
Я великий шанувальник Python для аналізу даних, але навіть мені цікаво, що ще доступно. R довгий час був основною мовою для статистики, але «Tidyverse» серйозно змінив цю мову. Ось чому я вирішив вивчити обидві технології.
R популярний в наукових колах і промисловості

Якщо ви проходите курси статистики в коледжі, ви, ймовірно, вивчите мову R. Завдяки тому, що мова була створена статистиками, ця мова широко використовується в статистичній академії, а також академічними дослідниками в інших галузях, які займаються статистичним аналізом, наприклад, у соціальних науках. Якщо ви візьмете підручники зі статистичних даних, згадані пізніше, ви побачите, що більшість прикладів коду буде на R. R також використовується для аналізу в діловому світі.
Якщо ви читаєте журнали, хоча все частіше згадуються інші мови, такі як Python, більшість обговорюваного програмного забезпечення працюватиме під R. Триваюче домінування R демонструється в Журнал статистичного програмного забезпеченнянауковий журнал із відкритим доступом, що охоплює статистичне програмне забезпечення.
На R сильно вплинула попередня мова. S. S було створено в Bell Labs для реалізації ідеї легендарного статистика Джона Т’юкі щодо «дослідницького аналізу даних». Як і інше творіння Bell Labs, Unix, S було ліцензовано практично безкоштовно. R базувався на цьому за допомогою ліцензії з відкритим вихідним кодом, коли він з’явився в 90-х роках. Таким чином, відношення R до S схоже на зв’язок між Linux і оригінальним Unix.
Tidyverse базується на цій спадщині статистичних обчислень, щоб запропонувати деякі вдосконалені інструменти для побудови графіків і обробки даних. Цей набір бібліотек R дозволяє будувати графіки та маніпулювати даними. Tidyverse містить ggplot2 для побудови графіків, dplyr для обробки даних, tidyr для очищення даних, readr для читання прямокутних даних з електронних таблиць або баз даних, purrr для функціонального програмування, tibble для керування кадрами даних, stringr для роботи з рядками, forcats для роботи з категоріальними змінними та lubridate для роботи з даними часу та дати.
Чудова графіка з ggplot2
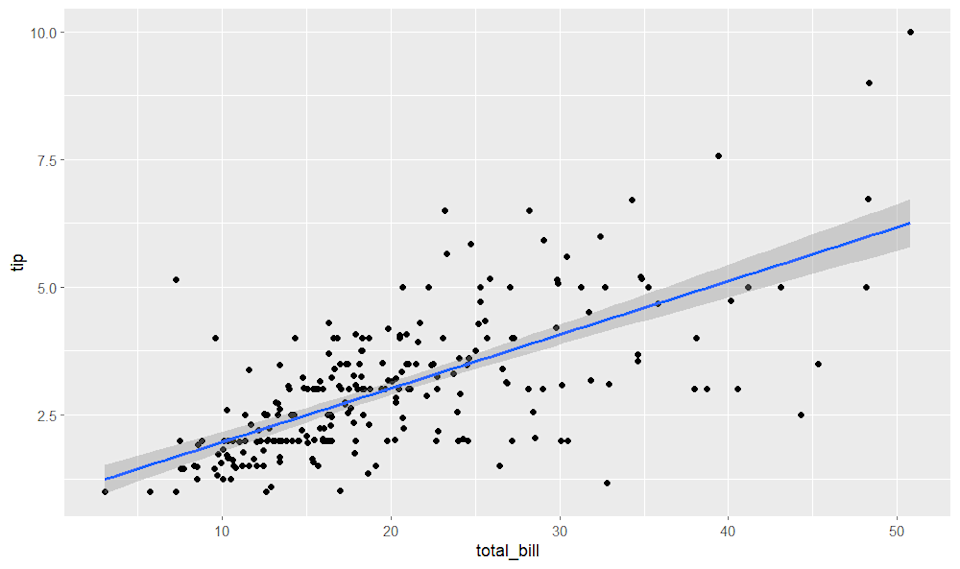
Однією з претензій на популярність R є його здатність створювати статистичні графіки професійної якості за допомогою мінімуму коду. ggplot2, як частина Tidyverse, може стати його «програмою-вбивцею», для якої ви хотіли б використовувати R і Tidyverse.
ggplot може дозволити вам створювати гарні сюжети, які ви можете публікувати. І професійні організації це роблять: BBC використовує це для своєї інфографіки.
ggplot2 базується на ідеї «граматики графіки». Замість спеціальної команди для чогось на кшталт створення діаграми розсіювання з лінією регресії, ви будуєте діаграму частина за частиною з вибраних елементів. Ви визначаєте «естетику», яка містить вісь кадру даних, наприклад осі x і y, а потім додаєте такі елементи, як діаграма розсіювання та регресія. Хоча цей підхід здається складнішим, ніж побудова графіків функцій, які можна знайти в програмі для роботи з електронними таблицями, він набагато гнучкіший.
Ось приклад використання бази даних порад, які записав офіціант під час роботи в ресторані:
ggplot(tips, aes(x = total_bill, y = tip)) + geom_point() + geom_smooth(method = "lm")
Цей код повідомляє ggplot2, що я хочу, щоб вісь x або незалежна змінна була загальною сумою рахунку, а вісь y – відповідною чайовою. Визначивши естетику, я наказую їй накласти діаграму розсіювання, а потім провести лінію лінійної регресії над нею.
Багато доступних текстів і посібників з R
Ще одна причина, чому я вирішив додати програмування на R до свого репертуару, полягає в тому, що через існуючу популярність R в академічних колах є багато матеріалу для вивчення більш складних концепцій.
Якщо ви візьмете більш просунуті підручники зі статистики, ви часто побачите, що в них є приклади коду, написані на R. Хоча було б досить легко перекласти ці приклади на Python за допомогою потрібних бібліотек, я б краще зосередився на вивченні концепцій, а потім спробував застосувати їх на Python пізніше, якщо захочу.
Є багато книг і навчальних посібників для різних рівнів кваліфікації. Для студентів, які проходять вступний курс статистики, OpenIntro Введення в сучасну статистику знайомить їх зі статистикою за допомогою R для лабораторних робіт, без необхідності шукати значення в таблицях чи запам’ятовувати формули.
Розділ наданої документації на веб-сайті CRAN, відповідь R на індекс пакетів Python або CPAN, містить багато доступних текстів. Один, на який я випадково натрапив Практична регресія та Anova з використанням R Джуліан Фаравей. Оскільки лінійна регресія є одним із моїх популярних методів у Python, це може бути великою підмогою у вивченні більш просунутих методів з R.
Багато пакетів у CRAN
Окрім Tidyverse, широка доступність пакетів для R є ще однією перевагою мови. У Comprehensive R Archive Network або CRAN міститься майже 23 000 пакетів. Це показує, наскільки статистики лояльні до R. Пакети Tidyverse є серед них, але також існують «перегляди завдань» для всього, від економетрики до спортивної аналітики.
У CRAN є чимало, щоб ботаніки займалися статистикою протягом десятиліть.
Tidyverse полегшує очищення даних
Якщо ви коли-небудь завантажували набори даних з Інтернету, ви знаєте, що вони можуть бути не ідеальними. Tidyverse отримав свою назву від ідеї, що кожен стовпець у фреймі даних має бути змінною, кожен рядок має представляти спостереження, а окрема клітинка представляє значення.
Проблема полягає в тому, що коли люди створюють власні набори даних в електронних таблицях, вони можуть не думати про цей критерій. Хоча найкраще розміщувати дані таким чином із самого початку, коли це можливо, багато електронних таблиць використовуються людьми, які не навчені статистиці та не думають заздалегідь, як їхні дані можуть бути використані в майбутньому.
Tidyverse розробив бібліотеки, які можуть змінювати набори даних відповідно до охайної моделі даних. Ви можете розгорнути дані до «широкого» формату з кількома стовпцями, а також ви можете стиснути їх у довший формат, який більше підходить для побудови.
RStudio чудовий
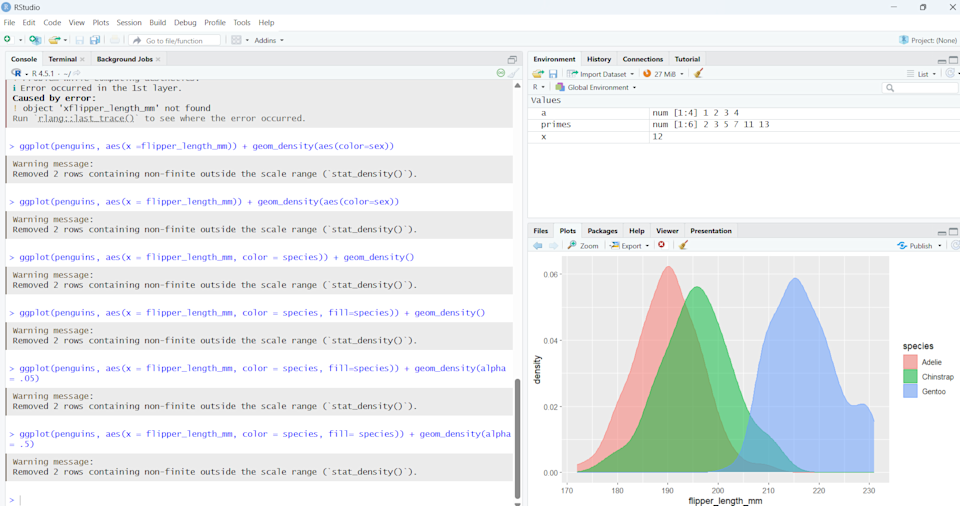
Раніше я загалом скептично ставився до IDE, вважаючи за краще працювати з окремими компонентами, такими як редактор і термінал, інтерпретатор або компілятор (але переважно інтерпретатор).
Основним інструментом розробки Tidyverse є RStudio, багатоплатформна IDE, спеціально розроблена для статистичної роботи. У назві вказано «R», але він також офіційно підтримує інші мови, такі як Python. Звертання до інших мов є також причиною того, що його розробник змінив назву з R Studio на Posit.
Наразі мені подобалося працювати з R Studio. Здається, це не заважає. Хоча я зазвичай скептично ставлюся до монолітних інструментів розробника, робота з аналізу даних може просто відрізнятися від інших завдань програмування. Це набагато інтерактивніше. З R ви витрачаєте більше часу на дослідження даних і пробування, а не на роботу над циклом редагування чи налагодження.
RStudio також має привабливий спосіб відображення графіків із ggplot2 на панелі в нижньому правому куті програми. З цього вікна також легко зберігати сюжети.
Іноді тиск однолітків — це добре
Початківцям програмістам часто радять вивчити Lisp, навіть якщо вони будуть використовувати інші мови у своїй повсякденній роботі, тому що знання цього вплине на те, як вони підходять до проблем, коли кодуватимуть на інших мовах. Я думаю, що R може відігравати подібну роль в аналізі даних. Python кращий, коли вам потрібно адаптувати ваші моделі для взаємодії з іншими програмами або працювати з реальним світом, але R, розроблений статистиками для статистиків, має сильний вплив на інші інструменти аналізу даних.
pandas DataFrames у Python явно зазнали впливу фреймів даних R.
Зрештою, бути прив’язаним до однієї мови – погана ідея. Незважаючи на популярність Python, я думаю, що знання кількох мов аналізу даних допоможе мені в довгостроковій перспективі.