Процес статистичного аналізу
Аналіз цього дослідження показаний на додаткових малюнках1. Після збору даних ми створили моделі машинного навчання та логістичної регресії відповідно для порівняння їх продуктивності. Стратегії побудови машинного навчання та традиційних моделей логістичної регресії різні. Розглянемо питання про розмір вибірки, коли ми створили машинне навчання, ми їх згрупували у співвідношенні 8: 2.
Учасники характерні
Всього в дослідженні було включено 211 учасника. Загальний стан, фізіологічні показники, психологічний стан, поведінка та спосіб життя учасників представлені в таблиці 1. Середній вік учасників, у тому числі 92 чоловіки (43,60%) та 119 жінок (56,40%), становив 66,04 ± 8,60 років. Серед цих 91 пацієнтів з остеопорозу 120 не мали остеопорозу.
Частота CNV у групах з остеопорозом та без нього відображається в таблиці 2. Всього було виявлено 219 CNV, пов'язаних з остеопорозом; 8 з них були виявлені в попередніх дослідженнях, а 211 було виявлено в офіційних експериментах. З них 134 екземпляри NSSV659422 були дублікатами, тоді як решта 77 екземплярів (або один, або три примірники) мали варіанти кількості копій.
Вибір фактора ризику
Всі показники аналізували за допомогою однофакторної логістичної регресії та багатофакторного логістичного аналізу, як показано в таблиці 3. Оскільки однофакторний аналіз у цьому дослідженні показав, що було менше факторів ризику, якщо лише статистично значущі фактори в однофакторному аналізі були включені як незалежні змінні в багатофакторному логістичному регресійному аналізі, важливі фактори ризику, ймовірно, будуть пропущені. Тому це дослідження має включити всі змінні для аналізу та значущих змінних на екрані. Були статистично значущі відмінності у віці, статі, ІМТ, частоті серцевих скорочень та споживання алкоголю згідно з однофакторним аналізом. Багатоваріантний аналіз показав, що секс, сіль з низьким вмістом дію, TG, історія інсульту та CNV NSSV659422 були суттєво різними (С
Розробка та перевірка номограми з моделлю логістичної регресії
Для вибору змінних, які врешті -решт були включені в модель, використовувались вперед і назад поетапні методи з мінімізацією AIC. У таблиці 4 відображаються результати багатоваріантного логістичного регресійного аналізу. Модель прогнозування включала вік, стать, глюкозу, статус гіперглікемії, холестральний, серцевий ритм, історію перелому, історію інсульту, CNV NSSV659422, сіль з низьким вмістом. Серед них модель прогнозування остеопорозу мала незалежні фактори ризику для старіння, статі, холестральної та низької солі. (С
Рівняння логістичної моделі:
Logit (p) =-5,819+0,048AGE+1,328 СЕКС+0,072GLUCOSE-0,173CHOLESTRAL+0,025 Серце-0,614CNV NSSV659422+0,767 ІСТОРІЯ 0,843 ІСТОРІА
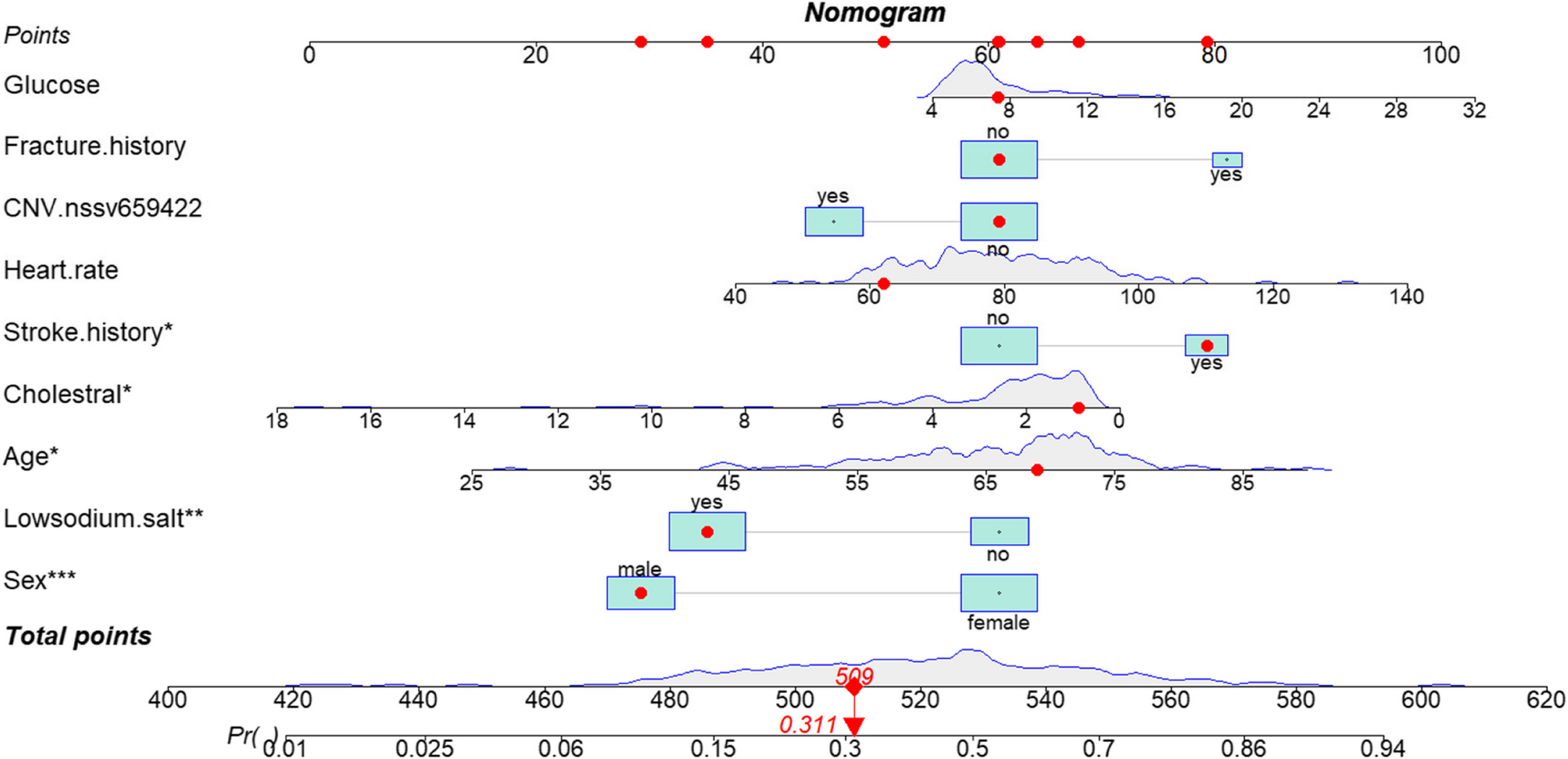
Для клінічного використання ми розробили модель номограми для прогнозування остеопорозу, як показано на рис. 1. Точки для ризику остеопорозу, глюкози, історії руйнування, CNV NSSV659422, частоти серцевих скорочень, історії інсульту, холестрального віку (років), сіллю з низьким вмістом спідня, статі та тотальними пунктами були організовані з-під протоку. У той же час ситуація першого об'єкта спостереження в наборі даних відображається на графіку та позначена червоними крапками, а його відповідні точки також позначені червоними крапками. Змінні глюкоза = 7,4, історія руйнування = ні, CNV NSSV659422 = Ні, частота серцевих скорочень = 62, історія інсульту = так, холестро = 0,89, вік = 69, низька сіль натрію = так, секс = чоловік. Після додавання відповідних точок загальні точки = 509, відповідна ймовірність становить 0,311.

Номограма логістичної регресійної моделі
Як показано на рис. 2, площа під AUC становить 0,751 (0,6859–0,8166.) Індекс Юдена становив 1,399, чутливість – 0,82, специфічність – 0,58, а значення обрізання кривої ROC – 0,363.
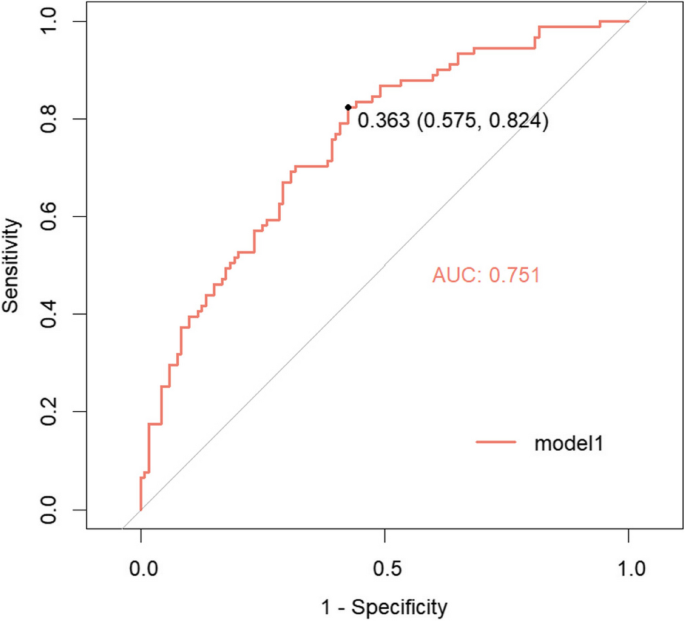
Крива ROC моделі логістичної регресії
Відповідна калібрування моделі була показана графіком калібрування, яка показала, що очікувана ймовірність та фактична ймовірність були однаковими (рис. 3). Оцінка Brier моделі становила 0,199, що менше 0,25. Результати показали, що модель мала хорошу ступінь калібрування та послідовність прогнозування.
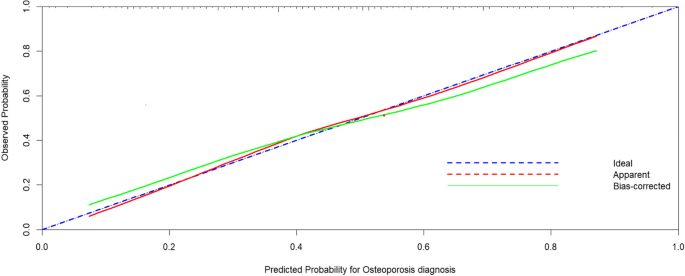
Калібрувальна графік моделі логістичної регресії. Примітки: Калібрувальна графік (відмінна калібрування, оскільки спостережувані результати близькі до лінії 45 °). Очевидна продуктивність = кінцева модель прогнозування на повних даних; Виконання продуктивності, скоригована на зміщенням = явна продуктивність мінус очікуваний оптимізм, оцінений із зразків завантаження
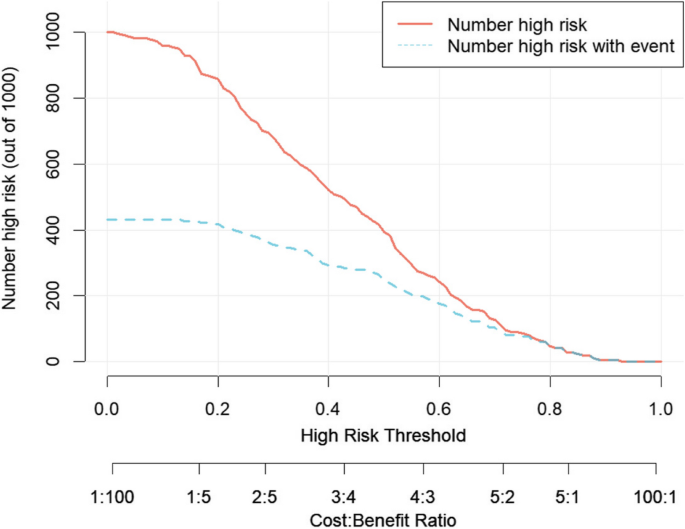
Старі дорослі можуть отримати хорошу чисту користь від моделі прогнозування, згідно з аналізом кривої рішення (DCA) [29]. Наприклад, слід зазначити, що логістична регресійна модель показує клінічну корисність у цілому діапазоні порогів ризику, коли поріг ймовірності прогнозування моделі номограми становить 0–0,75, особливо між 0,05 та 0,60, оскільки вона забезпечує більшу чисту користь порівняно з лікуванням усіх або ніхто з пацієнтів, що дозволяє припустити, що модель номограми має корисну клінічну застосовність (рис. 4).

Крива DCA моделі логістичної регресії
Аналіз кривої клінічного впливу (CIC) проводили, як показано на рис. 5, щоб оцінити клінічну застосовність номограми прогнозування ризику. Наприклад, при порізі ризику в осі X 0,4 кількість людей, що ризикують за допомогою моделі клінічного прогнозування, яку ми побудували, становить близько 520, а фактична кількість людей, що перебувають у ризику, становить близько 300, із співвідношенням втрат-вигоди 75%. Коли ймовірність порогу перевищує 65% від ймовірності оцінки прогнозування, модель прогнозування визначає, що група остеопорозу високого ризику сильно відповідає фактичній групі остеопорозу, яка підтверджує високу клінічну корисність моделі прогнозування. Комбінд DCA та CIC, коли поріг становить від 0,65–0,75, модель прогнозування не тільки має хороший Benifit, але й має ефективність.
Клінічна крива впливу моделі логістичної регресії
Для підтвердження моделі внутрішньо використовували переробку завантажувальної програми з AUC 0,75 (середнє значення 1000 зразків завантажувальної програми). Внутрішні результати перевірки показують, що модель прогнозування, застосована в цьому дослідженні, має хорошу надійність та послідовність. Результати переробки завантажувальної програми відображаються на рис. 6 та таблиці 5. Використовуючи 500 зразків завантажувальної програми протягом повного набору даних, очікуваний оптимізм моделі становив 0,014 для С-статистичного та 0,185 для нахилу калібрування. Очевидний С-статистичний для остеопорозу становив 0,751. С-статистичний, коригуючий оптимізм, становив 0,737, калібрувальний нахил-0,815, а калібрування в великій для всіх заходів продуктивності-
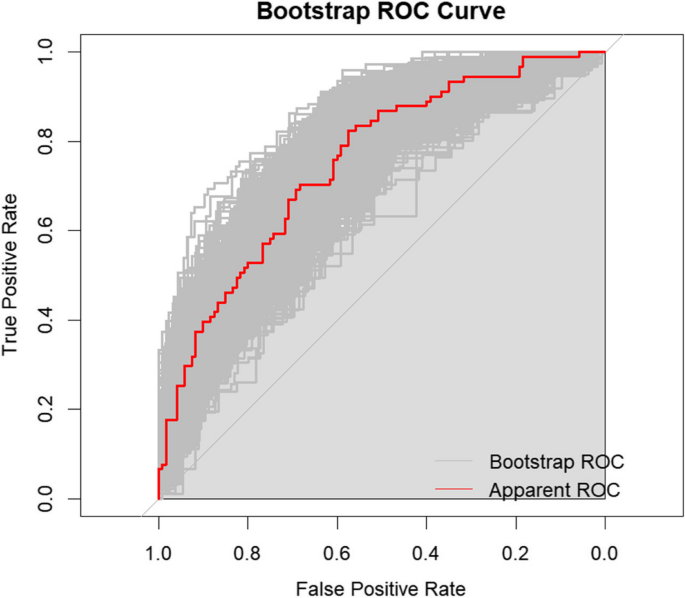
Крива ROC після внутрішньої перевірки за допомогою переробки завантаження (раз = 1000). ПРИМІТКА: Сірий відтінок показав середнє значення AUC зразків завантаження, червона лінія показала очевидну AUC
Виступи різних моделей
Таблиці 6 та 7, які представляють підсумок даних, що деталізують моделі, які використовуються для прогнозування остеопорозу, відображає конкретні результати різних моделей. Серед них модель SVM, виконана з найвищою точністю (0,754), а потім XGBoost (0,721), DT посіла найнижчу (0,651). Моделі логістичної регресії (LR) виявили найбільшу чутливість із значенням 0,751, а модель XGBoost показала найнижчу чутливість (0,588). Враховуючи, що точність та чутливість часто суперечать, ми обчислили показник F, показник оцінки, який зважив точність та чутливість. Топ -3 F бали моделі були DT (0,73), LR (0,69) та RF (0,63).
Серед цих статистичних даних є область під кривою (AUC), яка є загальною метрикою, яка використовується для оцінки ефективності діагностичної моделі. Він вимірює здатність моделі розрізняти особи з станом і без нього. AUC можна інтерпретувати як ймовірність того, що випадково вибраний позитивний випадок матиме більш високий прогнозований показник ймовірності, ніж випадково вибраний негативний випадок. AUC проілюстрував, що логістична регресія мала найкращі прогнозні показники, із значеннями AUC 0,751. Деталі наведені в таблиці 6. Загалом, найкраща модель була логістичною регресією, за якою слідують SVM та RF. AUC різних моделей машинного навчання були показані на додаткових малюнках3.
Додаткова фігура S2 показує графіки форми для чотирьох моделей машинного навчання. Хоча дев'ять найважливіших змінних з чотирьох моделей не зовсім однакові, деякі подібності можна знайти за допомогою логістичних регресійних моделей, статі, віку, глюкози, частоти серцевих скорочень та історії руйнування є важливими прогнозами. У моделі XGBoost є змінні ІМТ та DBP; У моделі RF є BMI, DBP, WHR, Питання змінних. У моделі підтримки Vector Machine є SBP, захворювання серця, змінні гіпертонічних захворювань. У моделі DT є змінні BMI, HDL-C, LDL-C, SBP. Ці важливі прогнози відрізняються від логістичних регресійних моделей. Більше того, у моделях векторних машин підтримки CNV NSSV659422 та низької солі натрію є важливими прогнозами. Сюжети форми показують, що нижчий рівень цих двох прогнозів (синіх крапок) був пов'язаний з меншою ймовірністю остеопорозу (значення форми
Поєднавши AUC та чутливість Для оцінки клінічної корисності BonePredict ми порівняли його ефективність з трьома широко використовуваними інструментами оцінки ризику остеопорозу: інструментом самооцінки остеопорозу (OSTA), інструментом оцінки ризику руйнування (FRAX) та кількісним ультразвуком (QUS). BonePredict продемонстрував чудову дискримінаційну здатність, досягнувши більш високої AUC у когорті розвитку порівняно з OSTA (AUC = 0,62), FRAX для основних остеопоротичних переломів (AUC = 0,71) та QUS (AUC = 0,68). Крім того, BonePredict демонстрував поліпшену калібрування та значно краще покращення чистої рекласифікації (NRI) та інтегроване поліпшення дискримінації (IDI) порівняно з цими існуючими інструментами.