
Alibaba Cloud оприлюднила свою останню модель візуальної мови, QWEN2.5-VL, що суттєво посилює свого попередника QWEN2-VL. Ця мультимодальна модель з відкритим кодом пропонується в різних розмірах, починаючи від 3 мільярдів, 7 мільярдів до 72 мільярдів параметрів і включає як базові, так і інструкційні версії. Флагманська модель, QWEN2.5-VL-72B-Instruct, тепер доступна через платформу QWEN CHAT, в той час як вся серія QWEN2.5-VL доступна на обсязі моделі спільноти Alibaba та Alibaba.
QWEN2.5-VL демонструє чудові багатомодальні можливості, видатні в розширеному візуальному розумінні текстів, діаграм, діаграм, графіки та макетів у зображеннях. Він також може зрозуміти відео довше години та відповідати на відео, пов'язані з відео, при цьому точно визначивши конкретні сегменти до точної секунди. Крім того, модель може генерувати структуровані результати, наприклад, у форматі JSON, перетворення неструктурованих даних із сканування рахунків -фактур, форм або таблиць в організовану інформацію, що особливо корисно для автоматизації обробки фінансових звітів або юридичних документів.
Поєднуючи можливості розбору та локалізації, QWEN2.5-VL також може слугувати візуальний агент Для полегшення виконання простих завдань на комп’ютерах та мобільних пристроях, таких як перевірка погоди та бронювання польотного квитка, шляхом режисури використання різних інструментів.
Зокрема, флагманська модель QWEN2.5-VL-72B-Instruct досягає конкурентоспроможної роботи в серії орієнтирів, що висвітлюють домени та завдання, включаючи читання документів та діаграм, загальна відповіді на візуальні запитання, математика на рівні коледжу, розуміння відео та візуальний агент.

Для поліпшення багатомодальних показників дослідники, що стоять за моделлю, впровадили динамічну роздільну здатність та навчання кадрів для покращення розуміння відео. Вони також ввели більш обтічний та ефективний візуальний кодер. Це значно покращило як швидкість тренувань, так і виходи, використовуючи механізми уваги вікон в архітектурі динамічного трансформатора зору (VIT). Ці інновації роблять QWEN2.5-VL універсальним та потужним інструментом для складних мультимодальних застосувань у секторах.
Розширення вкладу контексту до 1 мільйона жетонів
Крім того, Alibaba Cloud оприлюднила свою останню версію великої мови QWEN, відомої як Qwen2.5-1m. Ця ітерація з відкритим кодом відрізняється її здатністю обробляти довгі контекстні входи, здатність обробляти до 1 мільйона жетонів.
Як правило, здатність керувати більш тривалими контекстами дозволяє моделям вирішувати більш складні сценарії реального світу, які вимагають значної обробки інформації або генерації. Як результат, розширення контекстного вікна великих мовних моделей (LLM) може краще вирішувати завдання, такі як перетравлення документів і генерація довгих форм, що робить LLM, що триває, стало новою тенденцією.
Випуск цього разу включає дві версії налаштованих інструкцій моделей, QWEN2.5-7B-Instruct-1M та QWEN2.5-14B-Instruct-1M, які мають 7 мільярдів та 14 мільярдів параметрів відповідно. Обидві версії були доступні для Hunging Face, а також їх технічний звіт.
Крім того, Pioneer Cloud та AI випустив відповідну рамку висновку, оптимізовану для обробки довгих контекстів на Github. Ця рамка розроблена, щоб допомогти розробникам розгорнути серію QWEN2.5-1M більш економічно. Використовуючи такі методи, як екстраполяція довжини та розріджена увага, рамки можуть обробляти 1-мільйонні вхідні входи зі швидкістю 3-7 разів швидше, ніж традиційні підходи, пропонуючи потужне рішення для розробки додатків, які потребують обробки довгого контексту з більшою ефективністю.
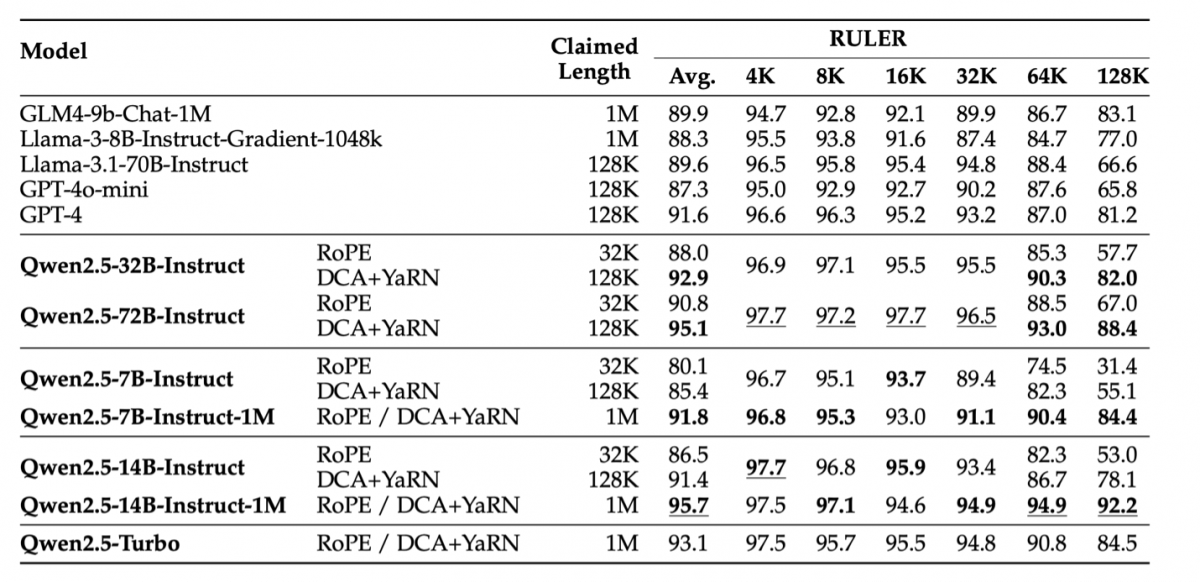
Серія QWEN2.5-1M продемонструвала вражаючі показники в орієнтирах, орієнтованих на можливості довгого контексту, таких як лінійка, LV-EVAL та Longbench-Chat. Ці чудові результати свідчать про те, що QWEN2.5-1M забезпечує надійну альтернативу відкритих кодів для завдань, що вимагають великих контекстних вкладень.
Порівняно зі своїм попередником, версією 128K, серія QWEN2,5-1M може значно підвищити можливості довгого контексту, досягнуті за допомогою передових стратегій у довгоконтекстному попередньому тренуванні та після тренування. Для підвищення ефективності довгого контексту застосовуються методи, такі як довгий синтез даних, прогресивна попередня підготовка та багатоступенева контрольована тонка настройка, при цьому ефективно зменшують витрати на навчання.