

Якщо гіперсальці – майстри будь -чого, він сприяє збільшенню масштабів та витрат на зниження, щоб новий тип інформаційних технологій може бути досить дешевим, щоб її можна було широко розгорнути.
Гіперсальці винайшли стільки нових технологій, які є синонімом другої та третьої хвилі комерційного Інтернету – і багато з них були винайдені спочатку в Google. Це означає, що Google був першим, хто досяг гіпершера, і спочатку все почало ламатися для Google.
Давайте відкладаємо декілька з них для розваги, а потім увійдемо в те, що Google розкрив про свій тиск на виходи та інновації AI на саміті AI Infra в Санта -Кларі минулого тижня.
Компанія винайшла стиль пошукової системи “Backrub”, який перетворив Інтернет, що зробило її фактично пошуковою системою протягом двох десятиліть. Потім з'явилася файлова система Google у 2003 році, а потім метод MapReduce прискорення та паралельна обробка, що стало відомим як “великі дані” у 2004 році. Створена база даних Bigtable NOSQL у 2006 році, реляційна база даних Dremel та Bigquery та наступник Colossus Global-масштабу до GFS у 2012 році. (TPU) для тренувань та висновку AI одночасно з вигадуванням та вдосконаленням моделі великої мови трансформатора, яка лежить в основі революції Генай.
У наші дні все подається в AI та AI, що подається у все, і Google перетворив BigQuery на основу своєї платформи даних, щоб обслуговувати дані його моделей Gemini та Gemma Transformer для внутрішнього використання, а також для послуг API для клієнтів Google Cloud. Ці моделі навчаються та доставляють висновок через флот Google TPU, який справді повинен бути величезним. Подивіться на діаграму, яку Марк Лохмейєр, генеральний менеджер AI та обчислювальна інфраструктура в Google, показав під час своєї основної доти на саміті AI Infra:
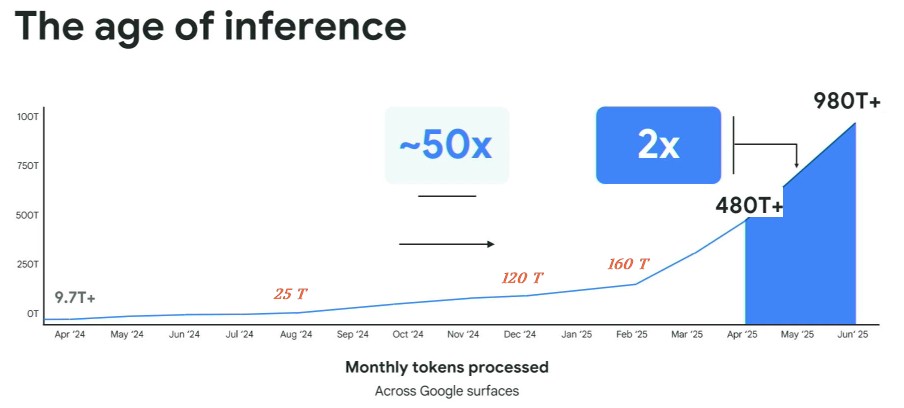
Ви можете побачити швидкість висновку у всіх продуктах Google, які компанія повинна обслуговувати, пройшла експоненціал. Ми поставили ставки виводів Google вище місяців, з якими вони пов'язані; Оригінальна діаграма мала їх компенсування ліворуч, що було добре для форматування, але погано для точності. Ми також додали в числах для точок даних, де швидкості виводу значно змінилися, показані червоними курсивом.
Ставка маркера висновку зігнулася в серпні 2024 року, коли він потрапив у нашу оцінку 25 трлн жетонів на місяць, а потім знову заграв у грудні 2024 року, коли він потрапив у 160 трлн жетонів на місяць. У лютому 2025 р. Швидкість маркерів по всій програмі Google почала зростати, вдаривши 160 трлн жетонів на місяць, а потім пішов ще крутішим у квітні 2025 року на понад 480 трлн жетонів в секунду. Швидкість маркера становила 9,7 трлн жетонів у квітні 2024 року і зросла на 49,5x по квітень 2025 року, що, ймовірно, ставить напругу на будь -яку бізнес -модель та інфраструктурний флот. Але знову ж таки, він подвоївся до 980 трильйонів жетонів на місяць до червня 2025 року, і якщо крива взагалі не згинається, вона зросла до 1160 трильйонів жетонів на місяць у серпні 2025 року. Наші здогадки прискорили трохи більше, і внутрішня ставка Google для своїх додатків була ближчою до 1,460 -трильйонних Tokens на місяць у серпні.
Важко здогадатися, скільки TPU може спричинити цю швидкість, враховуючи нашу відсутність знань про дані тексту чи відео чи зображення, які відповідають та генеруються, або моделі, що використовуються. На тесті MLPERF висновок про “трилій” TPU V6E створював близько 800 жетонів в секунду на моделі Llama 2 70B. Це працює приблизно до 2,07 мільярдів жетонів на місяць за ТПУ трилію. Якщо LLAMA 2 70B була єдиною моделлю, а висновок про обробку обробки даних MLPERF був єдиним навантаженням, що в серпні спрацювало б до флоту з 704,090 еквівалентів триллію, якщо наша дуже груба здогадка є правильною, і лише 4678 еквівалентів триллію для токену лише для позначення у квітні 2024. Нова машина “Ironwood” TPU V7P, яку ми детально розповів ще в квітні і яку ми порівняли з великими суперкомп'ютерами AI, які були встановлені і по всьому світу.

Лохмейєр не розголосив багато нових про системи Ironwood, але зробив кілька цікавих коментарів.
По -перше, крім підтримки рамки JAX AI, Native Pytorch тепер підтримується на TPU. Зараз дослідники Google AI віддають перевагу JAX над TensorFlow, який використовується для підтримки більшості виробничих навантажень у Google (тому ми чуємо). JAX – це рамка AI, яка працює на Python, і що Google, Nvidia та інші розвиваються разом.
Справа в тому, що Ironwood має 5 -кратну пікову продуктивність та 6 -кратну ємність пам'яті HBM систем трилієвих систем, які вона врешті -решт замінить. І що ще важливіше, кластер Ironwood, пов’язаний з абсолютно унікальним перемикачем оптичного кола (OCS) Google (OCS), може принести 9,216 TPU Ironwood з комбінованою 1,77 Pb потужності пам'яті HBM на тренувальних та умовах навантаження. Це робить систему NVIDIA Rackscale на основі 144 чіплетів GPU «Блеквелл» із сукупністю 20,7 ТБ пам'яті HBM схожим на жарт. (Але не той, з якого AMD або Intel можуть сміятися, тому що вони все ще застрягли у восьмисторонніх вузлах.) Це взаємозв'язок OCS, пояснив Лохмейєр, має динамічні можливості реконфігурації і може вилікуватись навколо невдач TPU, не перезапустивши цілі тренування та виходи. Цей останній біт величезний.
Так це рідке охолодження, про яке Лохмейєр трохи розмовляв у своїй основі:

“Google працює над рідким об'єднанням з 2014 року”, – пояснив Лохмейєр. “І зараз ми перебуваємо в нашому розповсюдженні розподілу охолодження п’ятого покоління, і ми плануємо розподілити цю специфікацію до проекту відкритого обчислення пізніше цього року. Щоб дати вам приблизне уявлення про масштаб тут, станом на 2024 року, ми мали близько Gigawatt від загальної рідини охолодженої ємності, яка була в 70 разів більше, ніж будь -який інший флот у той момент.
(Ми працюємо над глибоким зануренням у рідке охолодження для стелажів XPU. Слідкуйте за новими.)
На зображенні функції вгорі цієї історії показано системну дошку з чотирма TPU Ironwood, а на графіку Ironwood вище показано ряд із семи стелажів TPU Ironwood з однією ХДС на ряд та однією мережевою стійкою на рядок. Це перший раз, коли Google показав рядок машини Ironwood.
Ми трохи дивилися на це, і це нас турбувало.
Коли ми рахуємо, сім стелажів заліза з 16 системами на стійку, з чотирма TPU на систему, становить 448 TPU на ряд, а не 256, яких ми очікували. Кількість 256 ТПУ еквівалентна базовій стручці, який має 3D -взаємозв'язок, що пов'язує кожен ТПУ з усіма іншими в стручку. Ми знаємо, що повна система Ironwood, яку також з певною причиною називають струмком, має 144 стелажів із загальною кількістю 9 216 прискорювачів TPU V7E. Так що це означає, що ця повноцінна машина має 36 стручок, взаємопов'язаних у 4D-торусі.
Дуже дивно, що це не вісім налаштувань стійки TPU на ряд, що означало б два основні стручки на ряд. Ми вважаємо, що це означає, що на кожні два ряди є три стручки, з стійкою на рядок, що використовується як надмірний, гарячий запасний TPU. Це означало б, що повна фізичний Система Ironwood має 10 752 пристроїв TPU V7E на 168 стелажах через 24 ряди, з 1536 TPU SPRATES. Зроби, звичайно, можуть бути переплетені по всій семи стелажам у кожному з 24 рядів, і ми рішуче підозрюємо, що це так.
Google може використовувати TPU для більшості своїх внутрішніх навантажень, але, як хмарний будівельник, він також повинен мати великі флоти систем, прискорених GPU, і особливо тих, що базуються на GPU NVIDIA, які є галузевим стандартом. І це так, і Лохмейєр обов'язково вказав на це. Насправді Google закликає гібридний підхід до обчислення, мереж та зберігання, втіленого в Google Cloud “гіперкомп'ютеру AI”, і вказав, що Google Cloud має обчислювальні екземпляри на основі вузлів Blackwell RTX 6000 Pro (G4), а також восьмисторонні вузли B200 (A4) та 72-х-шлях B200 Rackscale Nodes (A4X). GB300 NVL72 – це дійсно спрямований на зниження вартості висновку, і це не було в списку екземплярів Google Cloud. Lohmeyer також зазначив, що додаток Dynamo Nvidia Dynamo – Nvidia називає його операційною системою, але ми не – це було додано як опція для користувальницького стеку умови у Google Cloud.
Ми наполегливо підозрюємо, що Google вважає за краще використовувати власний стек у висновку, про який Лохмейер пройшов усіх, але ми також не знаємо, чи працює стек умови Google на будь -якому, крім власних TPU. (Враховуючи свою історію перенесення речей до декількох архітектур, якщо цей стек Google не був перенесений як до NVIDIA, так і до GPU AMD, ми здивуємося. Це може бути незавершена робота.
Ось як це виглядає:
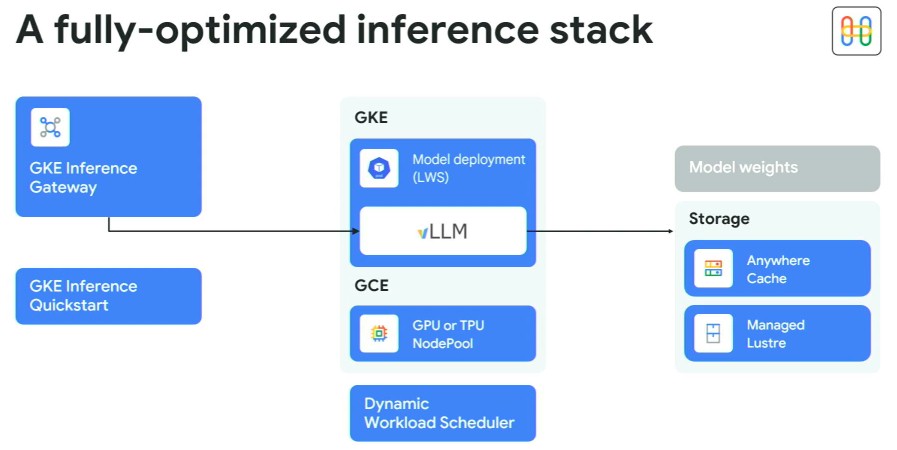
GKE – це керована контейнерна служба Kubernetes у Google Cloud і є аналогічною внутрішньо використовуваній контролера Borg та Omega. Vllm лежить в основі цього у висновку, як і з динамо.
Сервіс спрямований на спину з кешуванням під назвою Anywher Cache, що є новою службою кешування флеш-пам’яті, яка виступає як передній кінець різних служб зберігання Google. Лохмейєр каже, що в будь -якому місці кеш може збільшити затримки читання на 70 відсотків у регіоні Google Cloud та на 96 відсотків у кількох регіонах. (Він не сказав, що такі затримки, але ми підозрюємо, що вони отримують набагато довше, чим далі ви відсутні.) Кешування також може бути використане для зниження витрат на мережу, оскільки після кешування даних ви не переходите через мережу, щоб отримати дані. Служба керованої блиску – це файлова система високої продуктивності для подачі даних у кластерах GPU та TPU.
Шлюз для виводу GKE є новим і використовує балансування навантаження та маршрутизацію навантаження на AI, щоб розповсюдити запити у висновку по пулах обчислювальних двигунів. Ідея полягає в тому, щоб в першу чергу не дозволяти в черзі вгору, щоб використання можна було виняти вище.

Один із способів зробити це – це мати маршрутизатор, що сидить на передньому кінці пулу Xpus, і знайти пристрій, який вже має необхідний контекст, необхідний в його пам'яті. Як ми бачили в оголошенні NVIDIA минулого тижня прискорювача GPU “Rubin CPX”, який спрямований на обробку довгих контекстних запитів, шлюз Google порушує етап обробки “попередньої заповнення” з етапу запиту “декодування”, щоб вони могли бути зроблені на обчислювальних двигунах, оптимізованих для кожного завдання.
З'ясування, якими повинні бути ці конфігурації для різних частин апаратного забезпечення та стека програмного забезпечення, є непростим завданням, і тому Google створив інструмент GKE Infersect QuickStart, який також є новим і тепер загалом доступним:

Google бореться з усіма цими параметрами внутрішньо, і повністю усвідомлює, що рішення, прийняті достроковими, можуть бути неправильно прийняті з тяжкими наслідками для економіки висновку.
У сукупності Лохмейєр каже, що клієнти в Google Cloud можуть знизити затримку виступу на цілих 96 відсотків, знижувати пропускну здатність на 40 відсотків вище, і зменшити вартість жуючих, що жуються на 30 відсотків.
Lohmeyer також показав іншу технологію під назвою спекулятивне декодування, яку вона використовувала для підвищення продуктивності своєї моделі Близнюків та зниження споживання енергії приблизно на 33 рази:

За цими цінами всі ці відсотки є реальними грошима, і що 33 рази можуть бути абсолютно величезними, оскільки бюджет електроенергії обернено пропорційно прибутку в цій ракетці. Нам потрібно дізнатися більше про це.
