
Каталог даних AWS Glue тепер автоматизує створення статистики для нових таблиць. Ця статистика інтегрована з оптимізатором на основі витрат (CBO) від Amazon Redshift Spectrum і Amazon Athena, що забезпечує покращену продуктивність запитів і потенційну економію коштів.
Запити до великих наборів даних часто зчитують значні обсяги даних і виконують складні операції об’єднання кількох наборів даних. Коли система запитів, як-от Redshift Spectrum або Athena, обробляє запит, CBO використовує табличну статистику для його оптимізації. Наприклад, якщо CBO знає кількість окремих значень у стовпці таблиці, він може вибрати оптимальний порядок і стратегію об’єднання. Цю статистику потрібно збирати заздалегідь і постійно оновлювати, щоб відображати останній стан даних.
Раніше каталог даних підтримував збір статистичних даних таблиць, які використовуються CBO для Redshift Spectrum і Athena для таблиць у форматах Parquet, ORC, JSON, ION, CSV і XML. Ми представили цю функцію та її переваги продуктивності в Enhance query performance using AWS Glue Data Catalog статистика на рівні стовпців. Крім того, каталог даних також підтримує таблиці Apache Iceberg. Ми також детально розглянули це в розділі «Прискорення виконання запитів за допомогою статистики Apache Iceberg» у каталозі даних AWS Glue.
Раніше створення статистики для таблиць Iceberg у каталозі даних вимагало постійного моніторингу та оновлення конфігурацій для ваших таблиць. Вам потрібно було виконувати недиференційований підйом важких речей, щоб зробити наступне:
- Відкрийте для себе нові таблиці з певними форматами таблиць даних (такими як Parquet, JSON, CSV, XML, ORC, ION) і певними форматами таблиць транзакційних даних, такими як Iceberg, і їхніми окремими шляхами сегментів
- Визначення та налаштування обчислювальних завдань на основі стратегії сканування (відсоток вибірки та розклади)
- Налаштуйте ролі AWS Identity and Access Management (IAM) і AWS Lake Formation для конкретних завдань, щоб забезпечити певний доступ Amazon Simple Storage Service (Amazon S3), журнали Amazon CloudWatch, ключі AWS Key Management Service (AWS KMS) для шифрування CloudWatch і політики довіри
- Налаштуйте системи сповіщень про події, щоб зрозуміти зміни в озерах даних
- Налаштуйте конкретну продуктивність запитів на основі конфігурації оптимізатора та стратегії покращення зберігання
- Налаштуйте планувальник або створіть власні обчислювальні завдання на основі подій за допомогою налаштування та демонтажу
Тепер каталог даних дозволяє автоматично генерувати статистику для оновлених і створених таблиць із одноразовою конфігурацією каталогу. Ви можете почати, вибравши каталог за замовчуванням на консолі Lake Formation і ввімкнувши статистику таблиці на вкладці конфігурації оптимізації таблиці. Коли створюються нові таблиці, для таблиць Iceberg збирається кількість окремих значень (NDV), а для інших форматів файлів, таких як Parquet, збирається додаткова статистика, наприклад кількість нульових значень, максимальна, мінімальна та середня довжина. Redshift Spectrum і Athena можуть використовувати оновлену статистику для оптимізації запитів, використовуючи такі оптимізації, як оптимальний порядок об’єднання або агрегація на основі витрат. Консоль AWS Glue забезпечує видимість оновленої статистики та запусків генерації статистики.
Тепер адміністратори озера даних можуть налаштувати щотижневий збір статистики для всіх баз даних і таблиць у своєму каталозі. Коли автоматизацію ввімкнено, каталог даних щотижня генерує та оновлює статистику стовпців для всіх стовпців у таблицях. Це завдання аналізує 20% записів у таблицях для обчислення статистики. Цю статистику можуть використовувати Redshift Spectrum і Athena CBO для оптимізації запитів.
Крім того, ця нова функція забезпечує гнучкість налаштування параметрів автоматизації та запланованих конфігурацій збору на рівні таблиці. Індивідуальні власники даних можуть змінювати налаштування автоматизації на рівні каталогу на основі конкретних вимог. Власники даних можуть налаштувати параметри для окремих таблиць, зокрема, чи вмикати автоматизацію, частоту збору, цільові стовпці та відсоток вибірки. Ця гнучкість дозволяє адміністраторам підтримувати оптимізовану платформу в цілому, дозволяючи власникам даних точно налаштовувати статистику окремих таблиць.
У цій публікації ми обговорюємо, як каталог даних автоматизує збір статистичних даних таблиць і як ви можете використовувати його для підвищення ефективності вашої платформи даних.
Увімкнути збір статистики на рівні каталогу
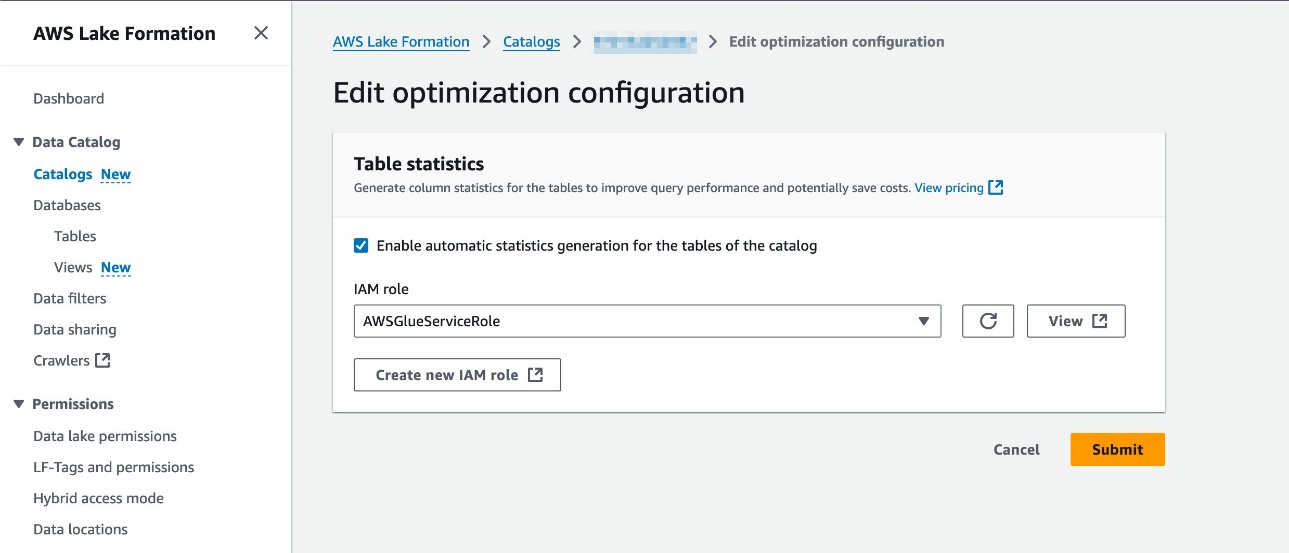
Адміністратор озера даних може ввімкнути збір статистики на рівні каталогу на консолі Lake Formation. Виконайте наступні дії:
- На консолі Lake Formation виберіть Каталоги на панелі навігації.
- Виберіть каталог, який потрібно налаштувати, і виберіть Редагувати на Дії меню.

- Виберіть Увімкнути автоматичне формування статистики для таблиць каталогу і виберіть роль IAM. Необхідні дозволи див. у розділі Передумови для створення статистики стовпця.
- Виберіть Надіслати.
Ви також можете ввімкнути збір статистики на рівні каталогу через інтерфейс командного рядка AWS (AWS CLI):
Команда викликає AWS Glue UpdateCatalog API, який приймає a CatalogProperties структура, яка передбачає наступні пари ключ-значення для статистики на рівні каталогу:
- СтовпецьStatistics.RoleArn – Роль IAM Amazon Resource Name (ARN), яка використовуватиметься для всіх завдань, ініційованих для статистики на рівні каталогу
- ColumnStatistics.Enabled – Логічне значення, яке вказує, увімкнено чи вимкнено параметри на рівні каталогу
Абоненти з UpdateCatalog повинен мати UpdateCatalog Дозволи IAM і бути наданими ALTER на CATALOG дозволи на кореневий каталог, якщо використовуються дозволи Lake Formation. Ви можете зателефонувати GetCatalog API для перевірки властивостей, установлених для властивостей вашого каталогу. Відомості про необхідні дозволи, які використовуються переданою роллю, див. у розділі Передумови для створення статистики стовпців.
Виконавши ці кроки, увімкнеться збір статистики на рівні каталогу. Потім AWS Glue автоматично оновлює статистику для всіх стовпців у кожній таблиці, щотижня вибираючи 20% записів. Це дозволяє адміністраторам озер даних ефективно керувати продуктивністю та економічною ефективністю платформи даних.
Перегляд автоматичних налаштувань на рівні таблиці
Коли ввімкнено збір статистики на рівні каталогу, коли таблицю Apache Hive або таблицю Iceberg створюється або оновлюється за допомогою AWS Glue CreateTable або UpdateTable API через консоль AWS Glue, AWS SDK або сканери AWS Glue, для цієї таблиці створюється еквівалентний параметр рівня таблиці.
Таблиці з увімкненою автоматичною генерацією статистики мають відповідати одній із таких властивостей:
- Формати таблиць HIVE, такі як Parquet, Avro, ORC, JSON, ION, CSV і XML
- Формат таблиці Apache Iceberg
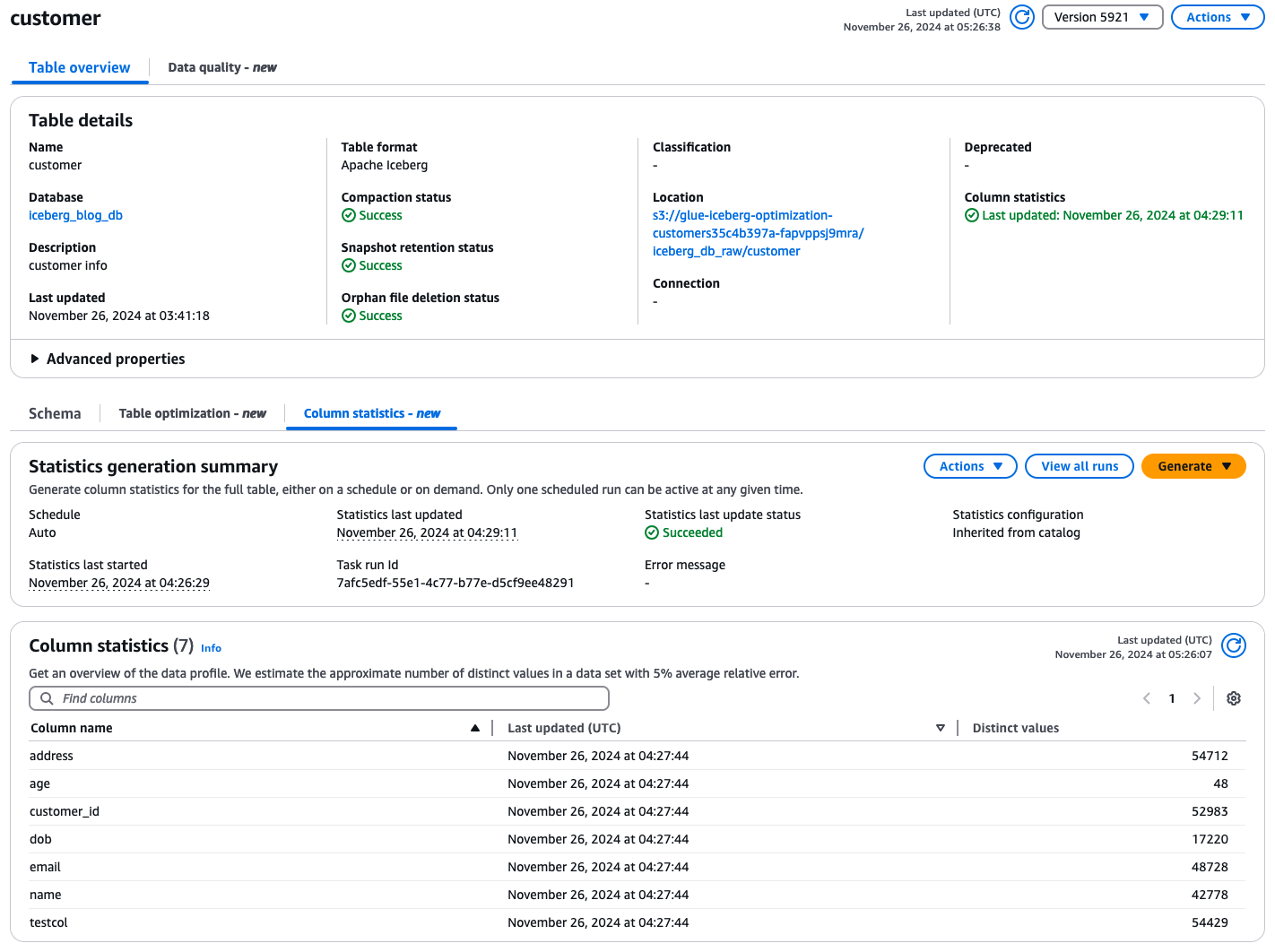
Після того, як таблицю було створено або оновлено, ви можете підтвердити, що налаштування збору статистики встановлено, перевіривши опис таблиці на консолі AWS Glue. Налаштування має мати розклад набір властивостей як Авто і Конфігурація статистики встановити як Успадковано з каталогу. Будь-яке налаштування таблиці з наведеними нижче налаштуваннями автоматично запускається внутрішньо AWS Glue.
Нижче наведено зображення Hive Table, де застосовано збір статистики на рівні каталогу та зібрано статистичні дані:

Нижче наведено зображення таблиці Iceberg, де застосовано збір статистики на рівні каталогу та зібрано статистичні дані:
Налаштувати збір статистики на рівні таблиці
Власники даних можуть налаштувати збір статистики на рівні таблиці відповідно до конкретних потреб. Для часто оновлюваних таблиць статистику можна оновлювати частіше, ніж щотижня. Ви також можете вказати цільові стовпці, щоб зосередитися на тих, які найчастіше запитуються.
Крім того, ви можете встановити, який відсоток записів таблиці використовувати під час обчислення статистики. Таким чином, ви можете збільшити цей відсоток для таблиць, які потребують більш точної статистики, або зменшити його для таблиць, де менша вибірка є достатньою для оптимізації витрат і продуктивності генерації статистики.
Ці параметри на рівні таблиці можуть замінити параметри на рівні каталогу, описані раніше.
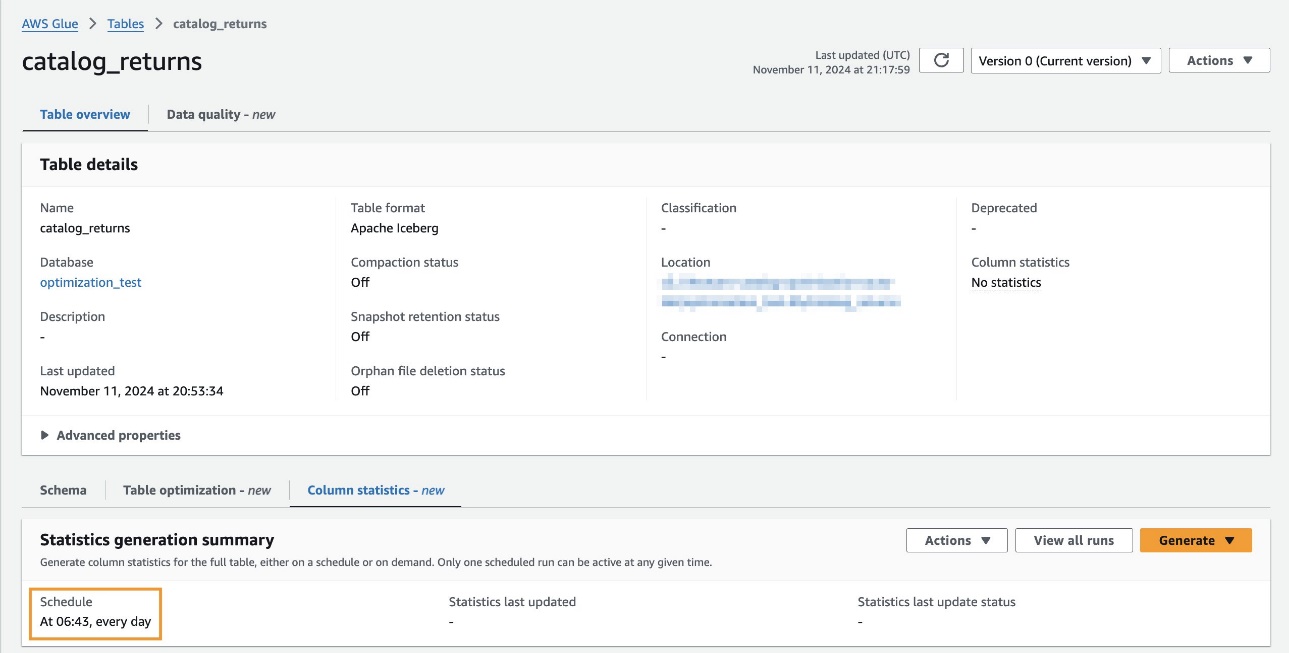
Щоб налаштувати збір статистики на рівні таблиці на консолі AWS Glue, виконайте такі дії:
- На консолі AWS Glue виберіть Бази даних під Каталог даних на панелі навігації.
- Виберіть базу даних, щоб переглянути всі доступні таблиці (наприклад,
optimization_test). - Виберіть таблицю, яку потрібно налаштувати (наприклад,
catalog_returns). - Перейти до Статистика колонок і вибирайте Генерувати за розкладом.
- в розклад виберіть частоту з щогодини, Щодня, Щотижня, Щомісяця і Custom (вираз cron). У цьому прикладі для Частотавибрати Щодня.
- для Час початкувведіть
06:43в UTC.

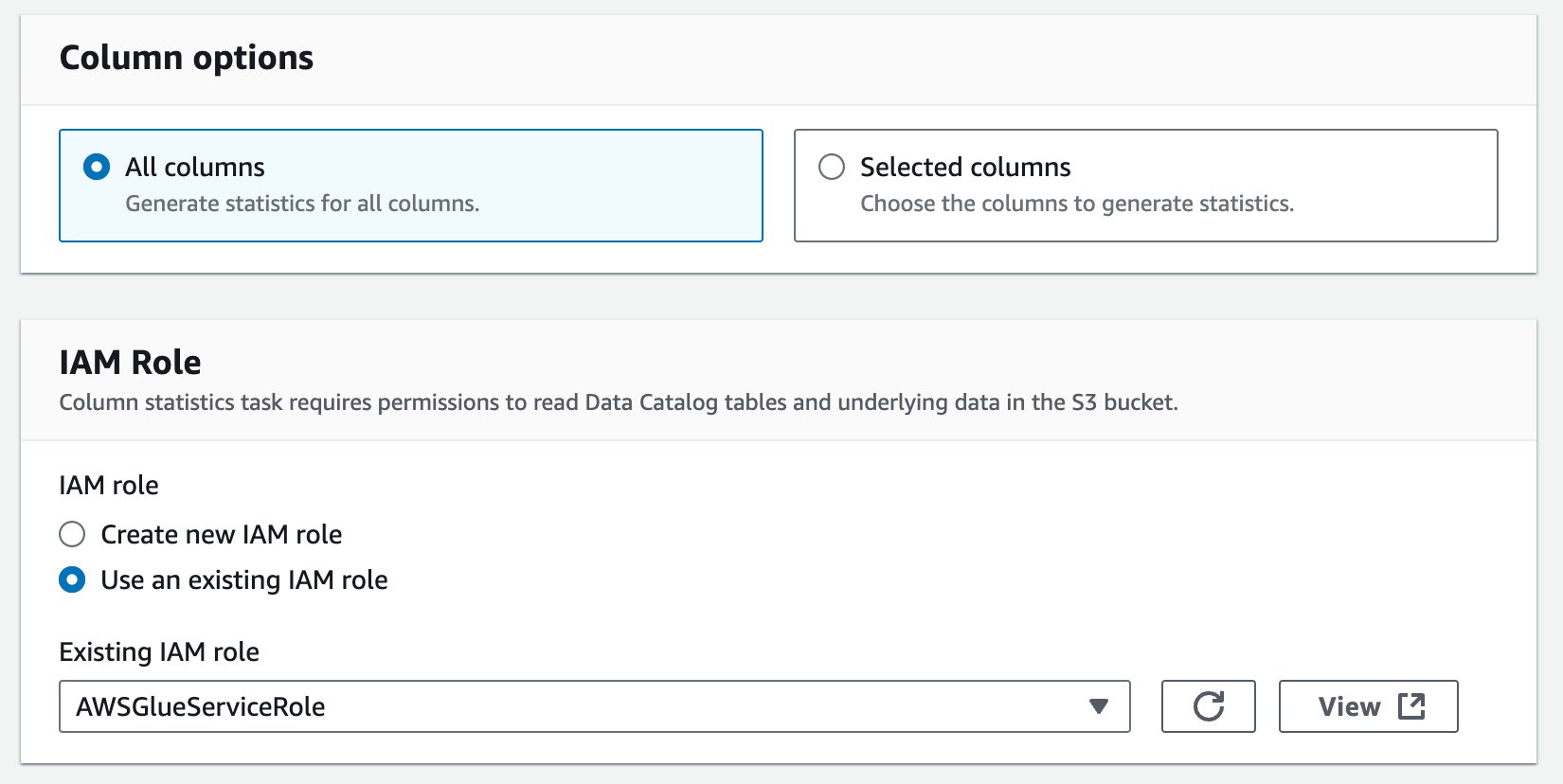
- для Варіанти колоноквиберіть Всі колонки.
- для роль IAMвиберіть наявну роль або створіть нову роль. Потрібні дозволи див. у розділі Передумови для створення статистики стовпців.
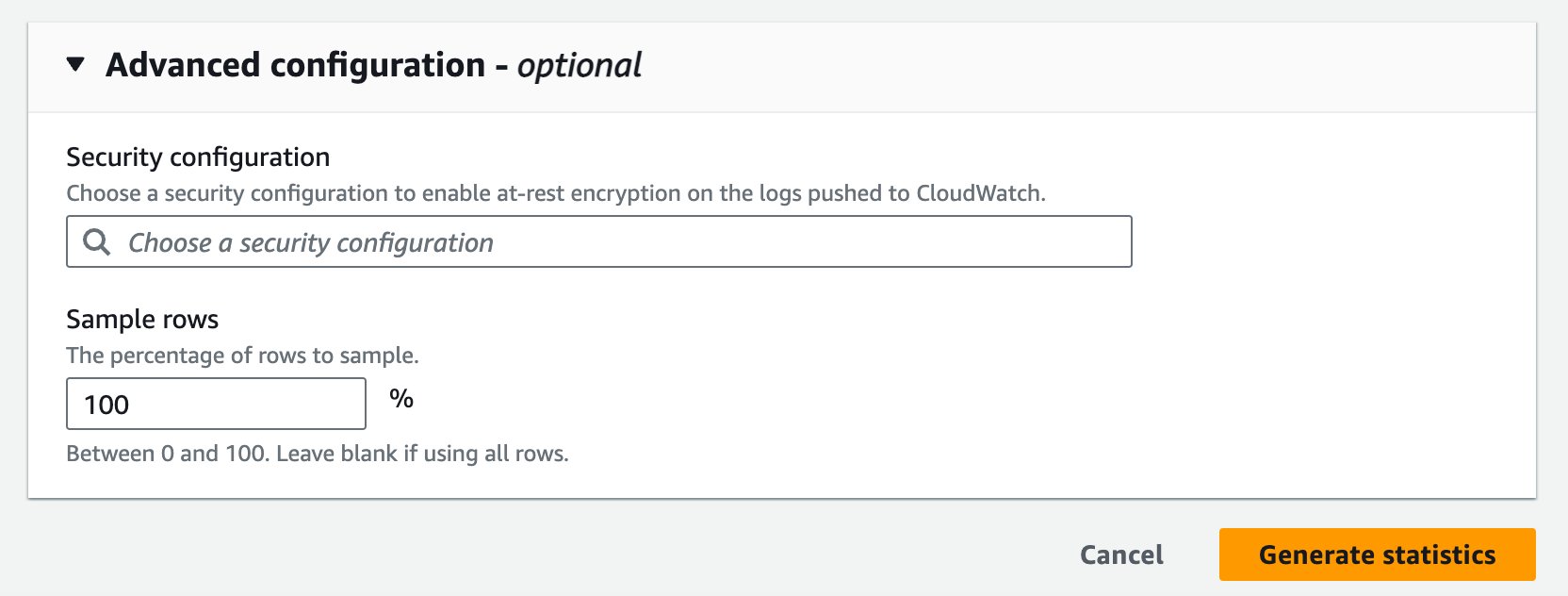
- Під Розширена конфігураціядля Конфігурація безпекиза бажанням виберіть конфігурацію безпеки, щоб увімкнути шифрування в стані спокою для журналів, які надсилаються до CloudWatch.
- для Зразкові рядивведіть
100як відсоток рядків для вибірки. - Виберіть Створення статистики.
В описі таблиці на консолі AWS Glue ви можете підтвердити, що завдання збору статистики заплановано на вказану дату та час.
Виконуючи ці дії, ви налаштували збір статистики на рівні таблиці. Це дозволяє власникам даних керувати статистичними даними таблиць відповідно до їхніх конкретних вимог. Поєднання цього з налаштуваннями на рівні каталогу адміністраторів озера даних дає змогу забезпечити базову лінію для оптимізації всієї платформи даних, одночасно гнучко задовольняючи вимоги до окремих таблиць.
Ви також можете створити розклад генерації статистики стовпців через AWS CLI:
Необхідні параметри є database-name, table-nameі role. Ви також можете включити додаткові параметри, такі як schedule, column-name-list, catalog-id, sample-sizeі security-configuration. Щоб отримати додаткові відомості, див. Створення статистики стовпців за розкладом.
Висновок
Ця публікація представила нову функцію в каталозі даних, яка дає змогу автоматизовано збирати статистичні дані на рівні каталогу за допомогою гнучких елементів керування для кожної таблиці. Організації можуть ефективно керувати та підтримувати актуальну статистику на рівні стовпців. Використовуючи цю статистику, CBO в Redshift Spectrum і Athena може оптимізувати обробку запитів і економічну ефективність.
Спробуйте цю функцію для власного випадку використання та повідомте нам свої відгуки в коментарях.
Про авторів
 Сотаро Хікіта є архітектором рішень Analytics. Він підтримує клієнтів у багатьох галузях у створенні та роботі з аналітичними платформами більш ефективно. Він особливо захоплений технологіями великих даних і програмним забезпеченням з відкритим кодом.
Сотаро Хікіта є архітектором рішень Analytics. Він підтримує клієнтів у багатьох галузях у створенні та роботі з аналітичними платформами більш ефективно. Він особливо захоплений технологіями великих даних і програмним забезпеченням з відкритим кодом.
 Норітака Секіяма є головним архітектором великих даних у команді AWS Glue. Він працює в Токіо, Японія. Він відповідає за створення артефактів програмного забезпечення для допомоги клієнтам. У вільний час любить кататися на шосейному велосипеді.
Норітака Секіяма є головним архітектором великих даних у команді AWS Glue. Він працює в Токіо, Японія. Він відповідає за створення артефактів програмного забезпечення для допомоги клієнтам. У вільний час любить кататися на шосейному велосипеді.
 Кайл Дуонг є старшим інженером з розробки програмного забезпечення в команді AWS Glue and AWS Lake Formation. Він захоплений створенням технологій великих даних і розподілених систем.
Кайл Дуонг є старшим інженером з розробки програмного забезпечення в команді AWS Glue and AWS Lake Formation. Він захоплений створенням технологій великих даних і розподілених систем.
 Сандіп Адванкар є старшим менеджером із продуктів в AWS. Перебуваючи в районі затоки Каліфорнії, він працює з клієнтами по всьому світу, щоб перетворити бізнес і технічні вимоги на продукти, які дозволяють клієнтам покращити спосіб керування, захисту та доступу до даних.
Сандіп Адванкар є старшим менеджером із продуктів в AWS. Перебуваючи в районі затоки Каліфорнії, він працює з клієнтами по всьому світу, щоб перетворити бізнес і технічні вимоги на продукти, які дозволяють клієнтам покращити спосіб керування, захисту та доступу до даних.
Залишити відповідь