Автор: Чарлі Сабгір
Рівень доходу, освіта та політичні переконання впливають на право власності на криптовалюту
Крипто приваблює молодих чоловіків.
Менше половини молодих чоловіків, які працюють повний робочий день, мають пенсійний рахунок. Фрілансер і робота на основі концертів додають проблеми.
Молоді американські чоловіки роблять великі ставки на криптовалюту. Традиційні пенсійні заощадження? Не дуже.
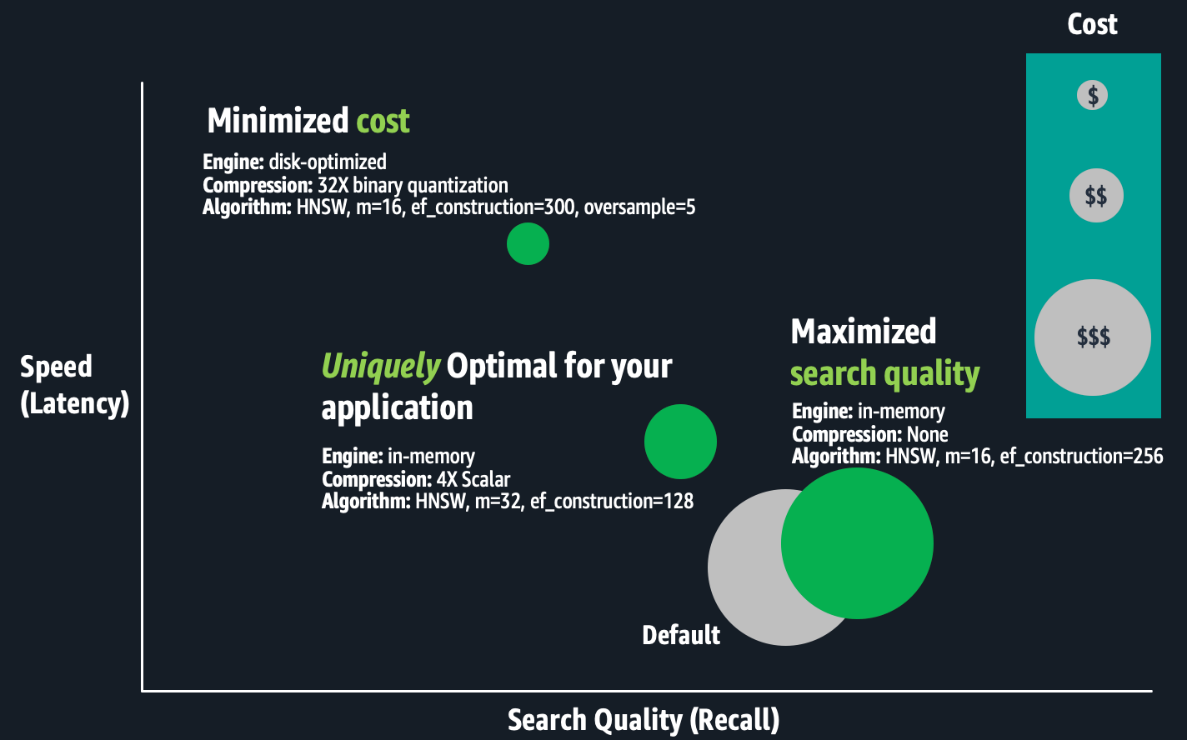
Нещодавнє опитування 1000 американських чоловіків 18-29 років від YouGov і Young Men Research Project (YMRP) – дослідницької організації, яка вивчає соціальні та політичні тенденції серед молодих американських чоловіків – показало, що 26% молодих чоловіків володіють криптовалютою, а 28% володіють будь-якими активами на основі криптовалюти, включаючи валюту, ETF на основі криптовалюти або обидва. Це більше, ніж 21% тих, хто має 401(k), Roth IRA або подібний пенсійний фонд. Для контексту, 24% молодих чоловіків володіють окремими акціями, тобто власниками криптовалюти.
Серед утримувачів криптовалюти біткойн (BTCUSD) є валютою вибору – 53% повідомили, що володіють нею, а 18% тримали ефір (ETHUSD) або Solana (SOLUSD). Менш ніж кожен п’ятий інвестував у «мемкойни», вартість яких може різко коливатися.
Чітка привабливість Crypto серед молодих чоловіків добре задокументована, але ці результати кидають виклик поширеним стереотипам. Типова карикатура – безрозсудні азартні гравці з низьким доходом, які женуться за швидкими грошима – не зовсім витримує.
Не пропустіть: падіння біткойна в листопаді не було випадковістю
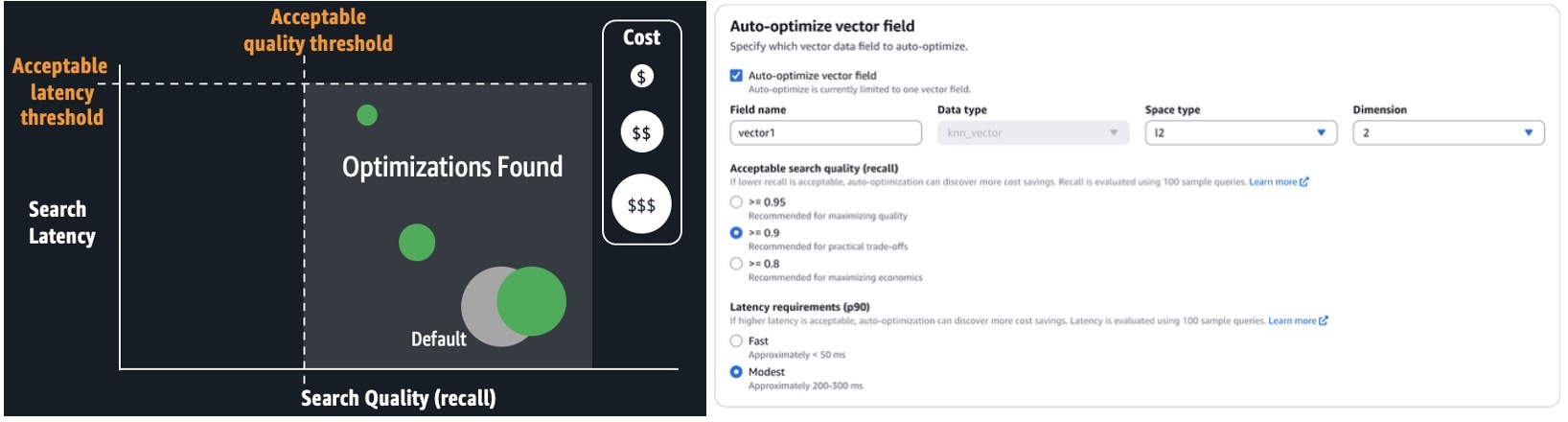
Більш високооплачувані молоді люди, швидше за все, володіють як криптовалютними, так і пенсійними рахунками. Серед тих, чий сімейний дохід становить 100 000 доларів або більше, 42% володіють криптовалютою, а 33% мають пенсійний фонд – приблизно вдвічі більше, ніж у тих, хто заробляє менше 60 000 доларів. Навчання розповідає схожу історію: 39% молодих чоловіків з вищою освітою володіють криптовалютою, порівняно з 23% їхніх однолітків без вищої освіти.
Серед тих, хто працює неповний робочий день, 27% володіють криптовалютою, тоді як лише 16% мають пенсійний рахунок.
Співробітники, які працюють повний робочий день – ті, хто має ширший доступ до спонсорованих роботодавцем планів – мають більш збалансовані портфоліо. Тридцять сім відсотків володіють криптовалютою, стільки ж мають пенсійні рахунки, а 34% володіють індивідуальними акціями. Однак серед тих, хто працює неповний робочий день, 27% володіють криптовалютою, а лише 16% мають пенсійний рахунок. Ця прогалина є попереджувальним знаком про зростаючу економіку концертів, де працівники обмінюють стабільні виплати працівникам на гнучкіші графіки.
Ніщо в результатах опитування не свідчить про те, що молоді люди уникають 401(k)s за власним бажанням. Майже половина американських працівників, які працюють повний робочий день, не мають доступу до будь-якого фінансованого роботодавцем пенсійного плану, а доступ ще більш обмежений для молодих працівників, які, швидше за все, будуть працювати неповний робочий день або працюватимуть нестабільно. Навіть якщо план доступний, план 401(k) накладає на людину більший ризик, ніж традиційні пенсії з визначеною виплатою. Серед такої фінансової невизначеності не дивно, що молоді чоловіки шукають альтернативні шляхи збагачення.
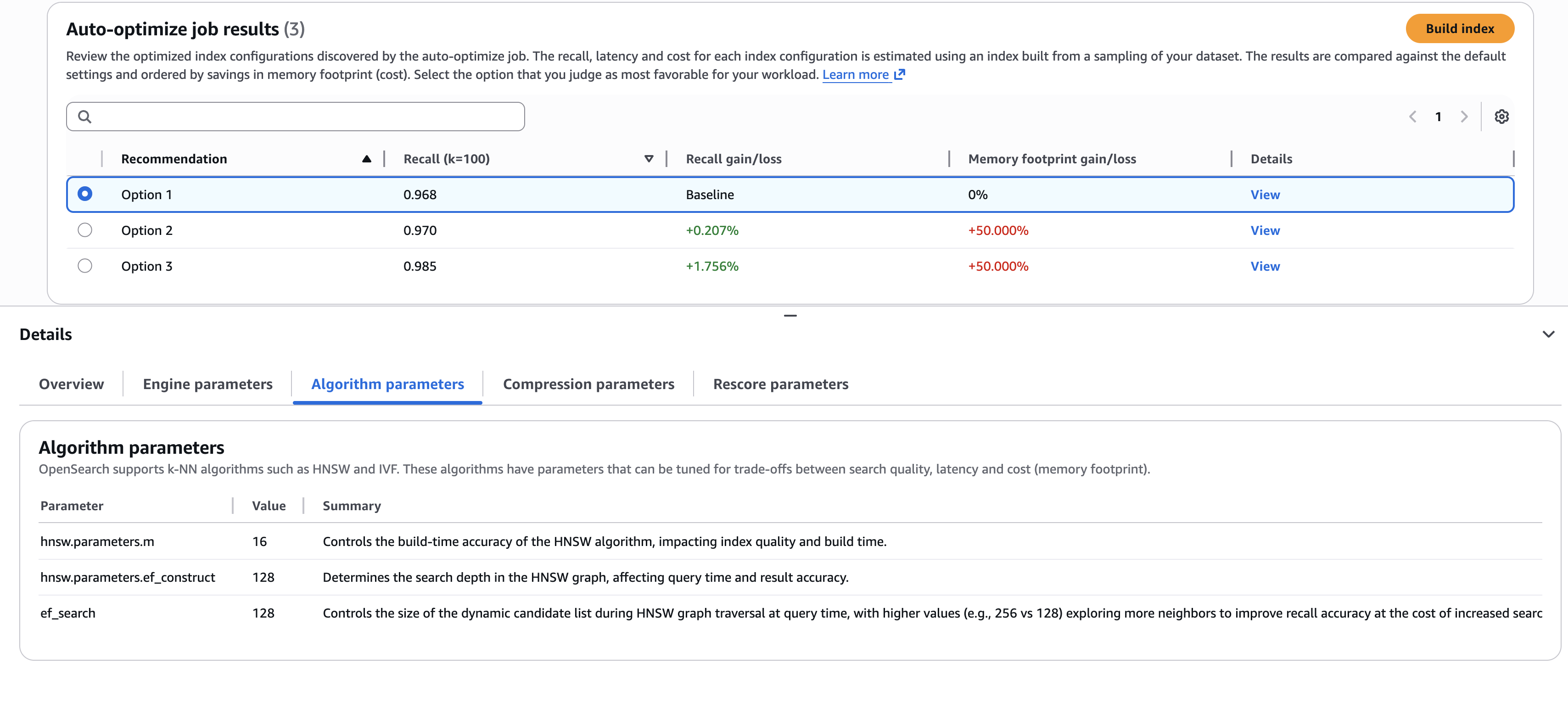
Результати збігаються з окремими висновками щодо політичних уподобань власників криптовалют. Дані YMRP показують, що молоді чоловіки, які голосували за президента Дональда Трампа у 2024 році, були відносно більш занурені в цифрові активи: 41% володіли криптовалютою, а 31% мали пенсійні рахунки. Серед тих, хто проголосував за кандидата від Демократичної партії Камалу Гарріс, сценарій змінився: 30% володіли криптовалютою, а 35% мали пенсійні рахунки. Прокриптовалютна позиція адміністрації Трампа, можливо, винагородила перших покупців, оскільки на початку цього року біткойн та інші основні криптовалюти різко зросли, але з тих пір основні криптовалюти впали.
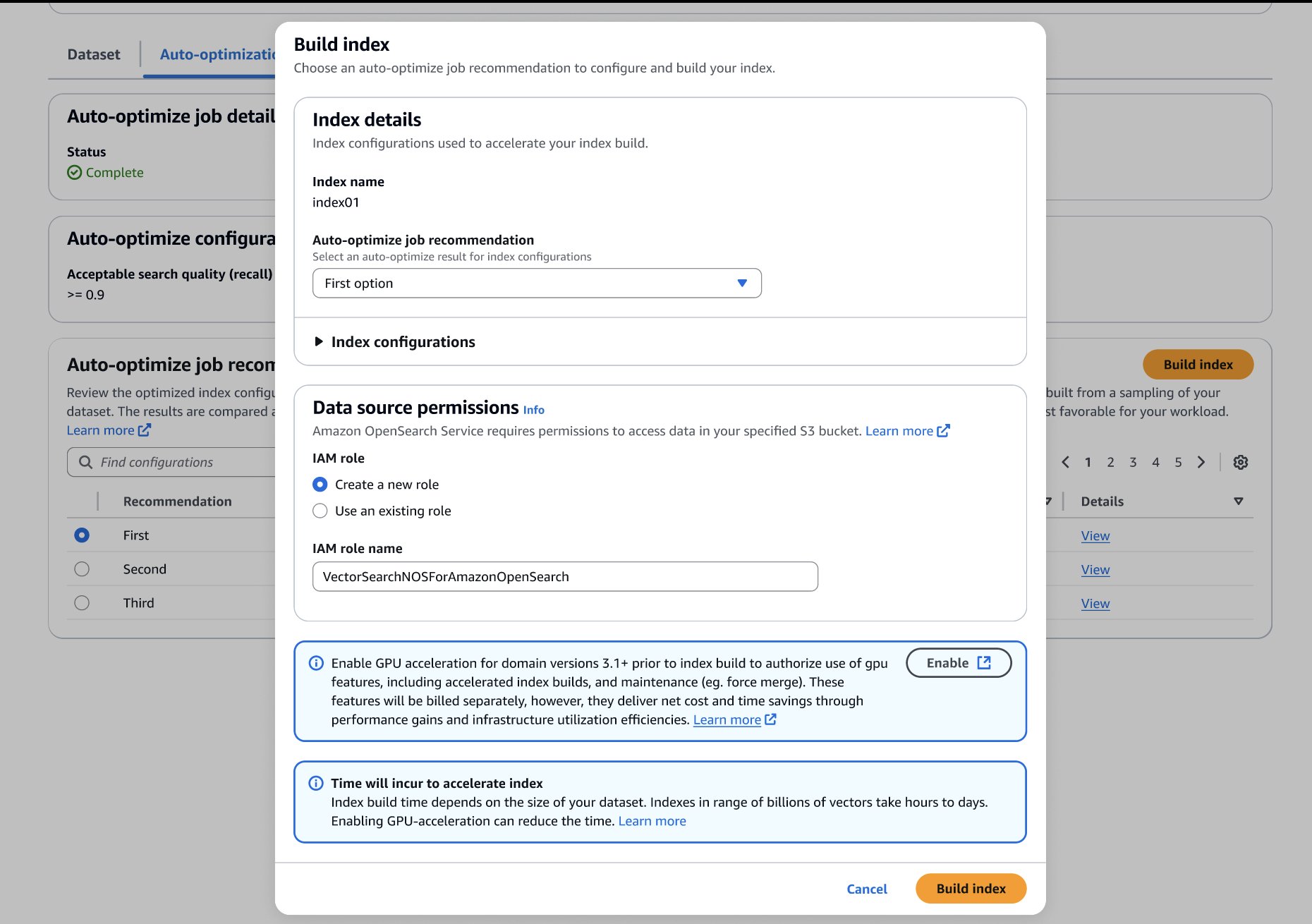
Окрім політики, володіння криптовалютою також відображає глибші соціальні погляди. Відповідно до того ж опитування, молоді чоловіки, які погоджувалися з твердженнями на кшталт «Фемінізм — це перевага жінок над чоловіками» або «Суспільство дивиться зверхньо на чоловіків, які є більш мужніми», частіше володіли цифровими активами, ніж ті, хто не погоджувався. Наприклад, 32% молодих чоловіків, які погодилися з твердженням «Чоловіки повинні приносити гроші, а жінки повинні піклуватися про дім і дітей», повідомили, що володіють криптовалютою, у порівнянні з 21% тих, хто не погодився.
YouTube, Reddit і Discord – соціальні медіа-платформи, де домінують чоловіки – регулярно рекламують інвестиційні стратегії на основі крипто.
Цифрові екосистеми молодих чоловіків допомагають пояснити цю привабливість. Впливові особи на YouTube, Reddit (RDDT) і Discord — платформах соціальних медіа, де домінують чоловіки — регулярно рекламують інвестиційні стратегії на основі криптотехнологій, часто під виглядом досвіду, а їхня молода чоловіча аудиторія обмінюється порадами та підказками. Наприклад, r/CryptoCurrency Reddit, одна з багатьох таких спільнот, має 10 мільйонів користувачів і близько 700 000 відвідувачів щотижня. Окреме дослідження виявило міцні зв’язки між «маносферою» – онлайн-спільнотами, які виступають проти прав жінок і часто пропагують традиціоналістські чоловічі ідеали – та залученістю криптовалюти.
Для багатьох молодих людей володіння криптовалютою відображає ширшу модель спекулятивної фінансової поведінки, а не стратегічного інвестування. Те саме опитування YMRP виявило, що молоді чоловіки, які володіють криптовалютами, грають в азартні ігри в Інтернеті майже втричі більше, ніж невласники – 20% проти 7% – і, швидше за все, тримають NFT, хоча загальна частка власності залишається низькою.
Ці цифри викликають тривогу. Менше половини американських молодих чоловіків, які працюють повний робочий день, мають пенсійний рахунок, і перехід до позаштатної роботи та роботи на концертах може залишити ще більше без нього. Крипто, тим часом, залишається мінливим класом активів без широкого регулювання – нестабільною заміною традиційного пенсійного забезпечення.
Для багатьох чоловіків покоління Z криптовалюта розглядається як спосіб досягти успіху в невблаганній економіці. Для інших це середній палець для встановлених інституцій. Зрозуміло лише те, що це молоде покоління вибирає дорогу, яка є менш прохідною – дорогою, вкритою значним ризиком.
Чарлі Сабгір є дослідницьким і стратегічним керівником проекту Young Men Research Project, який вивчає політичні та соціальні тенденції серед молодих чоловіків. Він також пише для Young Men Research Initiative Substack.
Детальніше: З дітьми не все гаразд – як молоді інвестори в акції створюють знижений ринок
Читайте також: Як створити ідеального інвестора: 50% покоління X і 50% покоління Z
-Чарлі Сабгір
Цей вміст створено компанією MarketWatch, якою керує Dow Jones & Co. MarketWatch публікується незалежно від Dow Jones Newswires і The Wall Street Journal.
(КІНЕЦЬ) Dow Jones Newswires
12-08-25 1631ET
Авторське право (c) 2025 Dow Jones & Company, Inc.