

Зображення автора
# вступ
Ви, мабуть, чули кліше: «Дані — це основа сучасних організацій». Це вірно, але тільки якщо ви можете покластися на цей хребет. Я не обов’язково говорю про стан самих даних, а радше про систему, яка створює та переміщує дані.
Якщо інформаційні панелі ламаються, конвеєри виходять з ладу, а показники змінюються випадковим чином, проблема полягає не в недостатній якості даних, а у відсутності спостережуваності.
# Що таке спостережуваність даних?
Спостереженість даних — це процес моніторингу працездатності та надійності систем даних.
Цей процес допомагає групам обробки даних виявляти, діагностувати та запобігати проблемам у стеку аналітики — від прийому даних до зберігання й аналізу — перш ніж вони вплинуть на прийняття рішень.
Завдяки можливості спостереження за даними ви відстежуєте такі аспекти даних і системи.

Зображення автора
- Актуальність даних: відстежує, наскільки актуальні дані порівняно з очікуваним графіком оновлення. Приклад: якщо щоденну таблицю продажів не оновлено до 7 ранку за розкладом, інструменти спостережень видають сповіщення, перш ніж бізнес-користувачі скористаються звітами про продажі.
- Обсяг даних: вимірює, скільки даних надходить або обробляється на кожному етапі. Приклад: падіння записів транзакцій на 38% за одну ніч може означати, що завдання прийому даних було порушено.
- Схема даних: виявляє зміни в назвах стовпців, типах даних або структурах таблиць. Приклад: якщо новий виробник даних надсилає оновлену схему до виробництва без попередження.
- Розподіл даних: перевірте статистичну форму даних, тобто чи виглядають вони нормально. Приклад: відсоток клієнтів преміум-класу впадає з 29% до 3% за ніч. Спостережливість виявить це як аномалію та запобіжить оманливому аналізу швидкості відтоку.
- Походження даних: візуалізує потік даних у екосистемі, від прийому через перетворення до кінцевих інформаційних панелей. Приклад: вихідна таблиця в Snowflake не вдається, і в поданні походження буде показано, що три інформаційні панелі Looker і дві моделі машинного навчання залежать від неї.
# Чому спостережуваність даних важлива
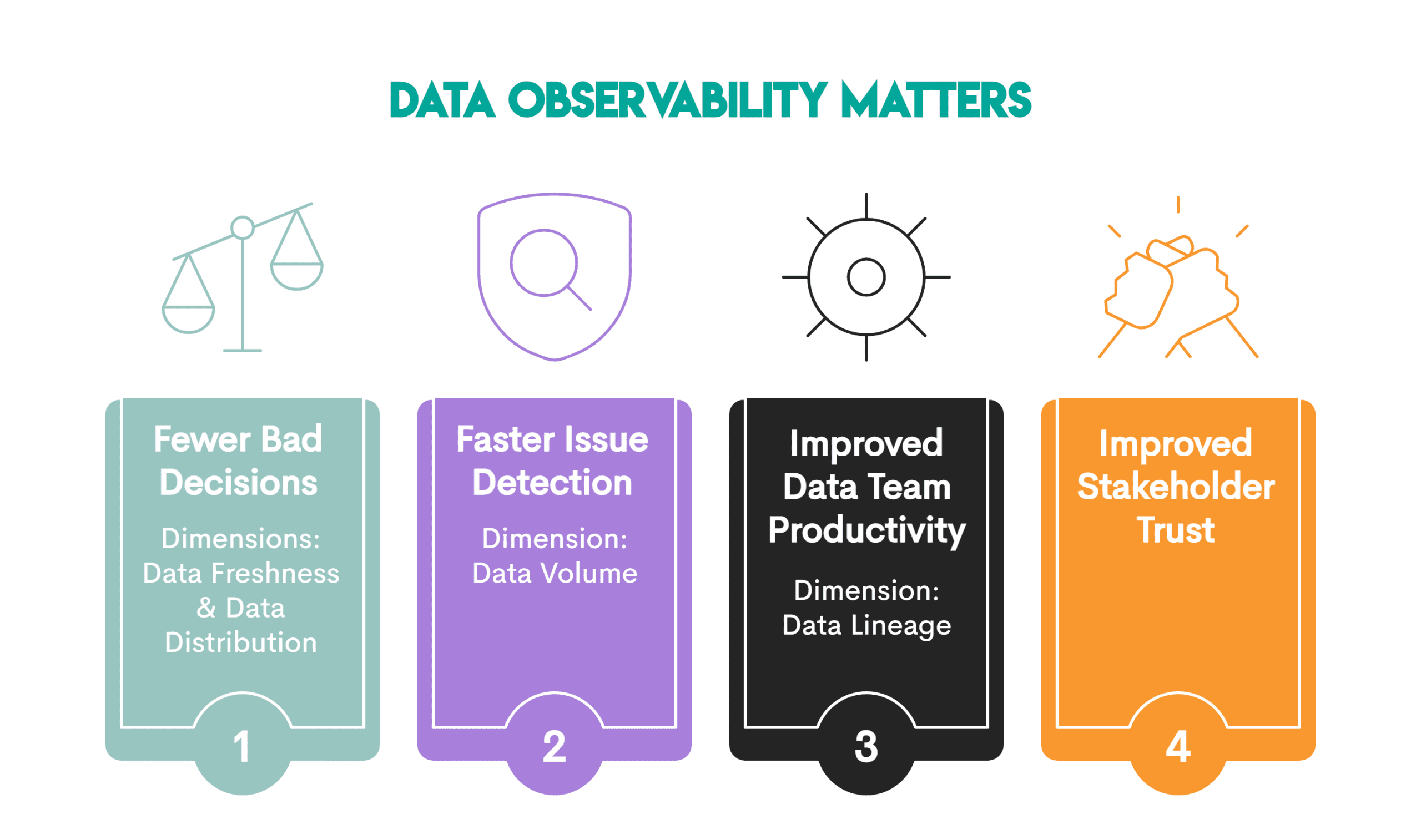
Переваги спостережуваності даних в аналітиці показано нижче.
Зображення автора
Кожен із параметрів або стовпів спостережуваності даних, про які ми згадували раніше, відіграє певну роль у досягненні загальних переваг спостережуваності даних.
- Менше поганих рішень: можливість спостереження за даними гарантує, що аналітика відображає поточні умови бізнесу (параметр актуальності даних) і що цифри та шаблони даних мають сенс, перш ніж використовувати їх для аналізу (розмір розподілу даних), що призводить до меншої кількості рішень, які можуть піти не так.
- Швидше виявлення проблеми: коли системи раннього попередження сповіщають вас про те, що дані завантажуються неповно або дублюються (розмірність обсягу даних) та/або є структурні зміни, які могли б тихо зламати трубопроводи, аномалії виявляються ще до того, як бізнес-користувачі їх навіть помітять.
- Покращена продуктивність команди даних: параметр походження даних відображає те, як дані переходять між системами, що полегшує відстеження, звідки почалася помилка та які активи зазнали впливу. Команда обробки даних зосереджена на розробці, а не на боротьбі з пожежами.
- Краща довіра зацікавлених сторін: це останній бос переваг спостереження за даними. Довіра зацікавлених сторін є кінцевим результатом трьох попередніх переваг. Якщо зацікавлені сторони можуть довіряти групі обробки даних, що дані є актуальними, повними, стабільними, точними, і всі знають, звідки вони взялися, довіра до аналітики випливає природно.
# Життєвий цикл і методи спостереження за даними
Як ми вже згадували раніше, можливість спостереження за даними – це процес. Його безперервний життєвий цикл складається з цих етапів.

Зображення автора
// 1. Етап моніторингу та виявлення
Мета: надійна система раннього попередження, яка в режимі реального часу перевіряє, чи щось дрейфує, зламається чи відхиляється у ваших даних.
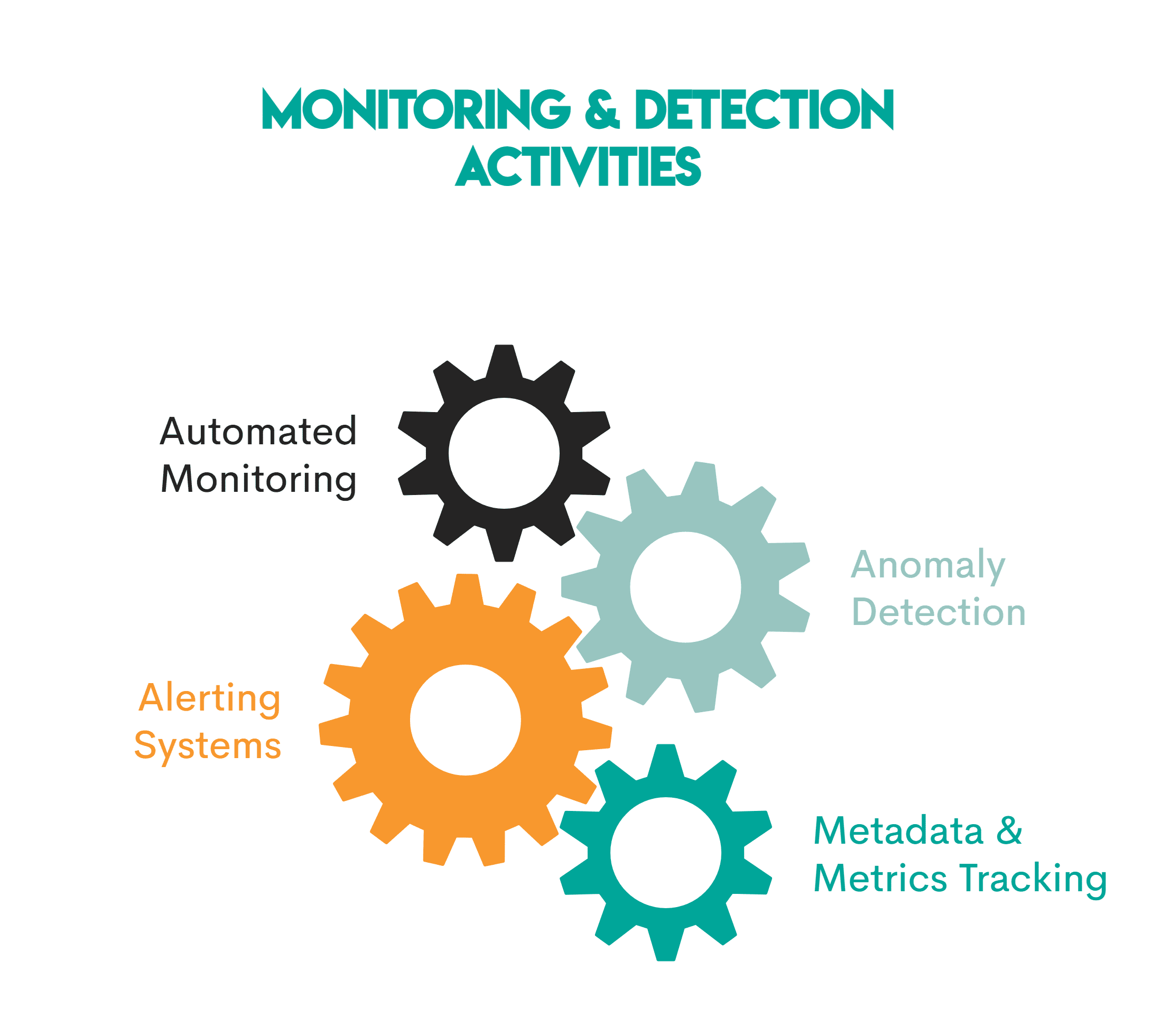
Що тут відбувається:
Зображення автора
- Автоматизований моніторинг: Інструменти спостереження автоматично відстежують доступність даних за всіма п’ятьма основними компонентами
- Виявлення аномалії: машинне навчання використовується для виявлення статистичних аномалій у даних, наприклад, несподіване падіння кількості рядків
- Системи оповіщення: щоразу, коли відбувається будь-яке порушення, системи надсилають сповіщення Млява, PagerDutyабо електронною поштою
- Відстеження метаданих і показників: системи також відстежують інформацію, таку як тривалість завдання, рівень успіху та час останнього оновлення, щоб зрозуміти, що означає «нормальна поведінка».
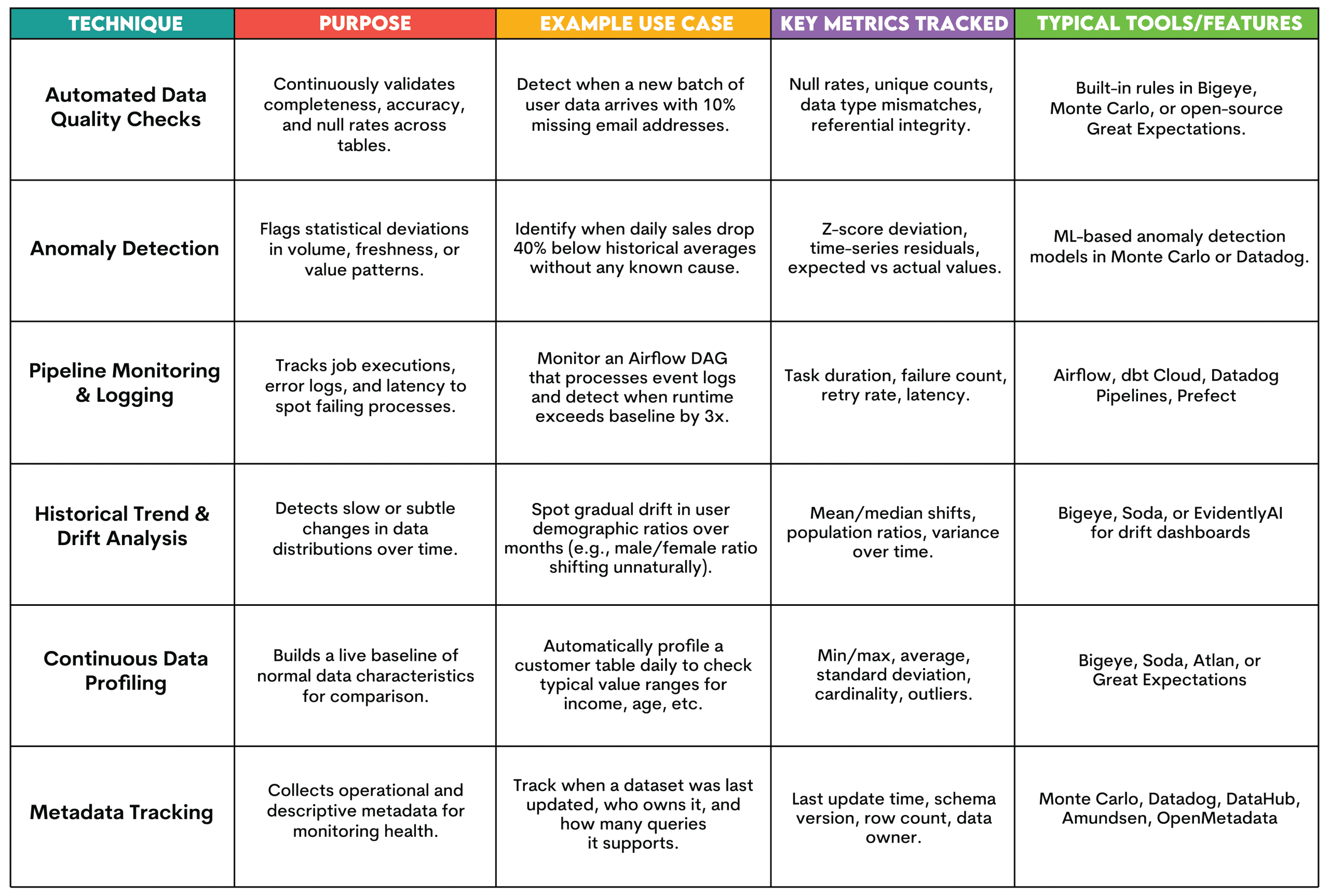
// Методи моніторингу та виявлення
Ось огляд поширених прийомів, які використовуються на цьому етапі.
// 2. Етап діагностики та розуміння
Мета: зрозуміти, з чого виникла проблема та на які системи вона вплинула. Таким чином, відновлення може бути швидким або, якщо є кілька проблем, їх можна визначити за пріоритетністю залежно від тяжкості їх впливу.
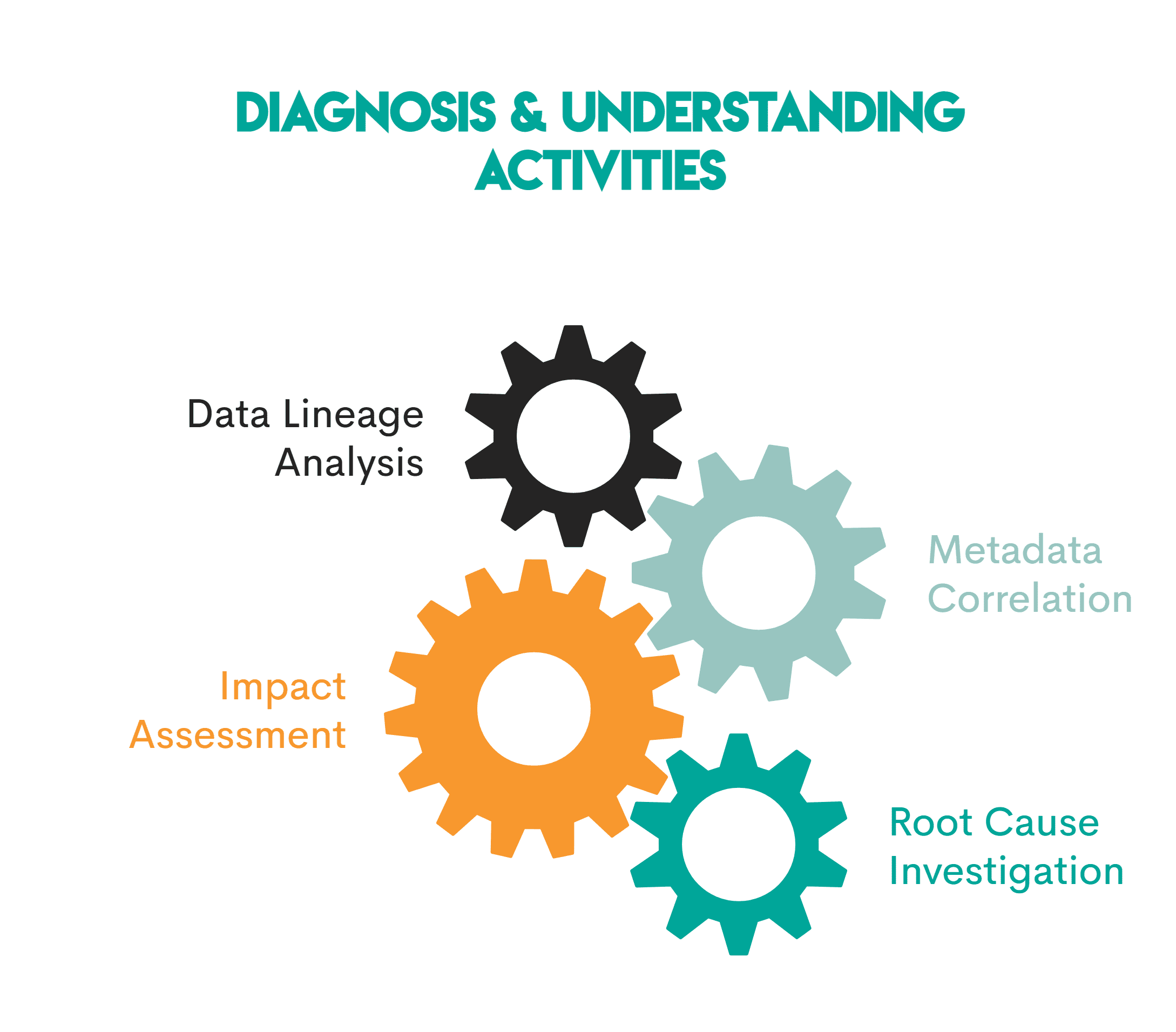
Що тут відбувається:
Зображення автора
- Аналіз походження даних: Інструменти спостереження візуалізують дані від необроблених джерел до остаточних інформаційних панелей, що полегшує визначення місця виникнення проблеми
- Кореляція метаданих: тут також використовуються метадані, щоб визначити проблему та її місце розташування
- Оцінка впливу: Що вплинуло? Інструменти ідентифікують активи (наприклад, інформаційні панелі чи моделі), розташовані нижче за місцем виникнення проблеми, і покладаються на дані, на які впливає проблема
- Дослідження першопричини: походження та метадані використовуються для визначення першопричини проблеми
// Методи діагностики та розуміння
Ось огляд технік, які використовуються на цьому етапі.
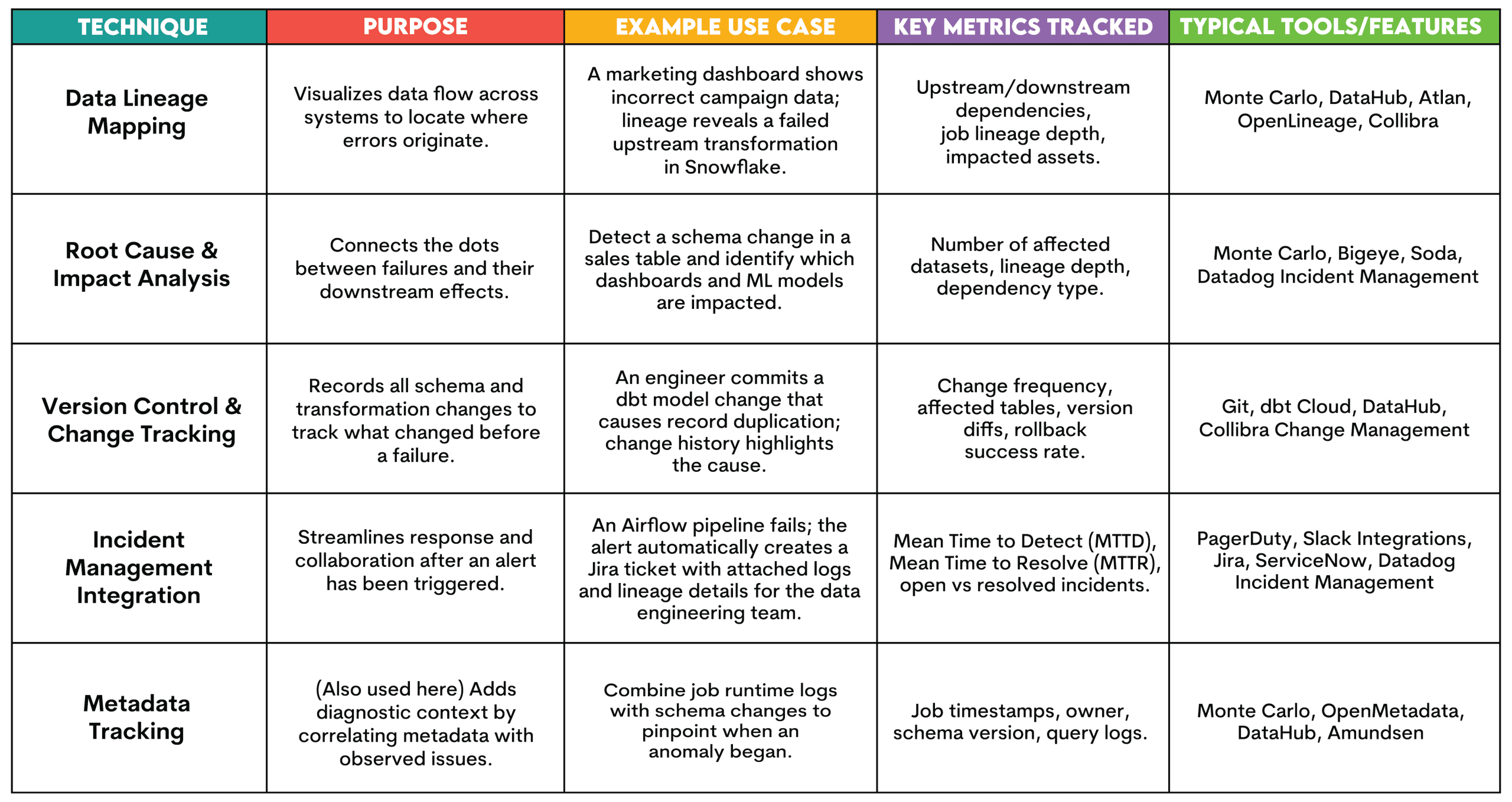
// 3. Етап профілактики та покращення
Мета: вчитися на тому, що зламалося, і робити системи даних більш стійкими з кожним інцидентом шляхом встановлення стандартів, автоматизації виконання та моніторингу відповідності.
Що тут відбувається:

Зображення автора
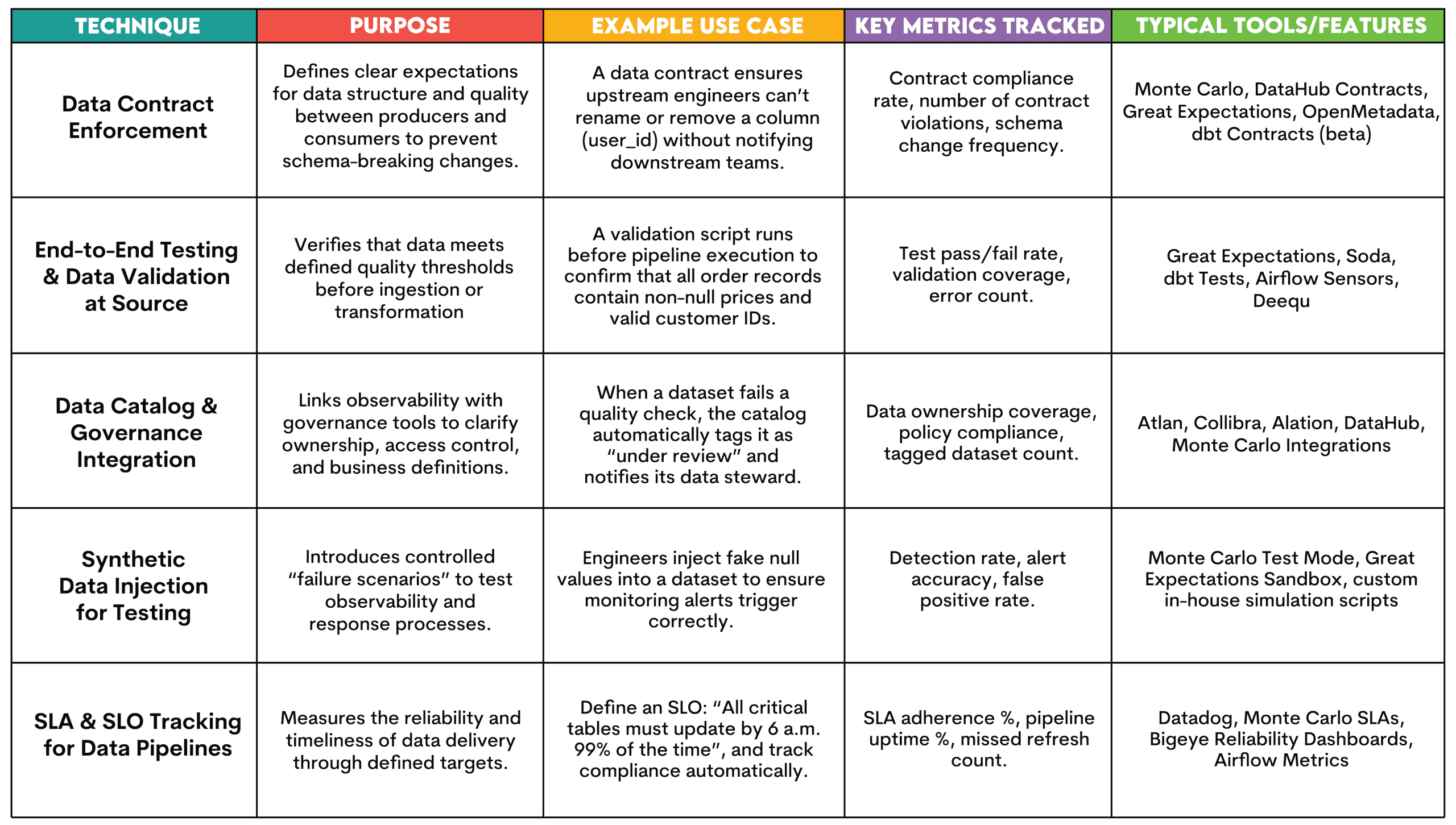
- Контракти даних: Угоди між виробниками та споживачами визначають прийнятну схему та стандарти якості, тому немає неоголошених змін даних
- Тестування та перевірка: Автоматизовані тести (наприклад, через dbt тести або Великі сподівання) переконайтеся, що нові дані відповідають визначеним пороговим значенням перед опублікуванням. Для команд, які покращують свої навички аналітики даних і налагодження SQL, такі платформи, як StrataScratch може допомогти практикам розвинути аналітичну точність, необхідну для виявлення та запобігання проблемам якості даних
- СЛАМ & СЛАМ Відстеження: команди визначають і контролюють вимірювані цілі щодо надійності (угоди про рівень обслуговування та цілі рівня обслуговування), наприклад, 99% конвеєрів завершено вчасно
- Розслідування інциденту: кожне питання переглядається, що допомагає покращити правила моніторингу та спостережливість загалом
- Управління та контроль версій: Зміни відстежуються, документація створюється, і є призначення права власності
// Методи профілактики та покращення
Ось огляд технік.
# Інструменти спостереження за даними
Тепер, коли ви розумієте, що робить спостереження даних і як воно працює, настав час познайомити вас з інструментами, які ви використовуватимете для його впровадження.
Нижче наведено інструменти, які найчастіше використовуються.

Зображення автора
Ми розглянемо кожен із цих інструментів докладніше.
// 1. Монте-Карло
Монте Карло є галузевим стандартом і першим формалізував модель п’яти стовпів. Він забезпечує повну видимість стану даних у конвеєрі.
Ключові переваги:
- Охоплює всі стовпи спостереження за даними
- Аномалії та зміна схеми відбуваються автоматично, тобто не потрібно налаштовувати правила вручну
- Детальне відображення походження даних і аналіз впливу
Обмеження:
- Не зовсім підходить для невеликих команд, оскільки розроблено для масштабного розгортання
- Ціноутворення підприємства
// 2. Datadog
Datadog починався як інструмент для моніторингу серверів, програм та інфраструктури. Тепер він забезпечує уніфіковану можливість спостереження за серверами, програмами та конвеєрами.
Ключові переваги:
- Співвідносить проблеми з даними з показниками інфраструктури (ЦП, затримка, пам’ять)
- Інформаційні панелі та сповіщення в реальному часі
- Інтегрується, наприклад, з Apache Airflow, Apache Spark, Апач Кафкаі більшість хмарних платформ
Обмеження:
- Більша увага приділяється працездатності, а не глибоким перевіркам якості даних
- Не вистачає розширеного виявлення аномалій або перевірки схеми в спеціалізованих інструментах
// 3. Велике око
Велике око автоматизує моніторинг якості даних за допомогою машинного навчання та базових статистичних даних.
Ключові переваги:
- Автоматично генерує сотні показників свіжості, обсягу та розповсюдження
- Дозволяє користувачам візуально встановлювати та контролювати дані SLA/SLO
- Просте налаштування з мінімальними інженерними витратами
Обмеження:
- Менше уваги до глибокої візуалізації походження або моніторингу на рівні системи
- Менший набір функцій для діагностики першопричин порівняно з методом Монте-Карло
// 4. Сода
Сода це інструмент із відкритим вихідним кодом, який підключається безпосередньо до баз даних і сховищ даних для тестування та моніторингу якості даних у реальному часі.
Ключові переваги:
- Зручний для розробників із тестами на основі SQL, які інтегруються в робочі процеси CI/CD
- Версія з відкритим кодом доступна для невеликих команд
- Сильна співпраця та особливості управління
Обмеження:
- Потрібне ручне налаштування для складного текстового покриття
- Обмежені можливості автоматизації
// 5. Acceldata
Acceldata це інструмент, який поєднує перевірку якості даних, продуктивності та вартості.
Ключові переваги:
- Спільно відстежує надійність даних, продуктивність конвеєра та показники вартості хмари
- Управління гібридними та багатохмарними середовищами
- Легко інтегрується з Spark, Hadoopта сучасні сховища даних
Обмеження:
- Орієнтоване на підприємство та складне налаштування
- Менше уваги до якості даних на рівні стовпців або виявлення відхилень
// 6. Ненормальний
Аномальний це платформа на базі штучного інтелекту, орієнтована на автоматичне виявлення аномалій, що вимагає мінімальної конфігурації.
Ключові переваги:
- Автоматично вивчає очікувану поведінку з історичних даних, правила не потрібні
- Чудово підходить для моніторингу змін схеми та розподілу значень
- Виявляє тонкі, неочевидні аномалії в масштабі
Обмеження:
- Обмежене налаштування та ручне створення правил для розширених випадків використання
- Зосереджено на виявленні з меншою кількістю інструментів діагностики чи керування
# Висновок
Спостереженість даних — важливий процес, який зробить вашу аналітику надійною. Процес побудований на п’яти стовпах: свіжість, обсяг, схема, розподіл і походження даних.
Його ретельне впровадження допоможе вашій організації приймати менше неправильних рішень, оскільки ви зможете уникнути проблем у конвеєрах даних і швидше їх діагностувати. Це покращує ефективність роботи групи обробки даних і підвищує достовірність їхніх ідей.
Нейт Росіді є науковцем із обробки даних і займається стратегією продуктів. Він також є ад’юнкт-професором, який викладає аналітику, і є засновником StrataScratch, платформи, яка допомагає дослідникам даних готуватися до інтерв’ю за допомогою реальних питань для інтерв’ю від провідних компаній. Нейт пише про останні тенденції ринку кар’єри, дає поради на співбесідах, ділиться науковими проектами з даних і охоплює все, що стосується SQL.