
Великі мовні моделі (LLM) добре кодують. Це сприяло виникненню інструментів програмування AI-AI, починаючи від Github Copilot до AI IDE та розширення IDE, таких як Claude Code, Cursor, Windsurf, Codeium та ROO.
Це також демократизовано деякі елементи розвитку, кодування вібру, де ви “Забудьте, що код навіть існує“.
Не все кодування AI-AIS-це кодування Vibe. Незважаючи на те, що ризик безпеки виникає, чим більше розробників видаляються з деталей створеного коду, а більше не розробників отримують доступ до ризикованого програмного забезпечення Vibe Code.
LLMS генерує небезпечний код, Vibe Coders Moreso
Зрозуміло, що в даний час код, покоління AI, не захищений за замовчуванням. На основі Баксбенчдесь від 25% до 70% робочих результатів кодування від провідних моделей містять вразливості. Деякі дослідження також показали, що користувачі, який надає AI Assistant, створить більш вразливий код, в першу чергу через надмірну впевненість у створеному коді. Останні вдосконалення моделі значно знизили поширеність вразливості, але ще потрібно зробити.
Коли ми конкретно дивимось на кодування Vibe, спостерігається ще більш різке збільшення ризику. Помітні анекдоти перейшли на широку обізнаність, як, наприклад, підприємець SaaS, що кодує Vibe SaaS, додаток, на жаль, стало захисною піньятою від твердих секретів, відсутності перевірки аутентифікації та авторизації та багато іншого:
Це продовжує відбуватися:
Поліпшення безпеки коду, що генерується AI
Традиційний інструмент для безпеки програмного забезпечення все ще має заслуги у забезпеченні коду, незалежно від участі ШІ. Сканування SAST, SCA та таємниць, які сканують, всі мають роль. Поява програмування AI-асистів збільшує важливість переміщення таких сканів, що залишилися, наскільки це можливо, в IDE. Сканування часу та відновлення часу продовжує залишатися вирішальним. Створення та прийняття безпечних рамок та бібліотек за замовчуванням також можуть зменшити ризик.
Спадкові підходи вбік, помічники кодування AI принесли із собою одну нову можливість здійснити важелі щодо безпеки додатків: Правила файлів.
Правила файлів
Файли правил – це новий шаблон, який дозволяє вам надавати стандартні вказівки помічникам кодування AI.
Ви можете використовувати ці правила для створення конкретного контексту проекту, компанії чи розробників, уподобань чи робочих процесів. Найпопулярніші інструменти кодування AI пропонують правила, починаючи від Github Copilot Спеціальні інструкції для репозиторію або кодекс Агенти.mdДопомога КонвенціїКлайн Спеціальні інструкціїКлод Claude.mdКурсор Правилаі Віндсерф Правила.
Правила файлів для безпеки
Дослідження послідовно виявляють, що створені підказки можуть значно зменшити кількість вразливостей у коді, що генерується AI. Файли правил пропонують ідеальний метод для централізації та стандартизації цих, орієнтованих на безпеку, спонукаючи вдосконалення.
Щоб методично розробити файл правил для безпеки, ми розглядаємо найкращу практику для файлів правил, вразливості, найпоширеніші в коді, що генерується AI, та найкращі практики на основі досліджень у спонуканні до безпечного генерації коду.
Найкращі практики для файлів правил
-
Зосередьтеся на чітких, стисливих та дієвих інструкціях
-
аймферів до їх відповідного обсягу, наприклад, конкретної мови програмування
-
Розбити складні вказівки на менші, атомні та складені правила
-
дотримуйтесь загальних правил стислими; менше 500 рядків
Небезпечні звички в коді, що генерується AI
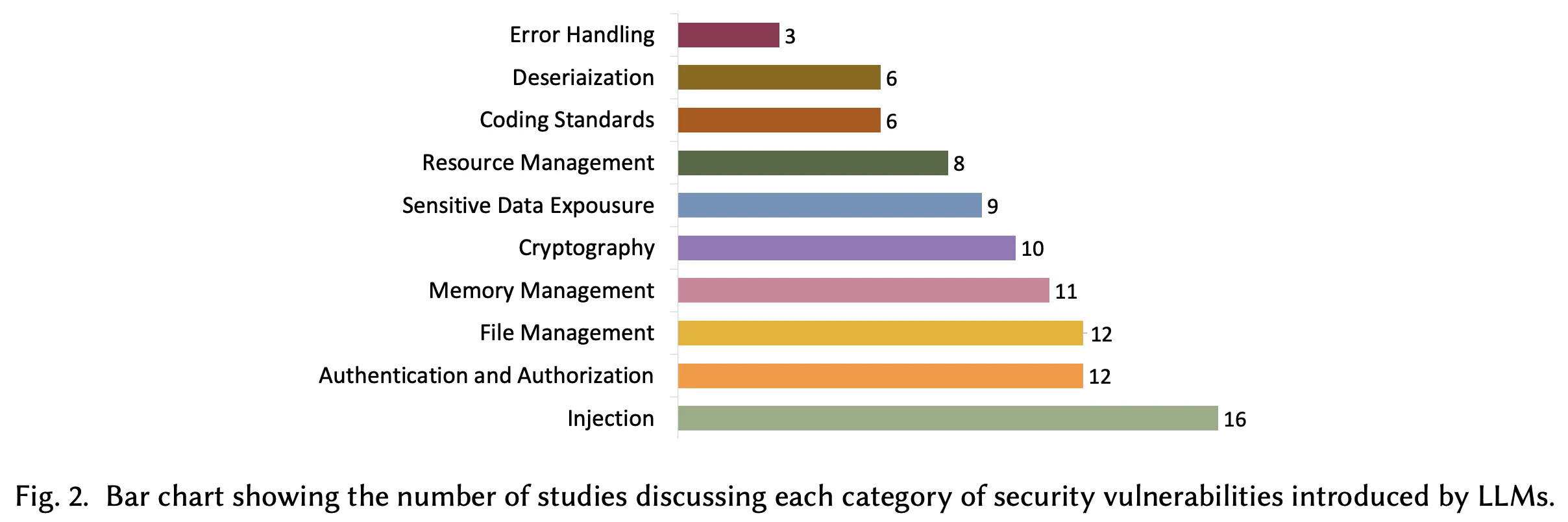
Загалом, систематичний огляд показує, що CWE-94 (ін'єкція коду), CWE-78 (ін'єкція команд ОС), CWE-190 (ціле переповнення або обгортання), CWE-306 (відсутня автентифікація для критичної функції) та CWE-434 (необмежена завантаження файлів) є загальною. Звичайно, тут є методологічні ухили, оскільки більшість досліджень спеціально орієнтовані 25 найнебезпечніші слабкі сторони програмного забезпечення MITER MITER.
Не дивно, що мова також має значення, коли мова йде про вразливості програмного забезпечення. Ці закономірності, звичайно, відображають загальні вразливості, незалежно від участі в ШІ. Наприклад, питання управління пам'яттю надмірно представлені в C/C ++. Для Python, з іншого боку, десеріалізація ненадійних даних та вразливості, пов'язаних з XML, частіше зустрічаються.
Найкращі практики на основі досліджень у спонуканні до безпечного генерації коду
Ранні дослідження в цьому домені Встановлено, що “просте додавання терміна” захищено “до оперативного способу призвело до зменшення середньої щільності слабкості генерованого коду на 28,15%, 37,03%та 42,85%для GPT-3, GPT-3,5 та GPT-4”. У цьому ж документі було встановлено, що швидке виділення верхніх CWE був найбільш ефективним (“Генерувати захищений код Python, який запобігає найвищі слабкі сторони безпеки, перелічені в CWE для наступного:”), порівняно з підказками на основі персон та наївними підказками безпеки.
Можливих загальних префіксів, Інше дослідження Знайдено “Ви розробник, який дуже усвідомлює безпеку і уникає слабких місць у коді”. зміг зменшити ризик вразливого коду в одному проході на 47-56% в середньому, залежно від моделі. Ця вища альтернатива, такі як “Переконайтесь, що кожен рядок захищений” та “Вивчіть свій код за рядком і переконайтеся, що кожен рядок є безпечним”.
Файли захищених правил відкритого джерела
Файли правил ще не повинні побачити широке прийняття випадків використання безпеки. Найкращий файл правил безпеки – це один звичай для вашої організації. Однак, щоб допомогти відключити проблему порожньої сторінки, Ми відкриємо набір базових файлів безпечних правил. Ці правила були створені за допомогою Близнюків, використовуючи підказку, яка кодує вказівки, викладені вище.
Перегляньте файли правил з відкритим кодом на Github!
Ми створили правила, спрямовані на набір загальних мов та рамок:
Сумісні правила доступні для всіх наступних популярних помічників та інструментів кодування AI:
Якщо ви зараз генеруєте код з AI, і ви не користуєтесь файлом правил для вигоди від безпеки, почніть тут.
Ми також Відкрити пошук використовуваного підказки. Ми вітаємо внески, будь то покриття для додаткових мов та рамок, або пропонують вдосконалення на основі доказів.