
AWS нещодавно оголосила про загальну доступність автоматичної оптимізації для векторної системи Amazon OpenSearch Service. Ця функція спрощує оптимізацію векторного індексу шляхом автоматичної оцінки компромісів конфігурації щодо якості пошуку, швидкості та економії коштів. Потім ви можете запустити векторний конвеєр прийому, щоб створити оптимізований індекс у вашій колекції чи домені. Раніше для оптимізації конфігурацій індексів, зокрема алгоритму, стиснення та налаштувань механізму, потрібні були експерти та тижні тестування. Цей процес потрібно повторити, оскільки оптимізація є унікальною для конкретних характеристик даних і вимог. Тепер ви можете автоматично оптимізувати векторні бази даних менш ніж за годину без керування інфраструктурою та отримання досвіду налаштування індексів.
У цій публікації ми обговорюємо, як працює функція автоматичної оптимізації, її переваги та ділимося прикладами результатів автоматичної оптимізації.
Огляд векторного пошуку та векторних індексів
Векторний пошук — це техніка, яка покращує якість пошуку та є наріжним каменем генеративних програм ШІ. Це передбачає використання моделі штучного інтелекту для перетворення вмісту в числове кодування (вектори), що дозволяє зіставляти вміст за семантичною подібністю, а не лише за ключовими словами. Ви створюєте векторні бази даних, вводячи вектори в OpenSearch для створення індексів, які забезпечують пошук у мільярдах векторів за мілісекунди.
Переваги оптимізації векторних індексів і як це працює
Векторний механізм OpenSearch надає різноманітні конфігурації індексів, які допомагають вам досягти вигідних компромісів між якістю пошуку (відкликання), швидкістю (затримка) і вартістю (вимоги до оперативної пам’яті). Універсально оптимальної конфігурації не існує. Експерти повинні оцінити комбінації налаштувань індексу, таких як параметри алгоритму Hierarchal Navigable Small Worlds (HNSW) (наприклад, m або ef_construction), методи квантування (наприклад, скалярне, двійкове чи добуток) і параметри двигуна (наприклад, оптимізоване для пам’яті, диска або тепло-холодне зберігання). Різниця між конфігураціями може полягати в 10% або більше різниці в якості пошуку, сотнях мілісекунд у затримці пошуку або до трьох разів у економії коштів. Для великомасштабного розгортання оптимізація витрат може збільшити або порушити ваш бюджет.
Наступний малюнок є концептуальною ілюстрацією компромісів між конфігураціями індексів.
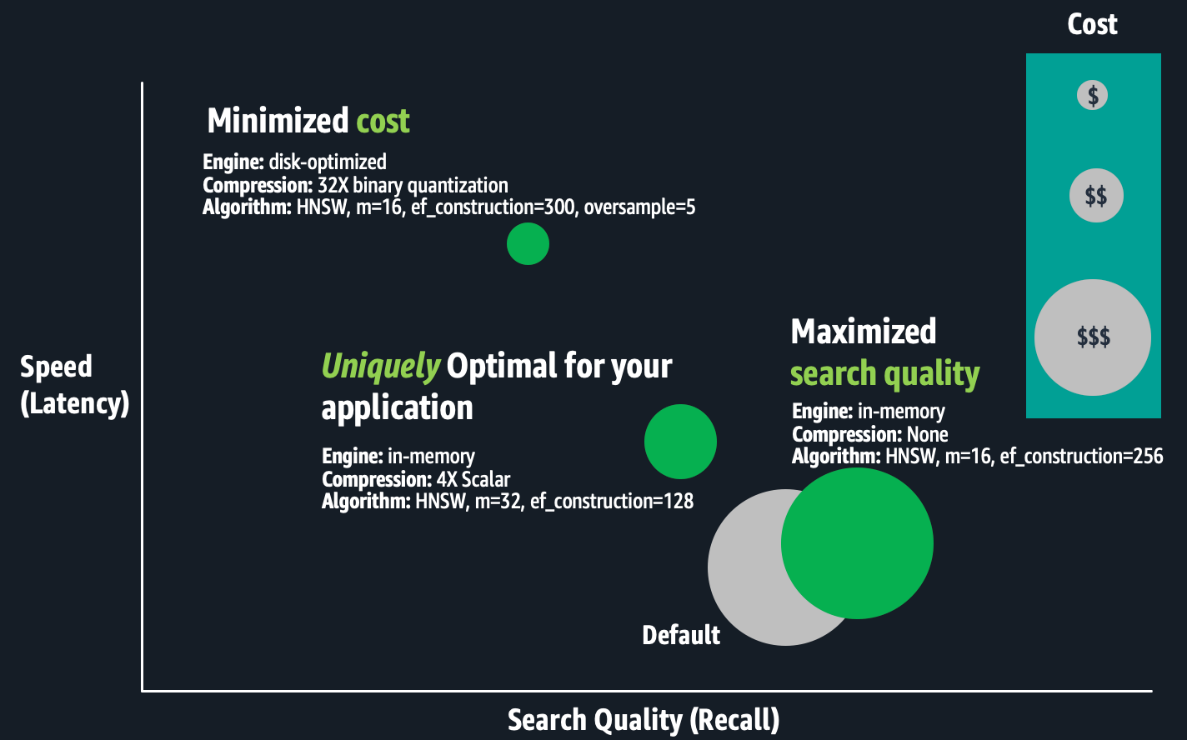
Оптимізація векторних індексів займає багато часу. Експерти повинні скласти індекс; оцінити його швидкість, якість і вартість; і внесіть відповідні налаштування конфігурації перед повторенням цього процесу. Проведення цих експериментів у масштабі може зайняти тижні, оскільки створення та оцінка великомасштабного індексу потребує значної обчислювальної потужності, що призводить до часу обробки лише для одного індексу від годин до днів. Оптимізація є унікальною для конкретних бізнес-вимог і кожного набору даних, а компромісні рішення є суб’єктивними. Найкращі компроміси залежать від варіанту використання, наприклад пошуку внутрішньої вікі або сайту електронної комерції. Тому цей процес потрібно повторити для кожного індексу. Нарешті, якщо дані вашої програми постійно змінюються, якість вашого векторного пошуку може погіршитися, що вимагатиме від вас регулярної перебудови та повторної оптимізації векторних індексів.
Огляд рішення
За допомогою автоматичної оптимізації ви можете запускати завдання для створення рекомендацій щодо оптимізації, які складаються зі звітів із детальними вимірюваннями продуктивності та поясненнями рекомендованих конфігурацій. Ви можете налаштувати завдання автоматичної оптимізації, просто вказавши прийнятну затримку пошуку та вимоги до якості для вашої програми. Досвід роботи з алгоритмами k-NN, методами квантування та налаштуваннями двигуна не потрібен. Це дозволяє уникнути універсальних обмежень рішень, заснованих на кількох попередньо налаштованих типах розгортання, пропонуючи індивідуальне пристосування для ваших робочих навантажень. Він автоматизує ручну працю, описану раніше. Ви просто запускаєте безсерверні завдання з автоматичною оптимізацією за фіксовану ставку за завдання. Ці завдання не споживають ресурси вашої колекції чи домену. Служба OpenSearch керує окремим багатокористувацьким теплим пулом серверів і розпаралелює оцінки індексів серед захищених працівників з одним клієнтом для швидкого отримання результатів. Автоматична оптимізація також інтегрована з векторними конвеєрами прийому, тож ви можете швидко створити оптимізований векторний індекс для колекції чи домену з джерела даних Amazon Simple Storage Service (Amazon S3).
На наступному знімку екрана показано, як налаштувати завдання автоматичної оптимізації на консолі OpenSearch Service.
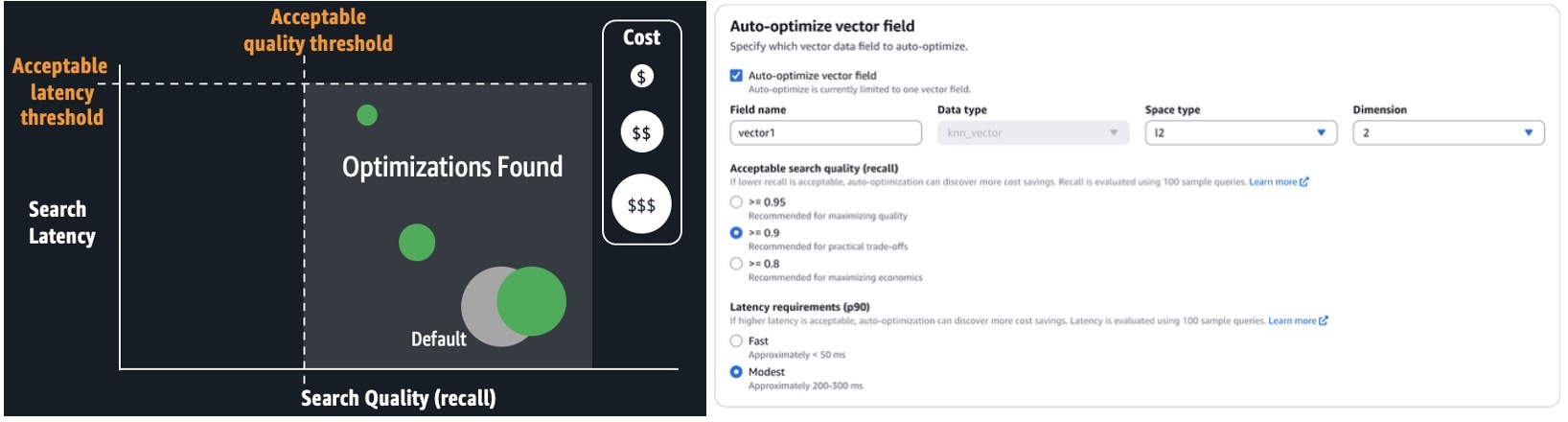
Коли завдання буде завершено (зазвичай протягом 30–60 хвилин для наборів даних понад мільйон), ви зможете переглянути рекомендації та звіти, як показано на наступному знімку екрана.
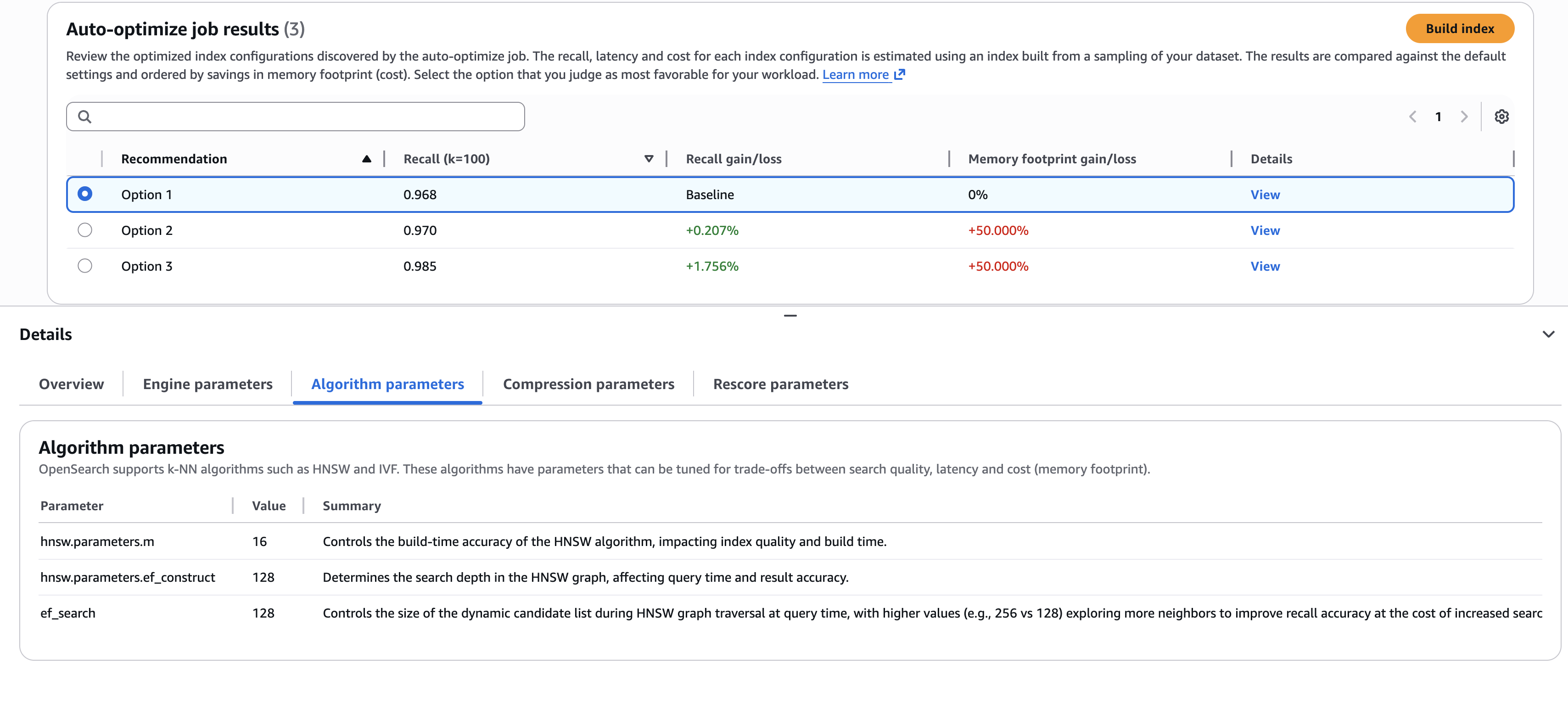
Знімок екрана ілюструє приклад, коли вам потрібно вибрати найкращі компроміси. Ви обираєте перший варіант, який забезпечує найбільшу економію (через менші вимоги до пам’яті)? Або ви обираєте третій варіант, який забезпечує покращення якості пошуку на 1,76%, але за більшу вартість? Якщо ви хочете зрозуміти подробиці конфігурацій, які використовуються для отримання цих результатів, ви можете переглянути підвкладки на Подробиці панелі, наприклад Параметри алгоритму вкладка, показана на попередньому знімку екрана.
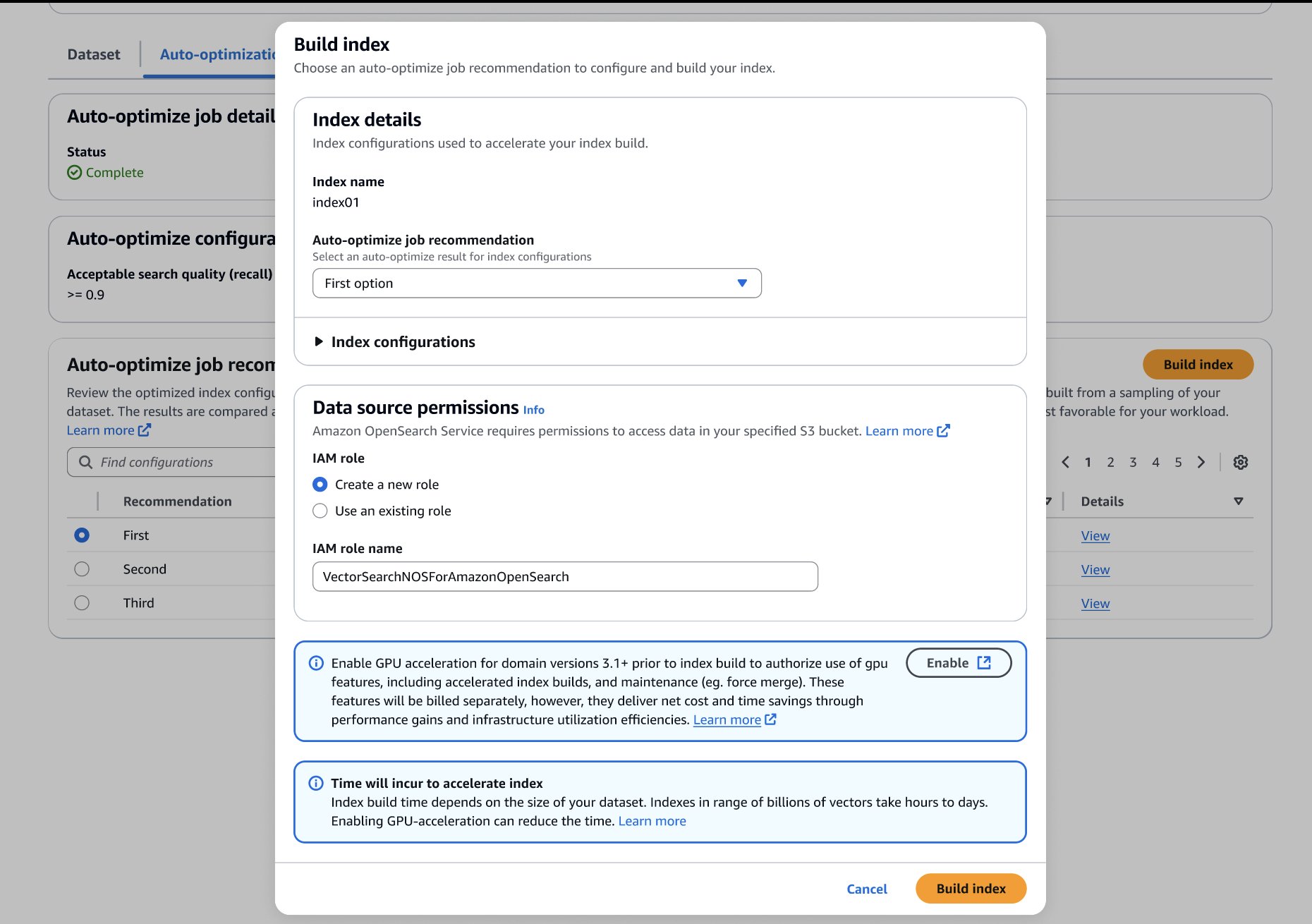
Зробивши свій вибір, ви можете створити оптимізований індекс у цільовому домені чи колекції OpenSearch Service, як показано на наступному знімку екрана. Якщо ви створюєте індекс для колекції чи домену, де працює OpenSearch 3.1+, ви можете ввімкнути прискорення GPU, щоб збільшити швидкість створення до 10 разів швидше за чверть вартості індексування.
Автоматична оптимізація результатів
У таблиці нижче наведено кілька прикладів результатів автоматичної оптимізації. Щоб кількісно визначити цінність запуску автоматичної оптимізації, ми представляємо переваги порівняно з налаштуваннями за замовчуванням. Приблизні вимоги до оперативної пам’яті базуються на оцінці стандартного розміру домену:
Необхідна оперативна пам’ять = 1,1 x (байт на розмір x розміри + hnsw.parameters.mx 8) x кількість векторів
Ми оцінюємо економію коштів, порівнюючи мінімальну інфраструктуру (має достатньо оперативної пам’яті) для розміщення індексу з параметрами за замовчуванням у порівнянні з оптимізованими налаштуваннями.
| Набір даних | Автоматична оптимізація конфігурацій завдань | Рекомендовані зміни до параметрів за замовчуванням |
Необхідна оперативна пам'ять) (% знижено) |
Орієнтовна економія коштів (Необхідні вузли даних для конфігурації за замовчуванням порівняно з оптимізованою) |
Відкликати (% приросту) |
| msmarco-distilbert-base-tas-b: 10 млн векторів 384D, згенерованих з MSMARCO v1 | Прийнятне відкликання >= 0,95 Невелика затримка (приблизно 200-300 мс) | Більше підтримки пам’яті для індексування та пошуку (ef_search=256, ef_constructon=128) Використовуйте оптимізований режим Lucene EngineDisk із 5-кратним збільшенням 4-кратного стиснення (4-бітне двійкове квантування) |
5,6 ГБ (-69,4%) |
менше 75% (3 x r8g.mediumsearch проти 3 x r8g.xlarge.search) |
0,995(+2,6%) |
| all-mpnet-base-v2: 1 млн векторів 768D, згенерованих з MSMARCO v2.1 | Прийнятне відкликання >= 0,95 Невелика затримка (приблизно 200–300 мс) | Більш щільний графік HNSW (m=32) Більше підтримки індексації та пам’яті для пошуку (ef_search=256, ef_constructon=128) Режим, оптимізований для диска, із 3-кратною передискретизацією, 8-кратним стисненням (4-бітне двійкове квантування) |
0,7 ГБ (-80,9%) |
Менше 50,7% (t3.small.search проти t3.medium.search) |
0,999 (+0,9%) |
| Cohere Embed V3: 113M векторів 1024D, згенерованих з MSMARCO v2.1 | Прийнятне відкликання >= 0,95 Швидка затримка (приблизно | Більш щільний графік HNSW (m=32)Більша підтримка пам’яті для індексування та пошуку (ef_search=256, ef_constructon=128)Використання стиснення Lucene engine4X (скалярне квантування uint8) |
159 ГБ (-69,7%) |
Менше 50,7% (6 x r8g.4xlarge.search проти 6 x r8g.8xlarge.search) |
0,997 (+8,4%) |
Висновок
Ви можете розпочати створення автоматично оптимізованих векторних баз даних на Вживання вектора сторінки консолі OpenSearch Service. Використовуйте цю функцію з прискореними GPU векторними індексами, щоб створити оптимізовані векторні бази даних у мільярдному масштабі за кілька годин.
Автоматична оптимізація доступна для векторних колекцій OpenSearch Service і доменів OpenSearch 2.17+ у регіонах AWS Схід США (Північна Вірджинія, Огайо), Захід США (Орегон), Азіатсько-Тихоокеанський регіон (Мумбаї, Сінгапур, Сідней, Токіо) та Європа (Франкфурт, Ірландія, Стокгольм).
Про авторів