
У квітні 2025 року ми представили інструмент моделювання даних Amazon DynamoDB для сервера протоколу контексту моделі (MCP). Інструмент веде вас через розмову, збирає ваші вимоги та створює модель даних, яка включає таблиці, індекси та міркування щодо витрат. Він проходить всередині помічників з підтримкою MCP, таких як розробник Amazon Q, Kiro, Cursor та Windsurf.
Коли клієнти почали експериментувати з інструментом, ми зіткнулися з звичним викликом: як ви знаєте, чи добре, які він надає, є хорошим? Кожна взаємодія створює два артефакти: a dynamodb_requirements.md Файл і a dynamodb_data_model.md файл. Але перегляд цих результатів вручну було повільним, суб'єктивним та важким для масштабування. Завдяки декількох підказках, оновленні моделі та нових сценаріїв, тонкі регресії можуть легко проскочити.
Для вирішення цього ми вирішили створити систему оцінювання, яка могла б оцінити як процес (як зібрані вимоги), так і продукт (остаточна модель). Ми побудували рамки, що поєднують DSPY, агенти Strands та Amazon BedRock в повторювану петлю, яка дає нам вимірювані сигнали якості та дозволяє нам впевнено вдосконалюватися.
У цій публікації ми показуємо вам, як ми створили цю автоматизовану оцінку та як це допомогло нам надати надійні настанови щодо моделювання даних DynamoDB у масштабі.
Від суб'єктивного огляду до вимірюваних сигналів
Першим нашим кроком було визначити, що означає «добре» для розмови про моделювання даних. Недостатньо перевірити, чи з’являється ім'я таблиці, чи правильний ключ розділу. Ми дбаємо про те, чи вимоги доволіться повністю, розглядаються схеми доступу, а запропонована схема масштабована та економічно вигідна.
Щоб зрозуміти, для чого ми оптимізуємо, ми вручну переглянули 150 реальних розмов з тестування наших команд. Кожен огляд зайняв понад 45 хвилин і вимагав глибокого досвіду Dynamodb, щоб помітити ці нюансовані проблеми.
Цей ручний аналіз підтвердив, що нам потрібні критерії оцінювання, ніж базова перевірка синтаксису. Замість того, щоб просто перевірити таблицю має ключ розділу, нам потрібно було оцінити, чи є методологія розмови ретельною, а отримана схема насправді добре працюватиме у виробництві.
DSPY забезпечив правильний рівень абстракції. Замість того, щоб писати крихкі правила, ми писали програми суддів, які використовують модель фонду (FM) для оцінки результатів за багатовимірними критеріями. Наприклад, розмову оцінюється за збором вимог, методологією, технічними міркуваннями та документацією. Модель даних оцінюється на повноті, точності, масштабованій та витратах. Кожна категорія виробляє два бали: один для збору вимог (сеанс), один для моделі вихідних даних. Цей підхід перетворив якість на щось, що ми могли б виміряти, відстежувати та покращити з часом.
Чому FM роблять кращих суддів
Використання AI для оцінки AI може здатися круговим, але останні дослідження підтверджують цей підхід. Дослідження показують, що згода GPT-4 з оцінювачами людини досягає 85%, що вища, ніж домовленість людини до людини на рівні 81% (Zheng et al., 2023). Для моделювання даних DynamoDB це має значення, оскільки нам потрібно оцінити суб'єктивні якості, які традиційні показники не можуть захопити.
Перш ніж влаштуватися на ФМС як оцінювачі, ми розглянули кілька підходів, кожен з яких має значні обмеження:
- Огляд вручну вимагало понад 45 хвилин за сценарій і страждав від невідповідності рецензента – однакова схема може бути оцінена по -різному залежно від рівня експертизи рецензента або втоми.
- Перевірки на основі правил спіймали помилки синтаксису (“Чи має таблицю ключ розділу?”), Але пропущені проблеми з нюансованим дизайном, такі як ризики гарячих розділів або непотрібні витрати на GSI.
- Прості показники (кількість таблиці, покриття шаблону доступу) не дали розуміння фактичної якості дизайну.
FMS вирішує основну проблему оцінки цілісних, контекстуальних дизайнерських рішень, якими систем на основі правил не може впоратися. Вони можуть міркувати про суб'єктивні якості, такі як “Чи ця розмова ретельно збирає вимоги?“Або”Чи є технічні міркування для цього звучання GSI?“Хоча розуміння компромісів, притаманних моделюванні даних. На відміну від жорстких показників, LLMS розуміє, що дизайн з меншою кількістю GSI може бути оптимізовано, а не неповне, і вони визнають, як бізнес-контекст керує технічними рішеннями. Це контекстне розуміння робить їх унікальними для оцінки нюансових дизайнерських виборів, які визначають схеми динамодбів якості.
Звернення до обмежень
Нам відомо про обмеження суддів AI – непослідовність є реальною, оскільки той самий суддя може дати різні бали на повторних пробігів. Ми пом'якшуємо це за допомогою детальних критеріїв оцінки з конкретними прикладами у наших підказках DSPY, декількох запусків оцінювання для виявлення дисперсії та підказки судді, керованого версією до підтримки відтворюваних результатів. Неоднозначність критеріїв становить ще один ризик, оскільки різні судді з великою мовною модель (LLM) можуть по-різному інтерпретувати «повноту», тому ми побудували спеціальні програми суддів DSPY з специфічними підказками, а не покладаючись на загальні інструменти оцінювання. Визначаючи саме те, що означає «збори хороших вимог» у контексті динамодба, ми переконуємось, що наші оцінки є як послідовними, так і значущими для якості моделювання даних.
Найголовніше, що судді LLM дають нам пояснені рішення. Замість непрозорої оцінки ми отримуємо детальні міркування, наприклад: “Збір вимог набрав 9/10, оскільки розмова захопила всі суб'єкти та моделі доступу, але могла бути глибше на оцінках частоти запитів.“Це робить результати оцінювання, що підлягають вдосконаленню інструменту. Для домену, настільки нюансованого, як моделювання даних DynamoDB, FMS забезпечує контекстне розуміння того, що простіші підходи не можуть відповідати. Вони не ідеальні, але вони досить складні, щоб з упевненістю керувати розвитком.
Керування реалістичними розмовами з агентами Strands
Після того, як ми знали, що виміряти, нам потрібні були реалістичні входи. Ось де прийшли агенти Strands. З агентами «Странди» ми можемо скласти багаторазові розмови, які поводяться як справжній користувач, який взаємодіє з інструментом MCP. Кожен сценарій, наприклад, розробка простої схеми електронної комерції, працює в кінці, виробляючи вимоги та запропонована модель даних.
Моделюючи розмови, а не покладаючись на статичні підказки, ми отримуємо оцінки, які відображають, як насправді використовується інструмент. Агенти Strands також природно інтегруються з Amazon Bedrock, а це означає, що ми можемо експериментувати з різними моделями і швидко побачити, як виходи змінюються.
Складаючи все це разом
Результат – рамка, яка веде розмову, фіксує артефакти та оцінює їх автоматично. Простий бігун дозволяє вам вибрати сценарій та модель, виконати сеанс, а потім переглянути показники оцінювання.
Протягом декількох хвилин у вас є як артефакти, так і підсумок оцінювання. Замість того, щоб розчісуватися через стенограми, ви можете негайно побачити, чи є збори вимог завершено, чи правильно відображені схеми доступу та наскільки добре схема вирішує масштабованість та проблеми. На наступному скріншоті показано багатовимірний результат оцінки з оцінювача.
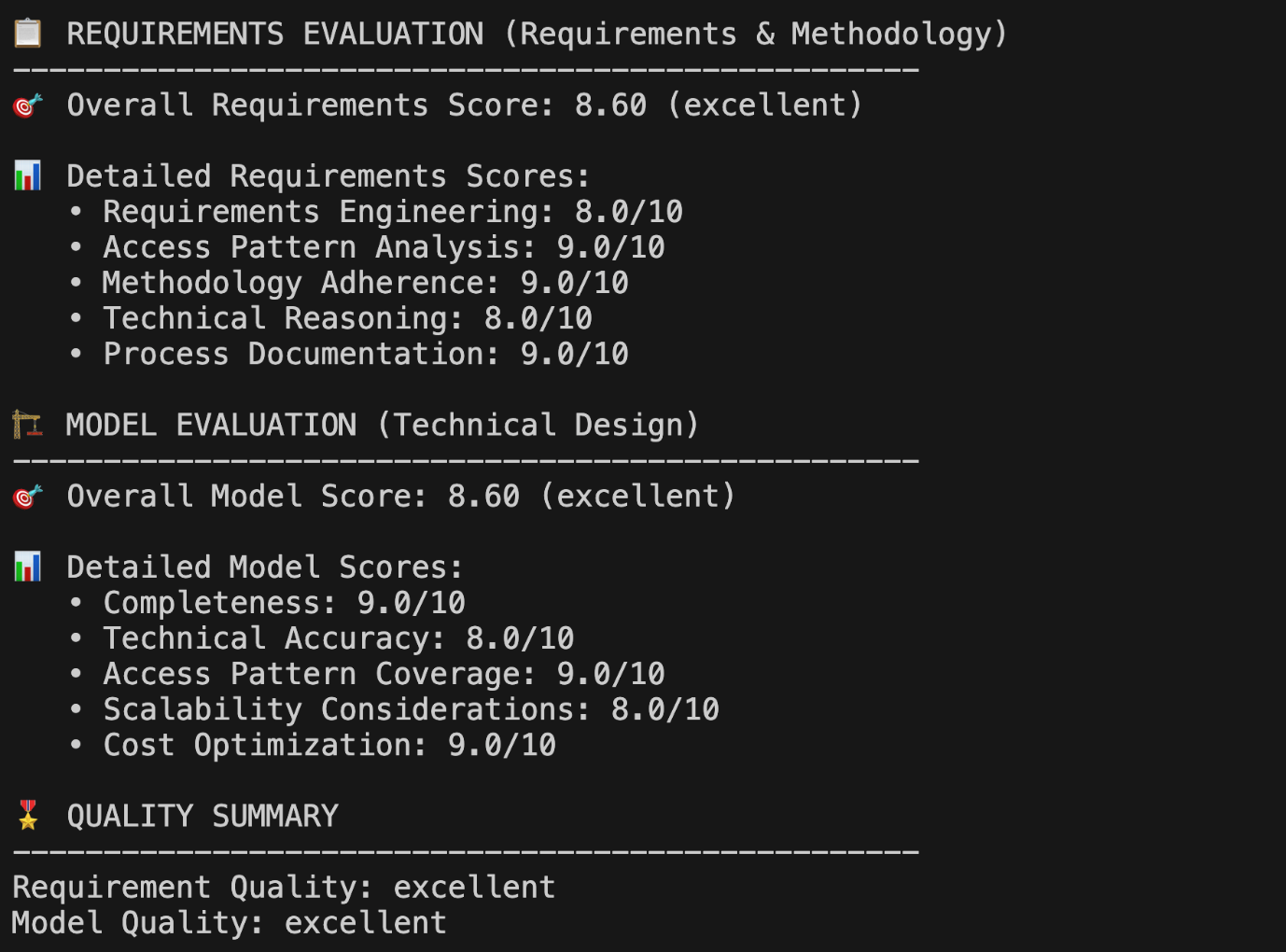
Цей багатовимірний бал дає вам негайне розуміння того, що працює добре (аналіз моделі доступу набрав 9/10) та що потребує уваги (технічні міркування на 8/10 пропонують можливість покращити глибину масштабованості). Замість того, щоб вручну переглядати тривалі стенограми розмови, ви отримуєте діючі відгуки за 3 хвилини.
Чому це має значення
Такі оцінки допомагають нам декількома способами. Вони ловлять регресії рано, коли ми вдосконалюємо підказки або змінюємо моделі. Вони дають нам послідовний спосіб порівняння підходів, а не покладатися на анекдотичні огляди. І вони будують довіру; Коли інструмент створює модель даних, ви знаєте, що вона була перевірена в декількох сценаріях і забила за чіткими критеріями.
Для клієнтів це означає, що рекомендації, які ви отримуєте від інструменту моделювання даних DynamoDB, продовжують вдосконалюватися з часом. Для будівельників інструментів MCP ширше він показує візерунок, який ви можете повторно використовувати: агенти Strands для імітації реалістичних розмов, DSPY для визначення показників та Amazon Bedrock для постачання моделей.
Висновок
Інструмент моделювання даних DynamoDB допомагає розробити масштаб, але, як і інші системи, керовані AI, він додає значення лише в тому випадку, якщо результати надійні. Поєднуючи агенти Strands, DSPY та Amazon Bedrock, ми перетворили суб'єктивні огляди на вимірювані сигнали, що дозволяє швидше ітерації та більш високу впевненість у рекомендаціях інструменту.
Ви можете вивчити рамки оцінювання у сховищі Github, прочитати про підхід DSPY до оцінки або спробувати агенти Strands, щоб імітувати власні робочі процеси MCP. Поки ми продовжуємо розвивати систему, наша мета проста: надати вам кращі інструменти, кращі моделі та кращі результати під час побудови на DynamoDB.
Про авторів