
Швидкий і надійний доступ до інформації має вирішальне значення для прийняття розумних бізнес-рішень. Ось чому компанії звертаються до Amazon OpenSearch Service, щоб розширити свої пошукові та аналітичні можливості. Служба OpenSearch спрощує розгортання, роботу та масштабування пошукових систем у хмарі, забезпечуючи такі випадки використання, як аналіз журналів, моніторинг додатків і пошук на веб-сайтах.
Ефективне керування індексами OpenSearch Service і ресурсами кластерів може призвести до значного покращення продуктивності, масштабованості та надійності – усе це безпосередньо впливає на прибутки компанії. Однак галузі бракує вбудованих і добре задокументованих рішень для автоматизації цих важливих операційних завдань.
Застосування постійної інтеграції та постійного розгортання (CI/CD) для керування ресурсами індексу OpenSearch може допомогти в цьому. Наприклад, збереження конфігурацій індексів у вихідному сховищі дозволяє краще відстежувати, співпрацювати та відкочувати. Використання інструментів інфраструктури як коду (IaC) може допомогти автоматизувати створення ресурсів, забезпечуючи послідовність і зменшуючи ручну роботу. Нарешті, використання конвеєра CI/CD може автоматизувати розгортання та оптимізувати робочий процес.
У цій публікації ми обговорюємо два варіанти досягнення цієї мети: постачальник Terraform OpenSearch і бібліотеку Evolution. Який з них найкраще підходить для вашого випадку використання, залежить від інструментів, з якими ви знайомі, мови, яку ви вибрали, і наявного конвеєра.
Огляд рішення
Давайте пройдемося по простій реалізації. Для цього випадку використання ми використовуємо AWS Cloud Development Kit (AWS CDK), щоб забезпечити відповідну інфраструктуру, як описано на наведеній нижче схемі архітектури, AWS Lambda для запуску сценаріїв Evolution і AWS CodeBuild для застосування файлів Terraform. Ви можете знайти код для всього рішення в репозиторії GitHub.

передумови
Щоб слідувати цій публікації, вам потрібно мати наступне:
- Знайомство з Java та OpenSearch
- Знайомство з AWS CDK, Terraform і командним рядком
- На вашій машині встановлено наступні версії програмного забезпечення: Python 3.12, NodeJS 20 і AWS CDK 2.170.0 або вище
- Обліковий запис AWS із роллю AWS Identity and Access Management (IAM), налаштованою з відповідними дозволами
Побудуйте рішення
Щоб створити автоматизоване рішення для керування кластером OpenSearch Service, виконайте такі дії:
- Введіть наступні команди в терміналі, щоб завантажити код рішення; створити програму Java; побудувати необхідний лямбда-шар; створити домен OpenSearch, дві функції Lambda та проект CodeBuild; і розгорніть код:
- Зачекайте від 15 до 20 хвилин, доки інфраструктура завершить розгортання, а потім перевірте, чи ваш домен OpenSearch запущений і працює, а функцію Lambda та проект CodeBuild створено, як показано на наступних знімках екрана.


Перш ніж використовувати автоматизовані інструменти для створення шаблонів покажчиків, ви можете переконатися, що жодного з них уже не існує за допомогою OpenSearchQuery Лямбда-функція.
- На консолі Lambda перейдіть до потрібного функція
- На Тест вкладка, виберіть Тест.
Функція має повернути повідомлення «Немає шаблонів індексів, створених Terraform або Evolution», як показано на наступному знімку екрана.

Застосуйте файли Terraform
По-перше, ви використовуєте Terraform із CodeBuild. Код готовий для тестування, давайте розглянемо кілька важливих елементів конфігурації:
- Визначте необхідні змінні для вашого середовища:
- Визначте та налаштуйте провайдера
ПРИМІТКА: Станом на дату публікації цього допису в провайдері Terraform OpenSearch є помилка, яка спрацьовує під час запуску вашого проекту CodeBuild і перешкоджає успішному виконанню. Поки це не буде виправлено, використовуйте наступну версію:
- Створіть шаблон покажчика
Тепер ви готові до тестування.
- На консолі CodeBuild перейдіть до відповідного проекту та виберіть Розпочати збірку.
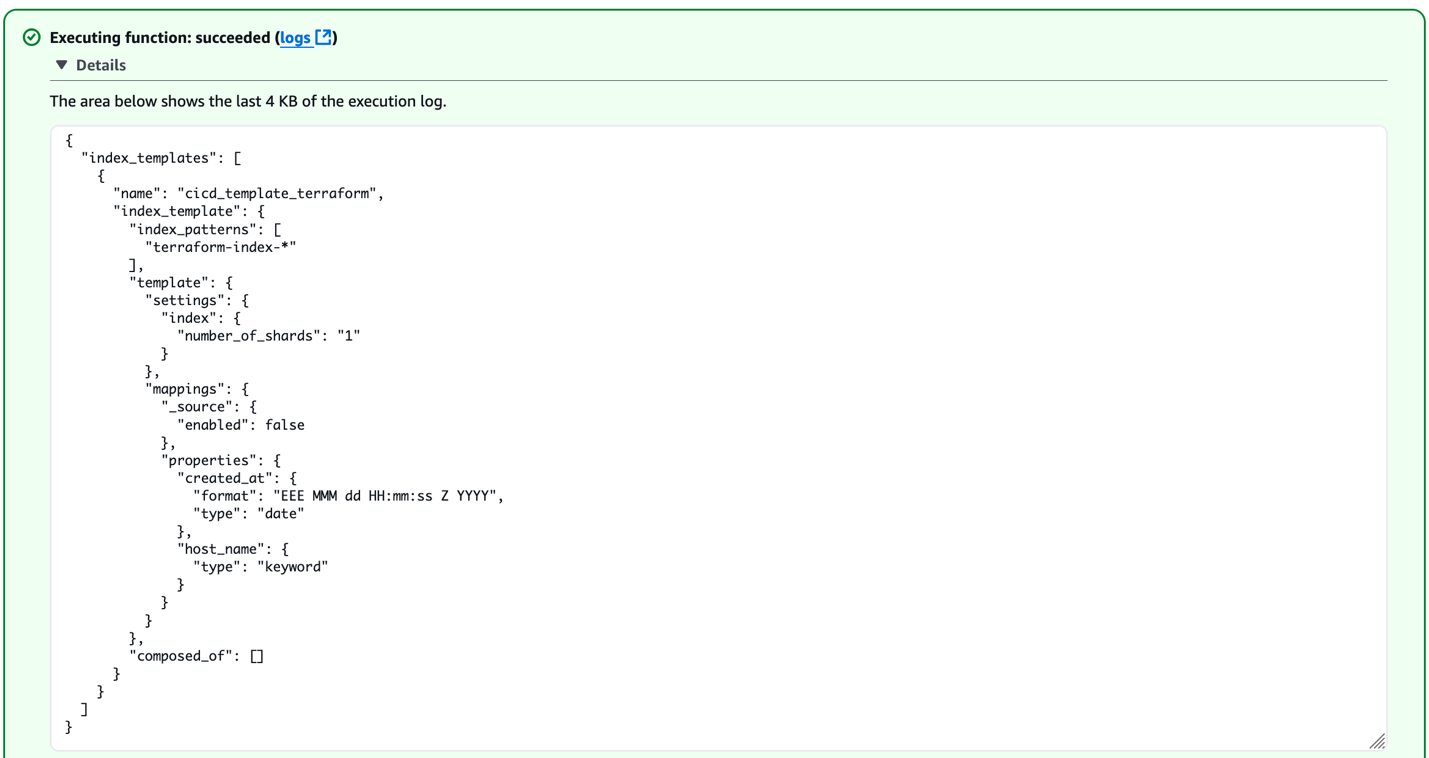
Складання має завершитися успішно, і ви побачите такі рядки в журналах:
Ви можете перевірити, чи правильно створено шаблон індексу за допомогою тієї ж функції Lambda, що й раніше, і побачите такі результати.
Запустіть сценарії Evolution
На наступному кроці ви використовуєте бібліотеку Evolution. Код готовий для тестування, давайте розглянемо кілька важливих частин коду та конфігурації:
- Для початку вам потрібно додати останню версію базової бібліотеки Evolution і AWS SDK як залежності Maven. Повний файл xml доступний у репозиторії GitHub; щоб перевірити сумісність бібліотеки Evolution з різними версіями OpenSearch, дивіться тут.
- Створіть Evolution Bean і перехоплювач AWS (який реалізує
HttpRequestInterceptor).
Перехоплювачі — це відкриті механізми, у яких SDK викликає код, який ви пишете, щоб ввести поведінку в життєвий цикл запиту та відповіді. Функція перехоплювача AWS полягає у підключенні до виконання запитів API і створенні підписаного запиту AWS із відповідними ролями IAM. Ви можете використати наведений нижче код, щоб створити власну реалізацію для підпису всіх запитів, зроблених до OpenSearch в AWS.
- Створіть власний клієнт OpenSearch, щоб керувати автоматичним створенням індексів, зіставлень, шаблонів і псевдонімів.
Клієнт ElasticSearch за замовчуванням, який постачається в комплекті як частина залежності Maven, не можна використовувати для створення PUT виклики до кластера OpenSearch. Тому вам потрібно обійти типовий екземпляр клієнта REST і додати a CallBack до AwsRequestSigningInterceptor.
Нижче наведено приклад реалізації:
- Використовуйте Evolution Bean для виклику методу міграції, який відповідає за ініціювання міграції сценаріїв, визначених або за допомогою
classpathабоfilepath:
- Ан
Evolutionсценарій міграції представляє виклик REST до API OpenSearch (наприклад,PUT /_index_template/cicd_template_evolution), де ви визначаєте шаблони індексів, налаштування та зіставлення у форматі JSON. Evolution інтерпретує ці сценарії, керує їхніми версіями та забезпечує впорядковане виконання. Подивіться наступний приклад:
Перші два рядки має йти порожній рядок. Evolution також підтримує рядки коментарів у своїх сценаріях міграції. Кожен рядок, що починається з # або // буде інтерпретовано як рядок коментаря. Рядки коментарів не надсилаються до OpenSearch. Натомість вони фільтруються Evolution.
Правила іменування файлів сценарію міграції мають відповідати шаблону:
- Почніть з
esMigrationPrefixщо є за замовчуваннямVабо значення, яке було налаштовано за допомогою параметра конфігураціїesMigrationPrefix - Після цього номер версії, який має бути числовим і може бути структурованим шляхом розділення частин версії крапкою (
.) - Слідом за
versionDescriptionSeparator:__(символ подвійного підкреслення) - Далі йде опис, який може бути будь-яким текстом, який підтримує ваша файлова система
- Закінчити з
esMigrationSuffixesщо є за замовчуванням.httpі налаштовується та не враховує регістр
Тепер ви готові виконати свою першу автоматичну зміну. Для вас уже створено приклад сценарію міграції, який ви можете переглянути в попередньому розділі. Він створить шаблон індексу з назвою cicd_template_evolution.
- На консолі Lambda перейдіть до своєї функції.
- На Тест вкладка, виберіть Тест.
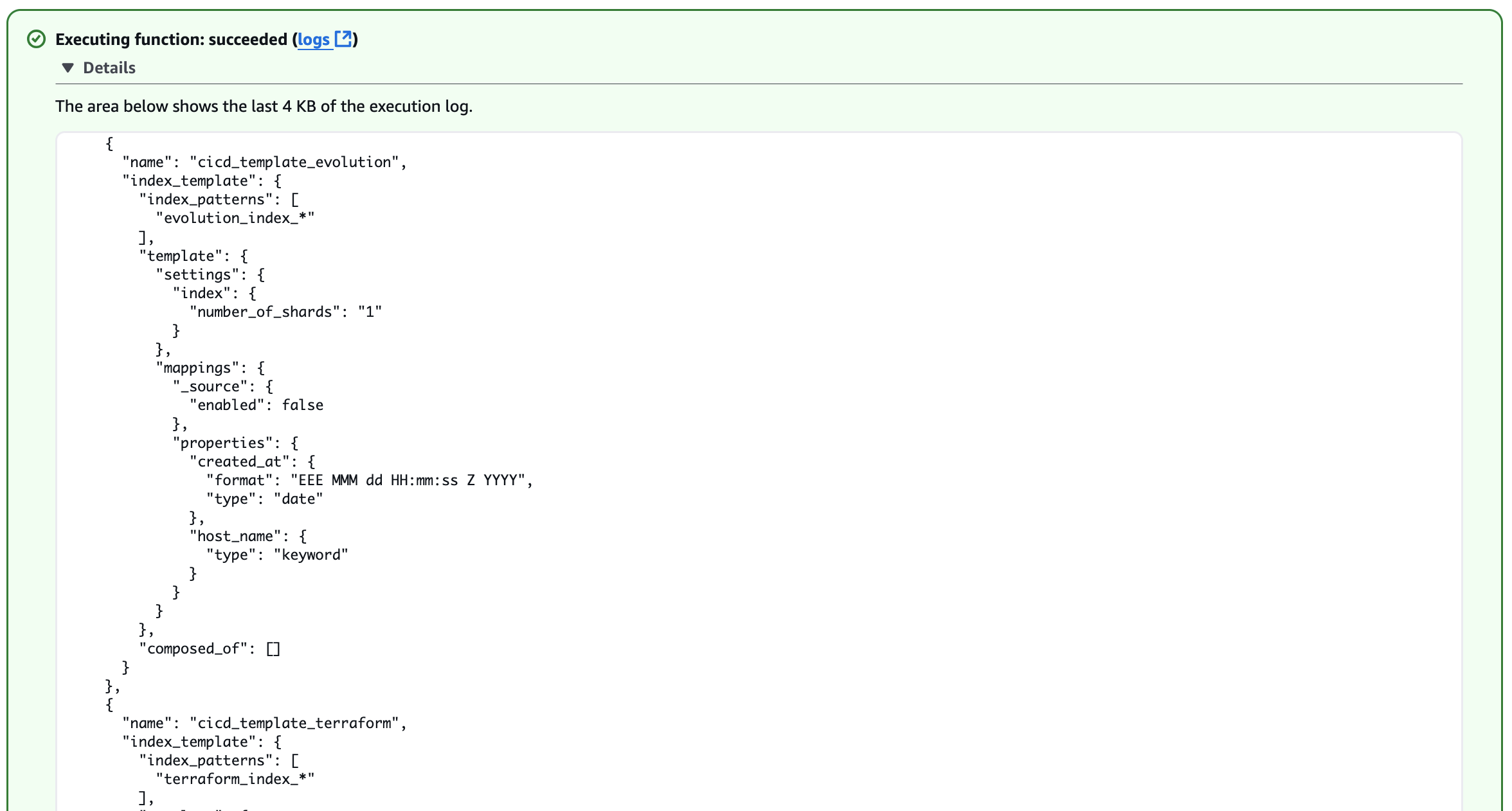
Через кілька секунд функція має успішно завершитися. Ви можете переглянути вихідні дані журналу в Подробиці розділ, як показано на наступних знімках екрана.
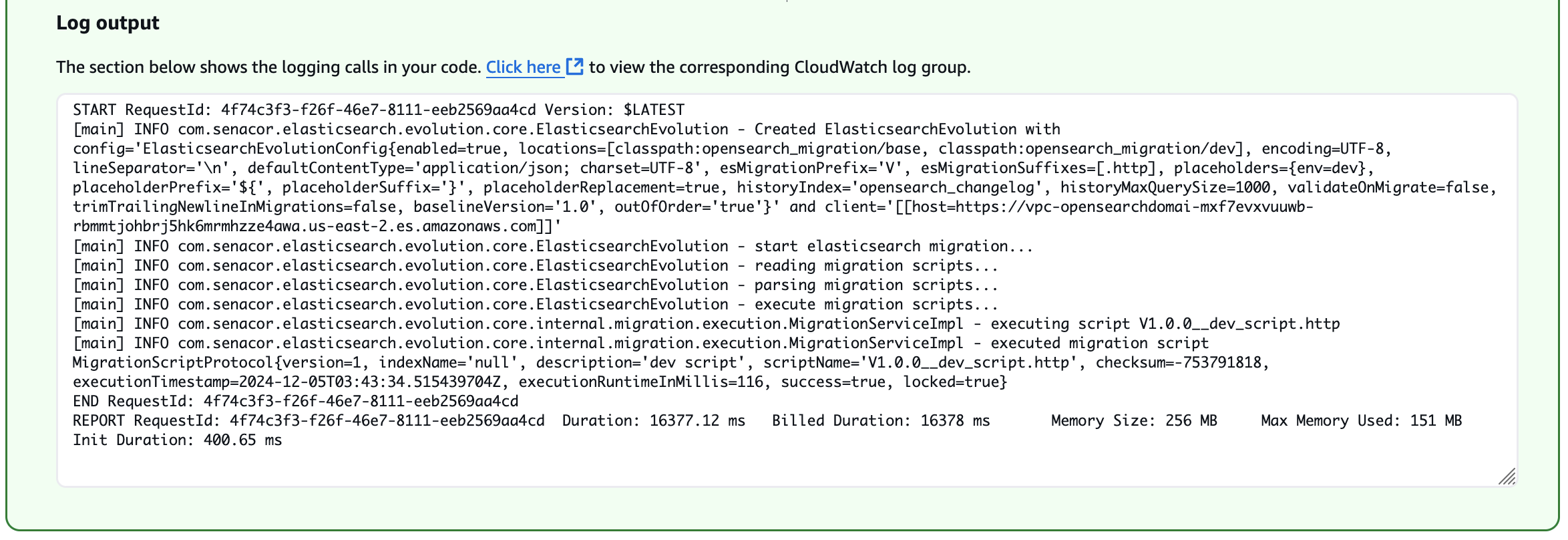
Шаблон індексу тепер існує, і ви можете перевірити, чи його конфігурація справді відповідає сценарію, як показано на наступному знімку екрана.
Прибирати
Щоб очистити ресурси, створені в рамках цієї публікації, виконайте такі команди (у infra папка):
Висновок
У цьому дописі ми продемонстрували, як автоматизувати шаблони індексів OpenSearch за допомогою методів CI/CD та таких інструментів, як Terraform або бібліотека Evolution.
Щоб дізнатися більше про службу OpenSearch, зверніться до посібника розробника служби Amazon OpenSearch. Щоб глибше вивчити бібліотеку Evolution, зверніться до документації. Щоб дізнатися більше про постачальника Terraform OpenSearch, зверніться до документації.
Ми сподіваємося, що цей докладний посібник і супровідний код допоможуть вам почати роботу. Спробуйте, поділіться з нами своїми думками в коментарях і не соромтеся звертатися до нас із запитаннями!
Про авторів
 Каміль Бірбес є старшим архітектором рішень в AWS і працює в Гонконзі. Він співпрацює з великими фінансовими установами для розробки та створення безпечних, масштабованих і високодоступних рішень у хмарі. Поза роботою Камілла захоплюється будь-якими видами ігор, від настільних до новітніх відеоігор.
Каміль Бірбес є старшим архітектором рішень в AWS і працює в Гонконзі. Він співпрацює з великими фінансовими установами для розробки та створення безпечних, масштабованих і високодоступних рішень у хмарі. Поза роботою Камілла захоплюється будь-якими видами ігор, від настільних до новітніх відеоігор.
 Шріхарша Субраманья Беголлі працює старшим архітектором рішень в AWS, що базується в Бенгалуру, Індія. Його основна увага — допомога великим корпоративним клієнтам у модернізації їхніх програм і розробці хмарних систем для досягнення їхніх бізнес-цілей. Його експертиза лежить у сферах даних і аналітики.
Шріхарша Субраманья Беголлі працює старшим архітектором рішень в AWS, що базується в Бенгалуру, Індія. Його основна увага — допомога великим корпоративним клієнтам у модернізації їхніх програм і розробці хмарних систем для досягнення їхніх бізнес-цілей. Його експертиза лежить у сферах даних і аналітики.