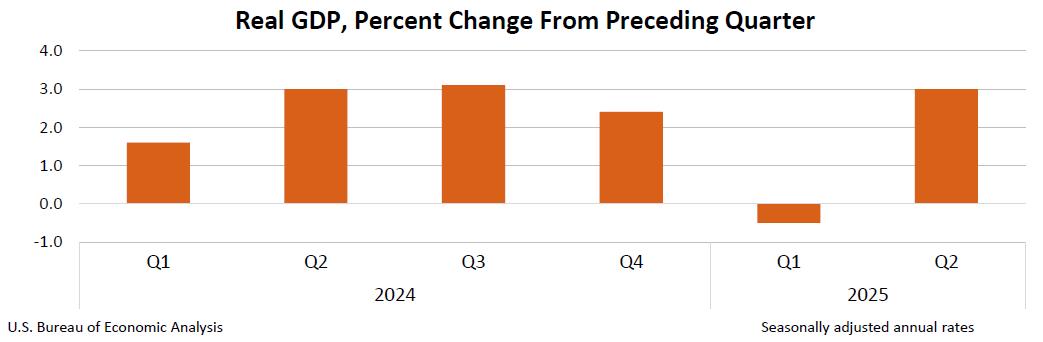
Справжній валовий внутрішній продукт (ВВП) У другому кварталі 2025 року (квітень, травень та червень) зросли щорічну ставку на 3,0 відсотка), згідно з попередньою оцінкою, опублікованою Бюро економічного аналізу США. У першому кварталі реальний ВВП зменшився на 0,5 відсотка.
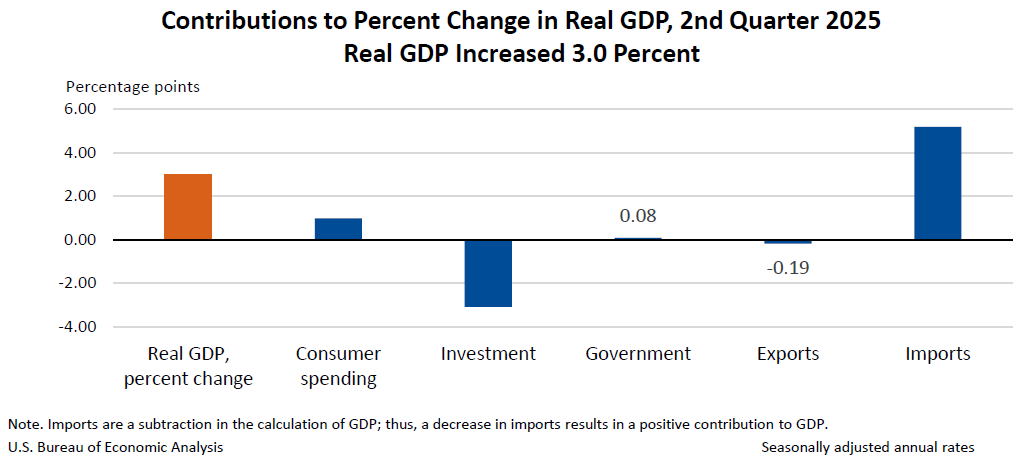
Збільшення реального ВВП у другому кварталі в першу чергу відображало зменшення імпорту, що є відніманням в обчисленні ВВП та збільшенням споживчих витрат. Ці рухи частково компенсували зменшення інвестицій та експорту. Для отримання додаткової інформації див. “Технічні примітки” нижче.
Порівняно з першою чверті, підняття в справжній ВВП У другому кварталі в першу чергу відобразив спад імпорту та прискорення споживчих витрат, які частково компенсувалися спаленням інвестицій.
Реальні остаточні продажі приватних вітчизняних покупцівСума споживчих витрат та валових приватних фіксованих інвестицій у другому кварталі збільшилася на 1,2 відсотка, порівняно зі збільшенням на 1,9 відсотка в першому кварталі.
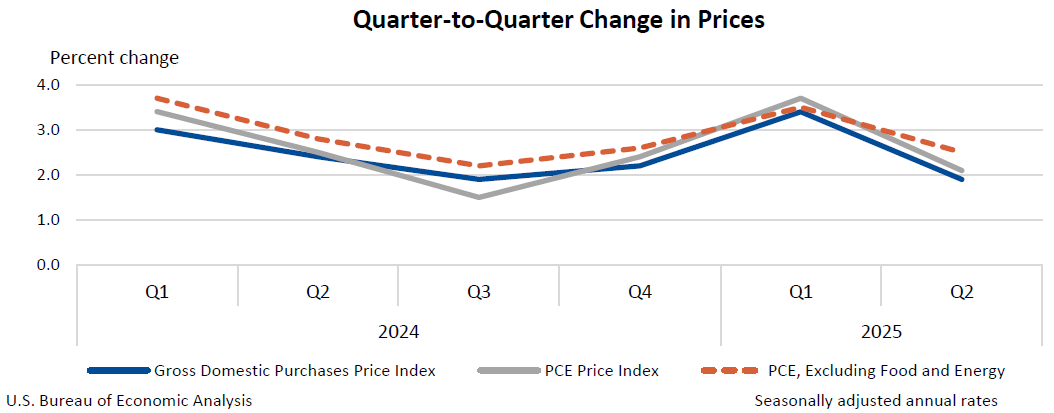
З Індекс цін для валових внутрішніх покупок У другому кварталі збільшився на 1,9 відсотка порівняно зі збільшенням на 3,4 відсотка в першому кварталі. З Витрати на особисте споживання (PCE) Індекс цін збільшився на 2,1 відсотка, порівняно зі збільшенням на 3,7 відсотка. За винятком цін на продукти харчування та енергії, індекс цін PCE збільшився на 2,5 відсотка, порівняно зі збільшенням на 3,5 відсотка.
Справжній ВВП та пов'язані з цим заходи (Відсоткова зміна з Q1 на Q2)
Попередня оцінка
Справжній ВВП
3,0
ВВП з поточним доларом
5,0
Реальні остаточні продажі приватних вітчизняних покупців
1.2
Валовий індекс цін на внутрішні покупки
1,9
Індекс цін PCE
2,1
Індекс цін PCE, виключаючи їжу та енергію
2,5
Наступний випуск: 28 серпня 2025 року о 8:30 ранку EDT Валовий внутрішній продукт (друга оцінка), Корпоративний прибуток (попередня оцінка), 2 -й чверть 2025
Технічні примітки
Джерела змін для реального ВВП
Реальний ВВП збільшувався з річною ставкою на 3,0 відсотка (0,7 відсотка за щоквартальною ставкою 1) у другому кварталі, в першу чергу, що відображає зменшення імпорту та збільшення споживчих витрат, які частково компенсували зменшення інвестицій та експорту.
Експорт та імпорт в першу чергу відображають Бюро перепису Бюро Бюро США міжнародної торгівлі товарами та послугами, а також звіту про попередні економічні показники Бюро перепису на червень.
У рамках імпорту зменшення в першу чергу відображало зменшення товарів на чолі з непридатними товарами споживачів, за винятком продуктів харчування та автомобільних (переважно лікарських, стоматологічних та фармацевтичних препаратів, включаючи вітаміни).
У межах експорту зменшення в основному відображало зменшення товарів на чолі з автомобільними транспортними засобами, двигунами та деталями.
Зростання споживчих витрат відображало збільшення як послуг, так і товарів. У рамках послуг провідними учасниками були охорона здоров'я, продовольчі послуги та проживання, фінансові послуги та страхування. У межах товарів провідними учасниками були автотранспортні засоби та деталі та інші непридатні товари.
У рамках охорони здоров’я зросли як амбулаторні послуги, так і лікарняні та престанічні послуги, засновані в основному на Бюро статистики праці (BLS) Поточна статистика зайнятості (CES), дані про зайнятість, заробітки та години.
Зростання послуг продовольства та проживання направляли продовольчі послуги, засновані на Бюро перепису щомісяця роздрібної торгівлі
Зростання фінансових послуг та страхування керувало послугами управління портфелем та інвестиційними консультаційними послугами.
Збільшення автомобільних транспортних засобів та деталей очолювали нові легкі вантажівки, що базуються в основному на даних про реєстрації IHS-Polk.
Збільшення інших непомірних товарів керувало фармацевтичними продуктами на основі даних MRTS.
Найбільшим фактором зменшення інвестицій були приватні інвестиції в інвентаризацію, що очолює зменшення виробництва непридатних товарів (головним чином, хімічне виробництво) та оптової торгівлі (що відображає широке зменшення промисловості товарів, що тривають). Оцінки приватних інвестицій інвентаризації базувалися насамперед на даних про перепис Бюро інвентаризації вартості та коригування BEA для врахування помітного збільшення імпорту в першому кварталі та зменшуються у другому кварталі.
Більше інформації про вихідні дані та припущення BEA, які лежать в основі оцінки другого кварталу, показано в таблиці ключових джерел даних та припущень.
1 Зміни відсотків у щоквартальних сезонних серіях відображаються за річними тарифами, якщо не вказано інше. Для отримання додаткової інформації зверніться до FAQ, чому BEA публікує відсотки змін у щоквартальних серіях за річними тарифами?.
Для оцінки зручності використання та універсальності трубопроводу SCSparkl ми реалізували три загальнодоступні одноклітинні набори даних RNA-SEQ, кожен з яких представляє чіткий біологічний контекст та структуру даних:
Немієлоїдні клітини миші мозок
Цей набір даних є частиною складу Tabula muris senis, який профілює одноклітинні транскриптоми у 20 тканинах від Mus musculus, що містить приблизно 100 000 клітин загалом23. Для нашого аналізу ми витягнули підмножину немієлоїдних клітин мозку, що включає 3,401 клітин з вимірюваннями експресії генів для 23 433 генів. Супровідні метадані надають детальні анотації, такі як суб тканинного походження (кора, гіпокамп, мозочок та стриатум), онтологічні класифікації клітин, ідентифікатор миші та стать.
Клітинна суміш Jurkat-293T
Цей набір даних, спочатку опублікований24містить 3,388 клітин, отриманих із суміші in vitro 1: 1 людських 293 Т та клітинних ліній миші Юркат. Набір даних був розроблений для розмежування профілів експресії, характерних для видів. Клітини, що експресують CD3D, були класифіковані як Юркат, тоді як ті, що виражають XIST, були ідентифіковані як 293T. Цей набір даних служить чітким орієнтиром для оцінки міжвидового розділення та точності кластеризації.
68 K PBMC
Для оцінки продуктивності трубопроводу на великих наборах даних та оцінки масштабованості виконання, ми використовували набір даних мононуклеарної клітини периферичної крові 68 К24 Набір даних складається з одноклітинних транскриптомічних профілів, зібраних від здорового донора, що охоплює неоднорідну популяцію імунних клітин. Цей набір даних був використаний для генерації випадкових підпрограм збільшення розмірів (від 2 К до 10 К.
Розробка трубопроводу
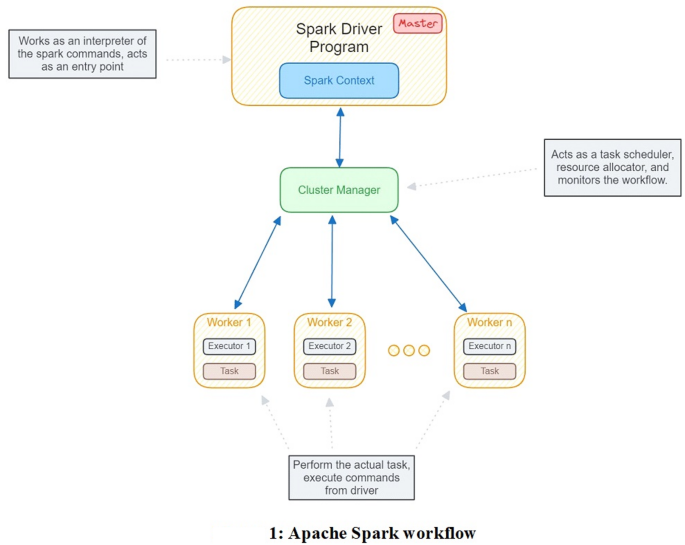
Для розробки ми використовували Spark Version 3.1.2, Python 3.9 та JDK версії 8.0. Apache Spark – це розподілений аналітичний двигун, зроблений для обробки великих даних. Він забезпечує основну платформу паралельної обробки для великих наборів даних25. Іскра в основі використовує абстракцію під назвою стійкі розподілені набори даних (RDD), колекція об'єктів, що розподіляється лише через кластер машин, яку можна відтворити, якщо одна з машин втрачена-толерантність12. Усі завдання запускаються паралельно за допомогою програми під назвою “Програма драйверів”, яка також підтримує високий рівень контролю над програмами та роботами, поданими виконавцям (рис. 1). Spark використовує концепцію пам’яті, тобто, вона використовує пам’ять випадкового доступу (оперативної пам’яті) машини та приносить дані, що обробляються безпосередньо до оперативної пам’яті25.
Рис. 1
Apache Spark Workflow. Програма Spark Driver працює як майстер і як вхідна точка для всіх робочих місць Spark. Майстер подає роботу до вузлів робітників. Менеджер кластерів веде трек вузлів, а завдання розподіляються їм, кілька менеджерів кластерів – це ще один переговорник ресурсів (пряжа), кубернетти, мезо та окремі (у нашому випадку). Робітник/рабські вузли – це фактичні машини, де виконуються завдання, і вони повідомляють перед менеджером кластерів.
Трубопровід SCSparkl складається з 3 етапів, алгоритмів для всіх трьох етапів (псевдокод 1, 2 та 3) були розроблені таким чином, що нормальне обладнання для товару підтримуватиме аналіз, і можлива оптимізація іскри. Етапи мають модульний характер, що підтримує різноманітність аналізу. Для глибокого розуміння того, як працюють етапи внутрішньо, ми розробили схему потоку даних (DFD) для кожної стадії (додаткова секта 1).
Преоціація стадії-1
Для завантаження даних та фільтрації даних було розроблено два ексклюзивні модулі Spark. Файл пакету data_load.py завантажує дані як Spark Dataframe і виконує початкову попередню обробку, як видалення спеціальних символів, таких як періоди (.), Comma (,), порожні пробіли тощо, зі стовпців та замінює їх на підкреслення ('_'). Дані SCRNA-SEQ зазвичай знаходяться у широкому форматі, а Spark має можливість краще працювати з даними високого/довгого формату; Отже, для оптимізації ми переробляємо дані у високий формат за допомогою melt_spark () Функція в трубопроводі, тим самим зменшуючи стовпне навантаження та підвищуючи ефективність. Цей крок є важливим для користувачів з низькими машинами пам'яті (тобто, як мінімуми, як 4 Гб). Потім дані даних записуються як іскровий паркетний файл. Формат Apache Parquet-це формат файлу зберігання стовпців з відкритим кодом, який базується на “Алгоритмі подрібнення та складання”. Він призначений для обробки великих і складних наборів даних для більш швидких функцій агрегації. Файл, форматований паркет, стискається, що прискорює подальші аналітичні процедури у файлі. В основному ми використовуємо агрегатні функції Apache Sparks, відомі своїм швидким пошуком і менш обчислювально вичерпними/дорогими. Pseudocode-1 надає детальний контур очищення та переробку даних.
Контроль якості етапу-2
Для когерентного та точного аналізу даних SCRNA-SEQ необхідно фільтрувати клітини та гени низької якості. Ми стежили за пакетом “Scater”9Сканпі14 і Сеурат13 Для генерування різноманітних матриць контролю якості. Матриця якості обчислюється за кількістю таких параметрів, як загальні гени, виражені на клітинку, відсоток консорціуму зовнішнього РНК -контролю (ERCC), численні клітини, що експресують гени, що перевищують нуль, мітохондріальний відсоток, виявлений у кожній комірці тощо.
тоді То1 і То2 Позначають якість клітин та підсумки якості генів відповідно, можна навести наступні в Таблицях 1 та 2.
Таблиця 1 То1 Резюме та формули для якості клітин.
Таблиця 2 То2 Резюме та формули для якості генів.
На додаток до нормальних процедур фільтрації, ми реалізували методологію фільтрації середнього рівня абсолютного відхилення (MAD) для фільтрації генів із нормалізованим значенням підрахунку, що перевищує вирішений поріг (зазвичай> 3). Pseudocode-2 окреслює загальну процедуру обчислення вимірювань якості клітин та генів, тоді як Pseudocode-3 окреслює процес фільтрації на основі цих резюме якості разом із наступними етапами нормалізації, зменшенням розмірності та кластеризацією, які детально описані в наступних розділах.
Стадія 3 Нормалізація та зменшення розмірності
Через властиву розрідженості та мінливості одноклітинних даних RNA-SEQ (SCRNA-SEQ) нормалізація є критичним кроком попередньої обробки, щоб забезпечити, щоб аналізи вниз за течією відображали справжні біологічні сигнали, а не на технічний шум. Правильна нормалізація покращує порівнянність експресії генів у клітинах і підвищує точність кластеризації, зменшення розмірності та диференціальний аналіз експресії. З data_normalize.py Модуль в рамках SCSPARKL в даний час підтримує два методи нормалізації: квантильна нормалізація (QN) та глобальна нормалізація (GN).
У QN значення експресії генів по всій клітині вперше класифікуються від найнижчого до найвищого, дані розташовані відповідно до рядків рядків. У всіх клітинах значення в одному ранзі усереднюються для формування нового еталонного розподілу. Потім ці середні значення відображаються назад до кожної комірки відповідно до початкового порядку. Цей метод допомагає стандартизувати розподіл експресії по клітинах, зберігаючи відносні відносини експресії всередині кожної клітини. Це особливо корисно для того, щоб зробити набори даних з різними масштабами виразів більш порівнянними.
Глобальна нормалізація, з іншого, регулює загальний вираз кожної клітини до фіксованої шкали (наприклад, підраховується на 10 000), а потім трансформація журналу. Цей підхід виправляє відмінності в глибині секвенування і зазвичай використовується в стандартних робочих процесах SCRNA-Seq. У цьому ми ділимо кожне значення експресії клітини на загальну кількість кількості гена. Потім отримане значення помножується на 10 000 і перетворюється журнал з додаванням псевдо-вартості 1. Математично, якщо \ (\: {X} _ {n*m} \) являє собою ненормалізована відфільтрована матриця SCRNA-Seq, а потім нормалізована матриця \ (\: {X} _ {n} \) можна дати як:
Обидві стратегії нормалізації інтегровані в іскровий трубопровід для підтримки паралельного виконання та ефективної обробки масштабних наборів даних.
Зменшення розмірності
Зниження розмірності є ключовим кроком в аналізі SCRNA-Seq, спрямованого на проектування високовимірних даних експресії генів у нижньовимірний простір, зберігаючи основну структуру та взаємозв'язки між клітинами26. Через високу розмірність та розрідженість даних SCRNA-seq, звичайні методи аналізу можуть впливати на «прокляття розмірності»-явище, де відстань між точками даних стає менш значущим у високомірних просторах27.
У цьому дослідженні ми використовували три широко використовувані методи зменшення розмірності: аналіз основних компонентів (PCA), Т-розподілене стохастичне вбудовування сусіда (T-SNE) та рівномірне наближення та проекцію (UMAP). Серед них PCA реалізується за допомогою бібліотеки MLLIB Spark, що дозволяє розподілити та паралельні обчислення через вузли. Ця інтеграція узгоджується з проектними цілями SCSparkl для підтримки масштабованого, високопропускного аналізу.
Навпаки, UMAP та T-SNE в даний час реалізуються за допомогою стандартних бібліотек Python та працюють поза двигуном виконання іскри. Тим не менш, ці методи читають вхід безпосередньо з проміжних файлів Apache Parquet, що виграють від ефективного вводу/виводу та сумісності з іскровими випусками. Незважаючи на те, що ці кроки не повністю паралельовані в іскрі, їх інтеграція в трубопровід залишається безшовною і підтримує візуалізацію та кластеризацію робочих процесів.
Кластеризація та подальший аналіз за течією
Основна перевага одноклітинної секвенування РНК (SCRNA-Seq) полягає в його здатності ідентифікувати як відомі, так і нові популяції клітин за допомогою непідконтрольної кластеризації28. По мірі того, як технології одноклітинних профілювання продовжують розвиватися, поліпшення ефективності захоплення дозволило послідовності мільйонів окремих клітин, що спричиняє все більш великі та складні набори даних. Ця шкала накладає значні обчислювальні вимоги до алгоритмів кластеризації, що використовуються для виявлення та класифікації типу клітин29.
Щоб вирішити це, SCSparkl інтегрує алгоритм кластеризації k-means, який розділяє набір даних N спостережень k кластери (k ≤ n) шляхом мінімізації дисперсії в межах кластера. Алгоритм працює ітеративно, спочатку шляхом випадкового вибору k -центроїд, а потім присвоюючи кожну точку даних найближчому центроїд. Цей процес триває до конвергенції, що призводить до компактних та добре розбитого кластерів.
Для підтримки усвідомленого відбору kТрубопровід включає як метод лікоть, так і аналіз балів силуетів, що дозволяє користувачам оцінювати стабільність та розділення кластеризації. Після визначення кластерів диференціальний аналіз експресії генів (DGE) проводиться для виявлення генів, які найбільш виразно експресуються між групами. Для цього ми застосовуємо двопробний t-тест у кластерах і класифікуємо 10 значущих генів на основі їх p-значень, забезпечуючи інтерпретаційний набір маркерних генів для біологічної перевірки нижче за течією.
Новий договір про трансформаційні дослідження, щоб визначити, як менопауза та модифікуючі фактори способу життя впливають на старіння мозку у жінок під час середнього віку, було присвоєно Неда Джаханшад, доктор наук.Стівенс це) та доцент кафедри неврології в Медичній школі Кека в Медиці USC. Джаханшад приєднується до глобальної допомоги (Розрізання ризику Альцгеймера за допомогою ендокринології) Програма від Wellcome Leap, провідної некомерційної організації, що базується в США, орієнтована на прискорення та збільшення кількості проривів у глобальному здоров’ї. Разом з Клаудією Барт, доктор наук, професор, Харіте, Університеттседізін Берлін, Німеччина, як співвинацький слідчий, Джаханшад буде частиною команди, що веде новаторський трирічний проект, який може призвести до розуміння того, як зменшити ризик когнітивного занепаду у віці жінок.
Хвороба Альцгеймера та пов'язані з цим деменції (АДРД) непропорційно впливають на жінок, але багато залишається невідомим про те, як змінюється жіночий мозок під час середнього віку – критичне вікно, яке збігається з переходом менопаузи. До 80% жінок відчувають виснажливі симптоми в цей період, включаючи гарячі спалахи, порушення сну, зрушення настрою та когнітивне зниження. Проект Джаханшада прагне використати передові візуалізації мозку та масштабні міжнародні дані для виявлення ранніх показників неврологічного старіння та пропонують індивідуальні втручання для здоров'я мозку.
Неда Джаханшад, доктор наук. Фото/stevens ini
“Здоров'я жіночого мозку залишається однією з найбільш недостатньо досліджених областей нейронауки”,-сказав Джаханшад. “За допомогою цього договору ми маємо можливість намітити, як розвивається мозок через середнє життя у жінок, і визначити, які конкретні втручання можуть змістовно знизити ризик деменції на індивідуальному рівні”.
Проект під назвою Графік жіночого мозку під час середнього вікубуде об'єднати дані тисяч жінок у всьому світі через Enigma (Підвищення генетики нейро-візуалізації за допомогою метааналізу) Консорціум, глобальна дослідницька мережа, яку керував Джаханшад. Дослідження буде проаналізувати МРТ -сканування та дані про здоров'я для відстеження змін у структурі мозку, зв’язку та тканинній мікроструктурі під час переходу менопаузи.
“Наше поєднання великих видобутків даних та найсучасніших методів дозволить краще зрозуміти фактори ризику та стійкості, які формують здоров'я жінок у середньому віці. Такі знання є важливими для забезпечення цілеспрямованих втручань для покращення здоров'я жінок протягом цього перехідного періоду”,-сказав Барт.
Ключові цілі включають:
Картографування того, як менопауза, гормональна замісна терапія (ЗГТ) та симптоми, пов'язані з менопаузою, впливають на схему мозку.
Використання AI для розробки персоналізованих моделей «цифрового близнюка», які прогнозують, як мозок жінки може старіти за різними сценаріями здоров'я та способу життя.
Застосування аналізів, щоб визначити, які модифіковані фактори – як дієта, фізичні вправи чи сон – мають найсильніший захисний вплив на старіння мозку та коли втручання, ймовірно, будуть найбільш ефективними.
Робота Джаханшаду та Барта ґрунтується на успіху попередніх досліджень Enigma, які об'єднали глобальні дані для виявлення надійних біомаркерів мозку для неврологічних та психіатричних розладів. Ці нові зусилля нададуть пріоритет включенню різноманітного населення, забезпечуючи результати широко репрезентативними.
“Це дослідження має потенціал для перетворення того, як ми розуміємо та підтримуємо жіноче здоров'я мозку”, – сказав Артур В. Тога, доктор наук, директор Інституту нейровізуалізації Стівенса та інформатики. “Прозорливий лідерство доктора Джаханшада та спільна робота допоможуть закрити критичну розрив у нейронауці”.
Ініціатива догляду за Leap Wellcome підтримує трансформаційні рішення, що покращують здоров'я мозку протягом усього життя, особливо у популяціях, які історично не помічаються. За допомогою цього договору Stevens INI продовжує своє лідерство в картографуванні мозку, нейровізуалізації та точних досліджень охорони здоров'я.
Щоб дізнатися більше про програму догляду, відвідайте https://wellcomeap.org/care/.
До лише декількох років тому ВВС США все ще покладалися здебільшого на антивірусні інструменти на основі підписів для захисту кінцевих точок. Але чиновники зрозуміли, що необхідний більш досконалий підхід, щоб захистити дані та системи від хакерів та противників.
“Інструменти просто не йшли в ногу”, – каже CTO ВВС Скотт Хайтман. “Ми хотіли мати більше поглиблених сигналів. Ми хотіли переконатися, що ми консолідуємо всі ці вклади, і що ми використовуємо штучний інтелект та машинне навчання для нашої переваги рішення”.
З тих пір ВВС перейшла на платформу, яка замінює виявлення на основі підпису на аналіз поведінки в кінцевих точках, мережах та хмарних системах. Агентства по всьому уряду переїхали в останні роки, щоб прийняти інструменти захисту від кінцевої точки та управління, які використовують машинне навчання, щоб виявити ненормальну поведінку, автоматизувати реагування на загрозу та зменшити навантаження на людських аналітиків.
Клацніть на банер нижче Почати реалізацію розумнішої безпеки.
Метт Хейден, віце -президент з кібер та нових загроз у інформаційних технологіях General Dynamics, раніше працював у федеральних ролях кібербезпеки – останнім часом на посаді помічника секретаря кібер, інфраструктури, ризику та стійкості у відділі внутрішньої безпеки – і наголошує на тому, що кінцеві точки є критичним компонентом у загальній стратегії кібербезпеки агентств, особливо як нападники використовують AI, щоб запустити більш високу фірму, що випускає фірму.
“Перше, що має зробити кожне агентство, щоб бути відповідальним захисником мереж,-це пройти низьковигаючий фруктовий шлях від нападників”,-говорить Хейден. “Це включає моніторинг ноутбуків та мобільних пристроїв. Саме ті кінцеві точки користувачі вкладають свої облікові дані. Ефективне виявлення кінцевих точок автоматично виявляє загрози і блокує їх на всьому вашому підприємстві. Основою сучасної оборони є зафіксування цих кінцевих точок з самого початку”.
ML-це обов'язково для виявлення ворожої поведінки
Боб Гурлі, співзасновник та CTO консультації з кібербезпеки Ooda та колишнього CTO в Агентстві оборонної розвідки, каже, що урядові лідери кібербезпеки визнали необхідність у можливостях AI та ML в безпеці кінцевих точок ще в 1990-х роках, але перші ефективні інструменти не прийшли на ринок приблизно до десятиліття тому.
“Тоді, за останні п’ять років, відбувся щойно вибух, і всі великі гравці зараз використовують машинне навчання в обороні кінцевої точки”, – говорить Гурлі. “Microsoft Defender чудово в цьому.
“Якщо ви хочете мати будь -яку надію пом'якшити шкідливий код і виявити змагальні дії”, – додає він, “ви повинні мати рішення машинного навчання”.
Переваги інструментів ML виходять за рамки простого виявлення, каже Хейден. “Зазвичай не існує професіонал з кібербезпеки, який дивиться на кожен інцидент, який виявляє кінцева точка, в той час, коли він його виявляє”, – говорить він. “Існує набір правил, і саме тут ML починає написати додаткове сценарій. Інструмент починає вживати дії від вашого імені для розслідування”.
Heitmann зазначає, що інструменти безпеки кінцевої точки ВВС автоматично карантину та підозрілі вкладення електронної пошти та посилання. “Це все робиться зі швидкістю потреби, перш ніж користувач коли -небудь отримає шанс отримати доступ до файлу”, – говорить він.
Дізнайтеся більше: Як військові використовують мультифакторну автентифікацію в цій галузі.
ML ловлять погрози, які інші інструменти пропускають
Після прийняття інструментів ML, команда кібербезпеки ВВС зараз автоматично закриває близько 1500 квитків, говорить Хайтман. “Це було від 30 хвилин до години, щоб наші люди витрачали на кожен з цих квитків”, – зазначає він. “Ми повертаємо час авіаперевезцям, щоб зосередитись на можливостях нового покоління”.
Протягом останніх шести місяців, зазначає Хайтман, інструменти допомогли ВВС зловити два екземпляри завантажувальних навантажувачів, які зловмисники можуть використовувати для завантаження шкідливих додатків дуже рано в процесі запуску системи, надаючи їм привілейований доступ до того, як інструменти безпеки навіть зможуть активувати.
“Вам було б важко знайти завантажувач через інструмент на основі підписів, оскільки це не зловмисне програмне забезпечення”,-говорить Хайтман. “Але інструменти ML бачать файли в системі, що знаходяться поза нормою, і вони можуть виявити схему поведінки.”
Незважаючи на те, що деякі автоматизовані інструменти кібербезпеки здобули репутацію переважних організацій з помилковими тривожними сигналами, Хейден каже, що в даний час не є великою проблемою для інструментів безпеки кінцевої точки, що працюють на ML.
“Чим більше інформації у вас є, тим краще і навіть помилкові тривоги можуть вдосконалювати алгоритми, що використовуються для підтримки оркестрації та автоматизації”, – говорить він. “У 2018 та 2019 роках у вас було багато скарг на те, що люди не могли фільтрувати шум, щоб знати, що було реально, а що не було; зараз інструменти розроблені для отримання всієї цієї інформації та для того, щоб допомогти організаціям пріоритетність”.
Вибір правильного ML для свого агентства
Поки існує рух на централізацію федеральної закупівлі рішень з кібербезпеки, Гурлі каже, що агенції сьогодні все ще мають “великий голос”, якими інструментами вони використовують.
Trellix, платформа, яка використовує вдосконалений ML та AI, щоб забезпечити багатошарову захист кінцевих точок у локальних та хмарних умовах, може похвалитися тим, що його рішення використовуються у всіх трьох відділеннях влади, усіх агентств на рівні кабінету та всіх агентств оборони. Державний департамент США покладається на Tanium AEM, автономне управління кінцевими точками, що включає в себе ML та AI Insights. А в березні Федеральна адміністрація авіації придбала Enterprise Edition Fusion5, яке приносить ML, пошук природних мов та віртуальні помічники до управління кінцевою точкою.
Окрім ціни, лідери агентства повинні враховувати надійність та сумісність при виборі продукту, говорить Гурлі. Реалізація розширених рішень щодо захисту кінцевих точок, як правило, не потребує великої підготовки, додає він, але зазначає, що працівники можуть переповнюватися, якщо агенції використовують кілька платформ одночасно.
Клацніть на банер нижче для останніх федеральних ІТ та кібербезпеки.
Люди можуть навіть не усвідомлювати, що певні інструменти безпеки були придбані або включені до угод про ліцензування підприємств. “Люди змінюють роботу, або іноді вони не зовсім знають, що було придбано”, – каже він. “Поінформованість може бути дуже нерівномірною”.
Хайтман зазначає, що всі агенції перебувають у гонці, щоб загрожувати, як тільки будуть запущені напади, а інструменти безпеки кінцевої точки на основі ML допомагають їм “закрити цю петлю швидше і швидше”.
“Ми постійно налаштовуємось на основі тактики наших супротивників, а потім вони налаштовують свою тактику у відповідь”, – говорить Хайтман. “Це буксир війни, білий капелюх проти чорного капелюха. Деякі дні вони збираються наблизитися, і деякі дні ми будемо на вершині. Машинне навчання допомагає нам отримати цю перевагу”.
Red Hat, провідний постачальник рішень з відкритим кодом, оголосив Red Hat Enterprise Linux для розробників бізнесу, щоб спростити доступ до провідної платформи підприємства Linux для сценаріїв розробки та тестування, орієнтованих на бізнес.
Нова пропозиція самообслуговування через програму розробників Red Hat, Red Hat Enterprise Linux для розробників бізнесу допомагає командам розвитку бізнесу будувати, тестувати та перевіряти додатки швидше та на тій же платформі, що лежить в основі виробничих систем у гібридній хмарі безкоштовно.
Red Hat Enterprise Linux для розробників бізнесу надає розробникам самообслуговування, без коштів до повного набору підприємства, готового для підприємства, вмісту Red Hat Enterprise Linux для використання в їхньому бізнесі.
Це допомагає забезпечити більшу узгодженість та надійність у командах розробників та операцій, незалежно від того, де на гібридній хмарі буде проживати отримана програма, повідомляє компанія.
Користувачі Red Hat Enterprise Linux для розробників бізнесу зможуть придбати різноманітні підписки на підтримку розробників Red Hat, що приносить десятиліття експертизи Linux Red Hat, щоб підтримати свої проекти.
Розробники, які працюють поза традиційним ІТ, наприклад, у бізнесі, тепер можуть легше отримати доступ до Red Hat Enterprise Linux, щоб розпочати розробку нових проектів.
Ці розробники також можуть будувати та тестувати на тій же платформі, яка затверджена для виробництва, що полегшує перехід додатків до виробництва, зменшуючи тертя між командами.
Це нове рішення доповнює існуючі пропозиції розробників, включаючи підписку на розробника Red Hat для людей, яка включає всі пропозиції Red Hat та призначене для особистого використання.
Крім того, підписка на розробників Red Hat Enterprise Linux для команд, яка включає повний набір вмісту Red Hat Enterprise Linux, готовий до підприємства, і доступний для великих підприємств через представника або партнера.
Red Hat Enterprise Linux для розробників бізнесу тепер загалом доступний.
“Сучасні розробники повинні мати можливість рухатися власними темпами, щоб доставляти інноваційні додатки, але повинні робити це, не збільшуючи тертя з ІТ-операційними командами або виробничими системами. Віце -президент і генеральний менеджер Red Hat Enterprise Linux, Red Hat.
Для отримання додаткової інформації про цю новину відвідайте www.redhat.com.
У Q2 програма Semi International Standards досягла прогресу в кількох нових ініціативах. Разом ми досягли критичної віхи для однієї з наших ініціатив стандартів даних з документом 6938C, що нещодавно проходив огляд технічного комітету в середині червня 2025 р. Виборчий бюлетень 6938c, який надає рекомендації щодо визначення даних виробничого обладнання, наданих постачальником обладнання, які можуть бути використані в інженерії обладнання або надання галузі, що надає галузь-семінізацію.
Крім того, ми розпочали великі зміни до напів стандартів S2, S8 та S10. Ці стандарти регулюють міркування щодо навколишнього середовища, охорони здоров'я та безпеки (EHS), втоми користувача та зменшення травм, а також оцінка та оцінка ризику обладнання відповідно. У наших нещодавно завершених стандартах Північної Америки влітку 2025 р. Глава технічного комітету NA EHS затвердив виборчий бюлетень для Semi S10. БЮЛЕТ (7169) запропонував декілька основних переглядів керівництва Semi S10 щодо оцінки ризику, що включало зміни до посилань на обладнання на об'єкти, що розглядаються. Інші зміни також включали переселення оцінки ризику заподіяння шкоди власності, крім OUC, до відповідного розділу інформації. Нижче наведено додаткові деталі.
Ми з нетерпінням готуємось до цьогорічного заходу Semicon West, що відбулося вперше у Феніксі, штат Арізона. Ми також раді оголосити про повернення саміту на напівглобальні стандарти, що відбудеться у вівторок вдень, 7 жовтня на Semicon West. Наш вступний саміт відбувся минулого року в Semicon Japan 2024 минулого грудня. Саміт має на меті визначити критичні стандарти та працювати над стратегією галузевої стандартизації для наступних 3- та 7-річних часових горизонтів. Цьогорічний глобальний саміт стандартів демонструватиме сесії щодо відстеження ланцюгів поставок, а також екологічної стійкості. Аналогічно, коли міркування кібербезпеки стають складнішими, Semicon West прийматиме спеціальний форум з кібербезпеки з 7-9 жовтня для вирішення найбільш актуальних проблем сьогодні. Незабаром буде доступна більш детальна інформація про програму.
Нарешті, ми з нетерпінням чекаємо нашого напів стандарти + церемонія нагородження в мережевому заході на Semicon West. Слідом за міжнародними стандартами та стандартами саміту у вівторок, 7 жовтня, приєднуйтесь до нас за закусками, напоями та чудовою розмовою від 6-7: 30 вечора
Тим часом дізнайтеся більше про те, щоб стати членом Програми напівнародних стандартів.
Важина для документа 6938
Документ 6938c представляє новий потенційний стандарт – Посібник з управління краями обладнання. Розробка робочою групою з управління даними Edge Edge (EEDG) З 2021 року, документ 6938C був облаштований у циклі 3-2025 та затверджено під час засідання глави Інформації та контролю Тайваню (TC), що відбулося 12 червня 2025 року. З тих пір він отримав схвалення Міжнародним комітетом з стандартів та оглядами підкомітету, і зараз проходить підсумку для публікації SEMI.
Оскільки виробниче обладнання пропонує більш доступні дані, ніж будь -коли, погана комунікація, непослідовні очікування та проблеми безпеки даних продовжують зупиняти або сповільнювати зусилля з інтеграції заводської роботи. Якщо він пройде, цей новий стандарт допоможе організувати інформацію, яка підтримує розумні виготовлення на межі. Крім того, посібник EEDG забезпечить комплексний набір найкращих практик як для користувачів, так і для постачальників для збільшення вартості існуючих даних обладнання.
ОНОВЛЕННЯ ПРО РОЗВИТКУ НА ПОПЕРЕДЖЕННЯ СПІЛЬНІСТЬ S2, S8 та S10
Наші стандарти Q1 2025 року спостерігають, як бюлетень оголосив про значний капітальний ремонт для напівспортових стандартів S2, S8 та S10.
S2, Standard Semi для ефективності на основі ефективності навколишнього середовища, охорони навколишнього середовища та безпеки (EHS) для напівпровідникового виробничого обладнання, проводить дискусії щодо переосмислення систем блокування безпеки. Спеціальна група S2 видасть неформальний бюлетень загальній аудиторії для відгуків. Тоді результати будуть використані для розробки офіційного бюлетеня.
Вперше розроблений у 1995 році, Seart Standard S8 працює над зменшенням втоми та травм, узгоджуючи обладнання до розміру, міцності та діапазону руху користувача. Незважаючи на те, що цей стандарт безпеки періодично оновлювався з моменту створення, його останній істотний перегляд був у 2018 році.
В бюлетень для перегляду S8 в кінцевому підсумку не вдалося огляд глави EH&S TC на цьогорічній зимовій зустрічі. З 214 коментарями та негативами, які слід врахувати, цикл -група переглядає голосування і планує перевидати в циклі 7 серпня 2025 року.
Нарешті, Semi Standard S10 рухається через бюлетень 7169. Цей стандарт визначає послідовний засіб оцінки ризику, на які можуть викликати інші вказівки з безпеки. БЮЛЕТ 7169 відокремлює оцінку об'єкта та будівництва ризику на ненормативну частину документа, забезпечують, щоб ризики EHS окремо обчислювались від комерційних об'єктних ризиків та уточнюють оцінку ризику спостережуваних подій від оцінки ризику передбачених подій.
Результати голосування 7169 були переглянуті 5 червня під час літніх зустрічей стандартів Північної Америки. Документ був затверджений і обробляється для публікації SEMI.
Форум кібербезпеки на Semicon West 2025
Цьогорічний Semicon West демонструє спеціальний форум з кібербезпеки для вирішення швидко змінюваного ландшафту кібербезпеки напівпровідникової галузі.
Форум кібербезпеки напівбезпеки зібрать експертів галузі, щоб ділитися знаннями та досвідом на наступні теми. Мета полягає в розробці діючих стратегій та глибшого розуміння поточних та майбутніх ризиків кібербезпеки.
Кібербезпека в застарілі напівпровідникові інструменти
Законодавство про кібербезпеку та існуючі
Кібербезпека в технічному обслуговуванні та виробництві
Вплив подій кібербезпеки на напівпровідникові виробничі операції
Безпека ланцюгів поставок
Загроза ландшафт у виробництві напівпровідників
Заклик 2025 р. Зараз закриті. Доповідачі будуть оголошені в Q3.
БІЛЬКА ПЕРЕГЛЯДУВАННЯ НАВЧАЛЬНОСТІ E187
Консорціум з кібербезпеки напівпровідника (SMCC) у співпраці з експертами з галузевих експертів із задоволенням оголошує про випуск Nemi E187 керівництва відповідності. Цей вичерпний ресурс призначений для підтримки постачальників напівпровідникового обладнання та виробників пристроїв, коли вони працюють над вимогами стандарту напів E187 0122 – специфікації кібербезпеки обладнання FAB.
Професіонали, які беруть участь у розробці інструментів, виробництві, операціях та безпеці, вважатимуть керівництво особливо актуальним та діючим. Він надає рекомендації щодо вирішення всіх дванадцяти вимог до напів E187 та зосередженості на новому обладнанні Fab.
Завантажте Whitepaper безкоштовно
Напів стандарти Літні зустрічі Північної Америки
Цьогорічні напів-стандарти Літні зустрічі Північної Америки відбулися з 2-5 червня у штаб-квартирі Semi в Мілпітасі, Каліфорнія. Зустрічі скликали 11 комітетів та 40 цільових груп для обговорення тем, починаючи від EHS до об'єктів, 3D -упаковки, MEMS тощо. Окрім результатів бюлетеня 7169, технічні зміни до бюлетеня 6601b, Новий стандарт: Посібник для зустрічі з ІРД -рекомендаціями таблиці таблиці для полімерних матеріалів та компонентів високої чистотитакож був затверджений главою TC TC TC TC TC, оскільки діяльність розпочалася в 2019 році. Ратифікаційне бюлетень буде видано в циклі 7-2025 для перевірки змін. Загалом, понад 15 заходів, починаючи від допоміжної інформації, повторних вимог та виборчих бюлетенів, також нещодавно пройшли процедурний огляд Комітетом Міжнародного стандартів (ISC) підкомітету з аудитів та оглядів та будуть передані в публікації для остаточної обробки.
Наступна зустріч із міжнародними стандартами відбудеться на Semicon West з 7-9 жовтня в Конгрес-центрі Фенікса. Деякі технічні комітети та цільові групи можуть відповідати практично поза цим набором зустрічей, тому обов'язково перевіряйте календар подій напів стандартів для оновлень.
Стандарти, представлені в Q2 2025
Нові та переглянуті стандарти, випущені у Q2.
Квітень 2025 р. Стандарти: https://store-us.semi.org/collections/standards/stdpbc-0425 Травень 2025 р. Стандарти: https://store-us.semi.org/collections/standards/stdpbc-0525 Червень 2025 р. Стандарти: https://store-us.semi.org/collections/standards/stdpbc-0625
Залучити
Заходи з розробки напів стандартів проводяться протягом року у всіх основних виробничих регіонах. Для участі приєднуйтесь до програми Semi International Standards.
Напів стандарти доступні за допомогою індивідуальних покупок для завантаження або в Інтернеті через напіввигуки. Зареєструйтесь на 30-денному випробуванні на напіввигуни.
Для отримання додаткової інформації відвідайте веб -сайт стандартів та сторінку подій. З будь -якими питаннями щодо заходів з напів -стандартів, будь ласка, зв'яжіться з місцевими співробітниками напівдержавних стандартів.
Не кожна велика акція AI – це покупка після масового бігу на ринку биків.
Штучний інтелект (AI) став одним з найбільших розмов для підприємств за останні кілька років. Кількість S&P 500 Компанії, що згадують “AI” на своєму дзвінку заробітку, піднялися з менше 75 у 2022 році до 241 протягом першого кварталу, повідомляє Factset Insight.
Кілька компаній створили великий бізнес навколо попиту на штучний інтелект або інтегровані ШІ, щоб швидко розширити свої адресні ринки. Багато з цих компаній бачили, що ціни на акції зростають за останні кілька років.
Але не кожен високолітній акції AI варто купувати після масштабного підняття ціни. Аналітики на Уолл -стріт зіпсували двох найсильніших виконавців за останні кілька років. Зараз деякі аналітики бачать надзвичайні недоліки попереду.
Ось два акції AI, які могли б впасти протягом наступного року, за словами аналітиків на Уолл -стріт.
Джерело зображення: Зображення Getty.
1. Palantir Technologies (74% потенціал)
Palantir Technologies(Фунгер 2,59%) за останні кілька років був одним з найкращих акцій. З початку 2023 року ціна акцій піднялася на прицільні 2290%, і тепер вона торгується з ринковою обмеженням, що перевищує 350 мільярдів доларів, станом на це написання.
Але кілька аналітиків вважають, що акція піднялася занадто далеко, занадто швидко. Лише сім аналітиків, що охоплюють ставку акцій, це покупка або еквівалент. Сімнадцять кажуть, щоб його утримувати, а Палантір має чотири рейтинги продажу. Найнижча ціна на вулиці – RISHI Jaluria RISHI RISHI RISHI, яка має цінову ціну в розмірі 40 доларів на акції, що на 74% знизився від його поточної ціни.
Причиною низької цінової ціль не вистачає фінансових результатів. Палантір бачив, що його дохід значно зростає протягом останніх кількох років, оскільки він розширює свій адресний ринок через свою платформу штучного інтелекту або AIP. Нова платформа полегшує користувачам взаємодіяти з програмним забезпеченням Big Data та знайти корисну інформацію про бізнес та допомагати приймати рішення. Це розширило випадки використання для програмного забезпечення Palantir, тим більше, що підприємства генерують все більше даних. Як результат, комерційний дохід США в США швидко піднявся, включаючи збільшення на 71% у першому кварталі.
Більше того, Palantir виявив величезні операційні важелі. Замість того, щоб зосередитись на маркетингу та продажах, генеральний директор Алекс Карп поставив більшу частину робочої сили Палантіра на створення кращого продукту. Ідея – кращий продукт зробить продаж для себе. Як результат, скоригована експлуатаційна маржа піднялася до 44% у першому кварталі, порівняно з 36% у першому кварталі минулого року.
Дійсно, Палантір стріляє по всіх циліндрах. Але Джалурія та багато інших на Уолл -стріт вважають, що оцінка запасів піднялася занадто високо. “Ми не можемо раціоналізувати, чому Палантір є найдорожчою назвою в програмному забезпеченні. Відсутній значний чверть, що піднімає в квартиру, що піднімає найближчу траєкторію зростання, оцінка здається нестійкою”,-сказав він.
В даний час акції Palantir торгують за 228 разів заробіток наперед і 78 разів очікування доходу протягом наступних 12 місяців. Якщо говорити про це, лише кілька акцій S&P 500 торгівлі за більш ніж у 100 разів заробіток, а інші не торгують більше, ніж у 26 разів, очікування продажів. Тим часом є інші компанії, які зростають продажі навіть швидше, ніж Палантір, тому це дуже важко виправдати.
2. Курестрик (26% потенціал)
Натовп(Хрустка 1,32%) З початку 2023 року на силі своєї платформи безпеки Falcon піднімається на 352%. Незважаючи на масштабне відключення, яке закрили численні ІТ -системи у всьому світі минулого липня, компанія швидко відскочила. Акція збільшилася більш ніж удвічі з його мінімумів минулого літа, досягнувши ринкової обмеження майже 120 мільярдів доларів.
Але аналітики починають дивитись на запас Crowdstrike з все більш критичним оком. Цього місяця акція отримала три зниження від покупки, а один аналітик також ініціював покриття з утриманням. За останні три місяці рейтинги купівлі на Уолл -стріт знизилися з 41 до 31. А найнижча ціна серед них становить 350 доларів, що передбачає зниження на 26% від ціни на це написання.
Знову ж таки, оцінка, як видається, найбільша турбота про акції. Оперативно, Crowdstrike вдалося виростити свою клієнтську базу, оскільки більше підприємств намагаються консолідувати свої потреби в кібербезпеці та вирішувати використовувати широкий портфель послуг Crowdstrike. Станом на кінець першого кварталу сорок вісім відсотків його клієнтів використовують щонайменше шість його модулів. Це зростає від 40% два роки тому.
CrowdStrike використовує AI на своїй платформі з агентичними можливостями AI через свою нову платформу Шарлотти, яка допомагає вжити заходів після виявлення загрози безпеці, щоб посилити вразливість. Це, крім його можливостей машинного навчання, які допомагають йому виявити ці загрози в першу чергу. І зі зростаючою клієнтською базою він має більше даних, щоб приймати в свої алгоритми AI, що дає йому значну перевагу перед меншими конкурентами.
За останні кілька років Crowdstrike вдалося дуже сильним зростанням. Його щорічно повторюваний дохід піднявся на 20% у першому кварталі, перевищивши свої вказівки, і керівництво очікує, що ця кількість прискориться протягом усього року, оскільки більше підприємств приймає свою платформу Falcon Flex.
Тим не менш, акції зараз торгують за співвідношенням ціни до продажу в 22 рази очікування доходу протягом наступних 12 місяців. І хоча це може здатися не таким дорогим порівняно з Палантіром, це робить його третім за висотою ціною в S&P 500 за цією показником оцінки. І якщо ви віддаєте перевагу дивитися на його заробіток, це одна з жменьки акцій в індексі, що торгує вище 100 разів, в 135 разів, якщо бути точним.
Хоча це можливо, натовп або Палантір продовжують підніматися вище звідси, напевно, варто зняти гроші зі столу та знайти кращі цінності на ринку.
“Департамент уряду” (DOGE) використовує штучний інтелект для створення “списку видалення” федеральних норм, згідно з повідомленням, пропонуючи використовувати цей інструмент для скорочення 50% правил до першої річниці другого інавгурації Дональда Трампа.
“Інструмент рішення про дерегуляцію AI Doge” проаналізує 200 000 державних норм, згідно з внутрішніми документами, отриманими The Washington Post, та вибрати ті, які він вважає, що більше не вимагається законодавством.
Дож, яким керував Елон Маск до травня, стверджує, що 100 000 цих правил можуть бути усунені, після деяких відгуків персоналу.
Презентація PowerPoint, оприлюднена POST, стверджує, що Департамент житлового господарства та містобудування (HUD) використовував інструмент AI для прийняття “рішень на 1083 регуляторних розділах”, тоді як Бюро фінансового захисту споживачів використовувало його для написання “100% дерегуляцій”.
Пост розмовляв з трьома працівниками HUD, які повідомили газеті AI, “нещодавно використовували для перегляду сотень, якщо не більше 1000, ліній норм”.
Під час своєї кампанії 2024 року Дональд Трамп стверджував, що урядові положення “збільшують вартість товарів” та пообіцяли “найагресивніше скорочення регуляторних норм” в історії. Він неодноразово критикував правила, спрямовані на боротьбу з кліматичною кризою, і, як президент, наказав керівникам усіх державних установ провести огляд усіх правил у координації з Дож.
На запитання про використання AI в дерегуляції постом, прес -секретар Білого дому Гаррісон Філдс сказав, що “всі варіанти вивчаються” для досягнення обіцянок дерегуляції президента. Філдс заявив, що “жодного єдиного плану не було затверджено або освітлене зеленим кольором”, а робота “на ранніх етапах і проводиться творчим способом за консультацією з Білим домом”.
Поля додали: “Експерти з дожів, що створюють ці плани, є найкращими та найяскравішими в бізнесі і розпочато, що ніколи не змінюється трансформація державних систем та операцій для підвищення ефективності та ефективності”.
Муск призначив до Дога безліч недосвідчених співробітників, серед яких 19-річна Едварда Корристіна, яка раніше відома онлайн-ручкою “великі кулі”. На початку цього року Reuters повідомив, що Корристин була однією з двох соратників Дож, що сприяють використанню ШІ у федеральній бюрократії.
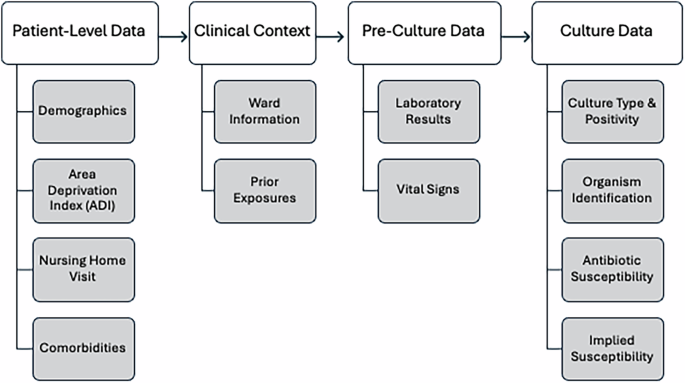
Набір даних ARMD26 доступний у Dryad та охоплює широкий спектр змінних, які організовані в декілька пов'язаних таблиць, кожен з яких пропонує унікальну перспективу на мікробіологічні, демографічні та клінічні характеристики пацієнта. Для полегшення аналізів нижче за течією набір даних включає таблиці щодо мається на увазі відносин з сприйнятливості до антибіотиків та правил, застосованих для висновку, коли пряме тестування не було доступне. Дослідники також можуть використовувати поздовжні дані, фіксуючи терміни інфекцій, попередні медичні процедури та експозиції ліків щодо замовлень на культуру, що дозволяє тимчасово аналізувати.
В основі ARMD стоїть мікробіологічна когорта культур, яка включає деталі про типи культури – культури дихання та крові – разом із ідентифікованими організмами та їх сприйнятливістю до антибіотиків. Результати сприйнятливості до антибіотиків були включені для 55 антибіотиків та класифіковані на п'ять груп: сприйнятливі, стійкі, проміжні, непереконливі та синергізм. Синергізм відноситься до випадків, коли взаємодія між двома антибіотиками призводить до посилення ефекту, тобто комбіноване лікування є більш ефективним, ніж або антибіотик. Ця категорія фіксує екземпляри, позначені як “синергія” або “без синергії” у наборі даних. Додаткові функції включають режим впорядкування культури (стаціонарний або амбулаторний) та терміни порядку.
Набір даних розміщує кожну культурну подію в її клінічному контексті. Інформація про відділення надає розуміння середовища догляду, де були зібрані культури, розрізняючи стаціонарні підопічні, відділення інтенсивної терапії (відділення інтенсивної терапії), відділення екстреної допомоги (ЕД) та амбулаторні клініки.
Для захоплення потенційних впливів на результати культури ARMD включає записи попередніх експозицій антибіотиків. Цей компонент детально описує назву антибіотиків, клас та підтип, що дозволяє аналізувати, як попередні методи лікування можуть впливати на сприйнятливість організму та розвиток резистентності. Зафіксовано терміни цих експозицій щодо збору культури, що підтверджує дослідження впливу попереднього використання антибіотиків на розвиток резистентності. Крім того, набір даних відстежує тенденції мікробної резистентності як на індивідуальний, так і на рівні популяції з часом, записуючи еволюцію резистентності відносно культурних подій для конкретних організмів та антибіотиків. Дані про історичну інфекцію зафіксовані завдяки включенню попередньої таблиці зараження організму, яка документує організми, виявлені в попередніх культурах для кожного пацієнта. Це дозволяє поздовжній аналіз рецидиву інфекції та його потенційний вплив на поточну антимікробну резистентність. Таблиця фіксує ідентифікований організм та терміни попередньої інфекції відносно кожної зібраної культури.
Демографічні показники пацієнтів пропонують істотний контекст для стратифікуючих аналізів за віком (зафіксовані в заздалегідь визначені діапазони) та статі (бінарно кодували). Крім того, набір даних включає в себе соціально-екологічні фактори завдяки включенню балів ADI, які фіксують соціально-економічні характеристики на рівні сусідства на основі Zip-кодів пацієнта з Атласу сусідства27. Оцінки ADI, розроблені для 9-значних поштових кодів, враховують такі фактори, як дохід, освіта, зайнятість та якість житла, забезпечуючи більш широкий контекст для розуміння відмінностей у ризику АМР. Для записів із лише 5-значними поштовими кодами, відсутні показники ADI були замінені на середній бал ADI, обчислений з 9-значних поштових кодів, що поділяють ті самі перші 5 цифр. Для інших випадків з недійсними або недоступними показниками ADI (наприклад, позначеними як P, U або NA), не було проведено імпутації, і ці записи залишалися як нульові значення в наборі даних.
Визнаючи роль закладів довгострокової допомоги в динаміці AMR, відвідування домашніх дому також задокументовано, визначаючи кількість днів між відвідуваннями та замовками культури, до 90 днів, щоб висвітлити потенційні фактори ризику резистентних інфекцій.
Комплексні лабораторні дані інтегруються в набір даних, фіксуючи ключові клінічні вимірювання, проведені за час кожного порядку культури. Змінні включають кількість лейкоцитів, гемоглобін, креатинін, лактат та прокальцитонін, серед інших регулярних зібраних досліджень. Кожна метрика узагальнюється за допомогою статистичних дескрипторів, таких як медіани, кварталі (Q25, Q75) та перші та останні записані значення. Крім того, дані життєво важливих ознак – включаючи серцевий ритм, артеріальний тиск, температуру та частоту дихання – забезпечують додатковий клінічний контекст, що дозволяє аналізувати фізіологічні реакції на інфекцію.
Коморбідні умови відображаються за допомогою стандартизованих індексів, таких як індекс коморбідності Elixhauser28 та Агентство з питань досліджень охорони здоров'я та якості (AHRQ) Програмне забезпечення клінічних класифікацій (CCSR)29. Кожна коморбідність є часовою позначкою щодо культури. Зокрема, поточні супутні захворювання позначаються за допомогою нульових значень у полі кінцевої дати, що вказує на те, що умова була активною під час збору культури. Ці нульові значення не представляють відсутні дані або відсутність умови. Крім того, також надається процедурна історія, записуючи медичні процедури (наприклад, центральні венозні катетерні розміщення, механічну вентиляцію), проведені до наказів про культуру, отримані з поточних кодів процедурної термінології (CPT).
Нарешті, таблиця сприйнятливості, що мається на увазі, спричиняє сприйнятливість до антибіотиків для препаратів, які не перевіряються, використовуючи широкий набір заздалегідь визначених правил. Ця таблиця фіксує випадки, коли сприйнятливість до одного антибіотика може означати сприйнятливість або резистентність до іншого на основі встановлених мікробіологічних та фармакологічних принципів. Таблиця призначена для підвищення інтерпретації даних про сприйнятливість, включаючи мається на увазі зв’язок між антибіотиками, що може бути критичним для керівництва клінічними прийняттям рішень та розуміння моделей стійкості. Крім того, ми ділимося правилами, застосованими для отримання цих мається на увазі, забезпечуючи прозорість та дозволяючи дослідникам зрозуміти та відтворювати логіку, що стоять за виведеними даними. Ця похідна таблиця використовує мікробіологічні принципи для захоплення взаємозв'язків між антибіотиками.
Дані демографії та мікробіологічної культури
ARMD включає 751,075 записів мікробіологічної культури, зібраних у 283 715 унікальних пацієнтів. Культури сечі становлять більшість зразків (50,0%), культури крові – 38,8%, а дихальні культури – 11,3%. Набір даних триває з грудня 1999 року по лютий 2024 року; Однак спостерігається помітне збільшення записаних замовлень на культуру, починаючи з 2008 року. Ця зміна узгоджується з прийняттям Епоса Стенфорда як системою EHR, яка значно покращила збір даних та документацію.
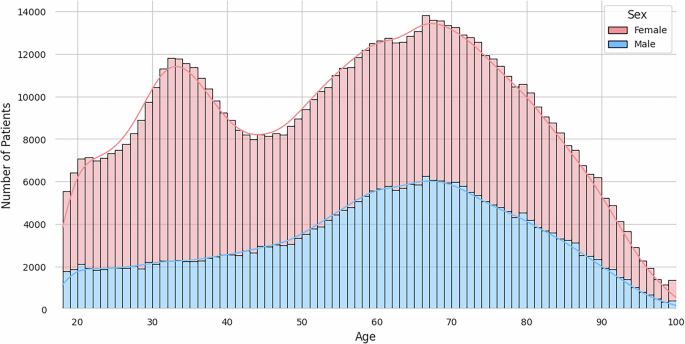
Населення пацієнтів демонструє широкий розподіл віку, як показано на рис. 2, середній вік 56,7 років. Розподіл статі в когорті виявляє переважання пацієнтів -жінок, що становить 66,9% (189 864 пацієнтів) загальної популяції, а пацієнти чоловічої статі – 33,0% (93 763 пацієнтів), тоді як мінімальна частка (0,03%, n = 82) має невідому позначення статі.
Рис. 2
Гістограма, що показує віковий розподіл пацієнтів у наборі даних ARMD.
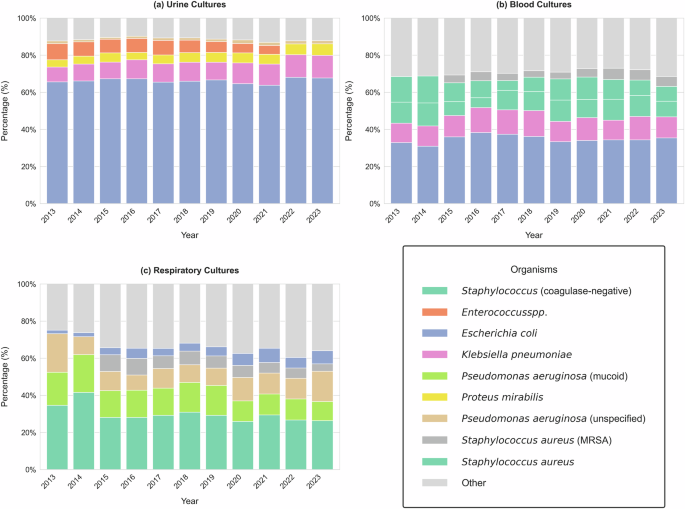
На малюнку 3 представлено щорічне розподіл перших найпоширеніших організмів, виявлених у культурах сечі, крові та дихання з 2013 по 2023 рік. У культурах сечі (рис. 3А), Escherichia coli (E. coli) є переважним збудником, послідовно становить більше 60% ізолятів. Klebsiella pneumoniae і Proteus чудовий є наступними найчастіше виявленими організмами, з невеликими варіаціями з часом. Ця стабільність у розподілі вказує на послідовний мікробіологічний профіль для ІПС у когорті, що відповідає встановленим епідеміологічним тенденціям по всій країні30,31,32.
Рис. 3
Розподіл п'яти найпоширеніших бактеріальних організмів, виявлених у сечі, крові та дихальних культурах з часом (2013–2023). Складені смугові діаграми показують відносний відсоток кожного організму за роком, з додатковою «іншу» категорію, що агрегує всі рідше ізоляти. Організми демонструють різні закономірності поширеності в різних типах культури, що відображають зміни в джерелах інфекції та мікробної екології.
У культурах крові (рис. 3В) спостерігається більш різноманітний спектр збудників збудників порівняно з культурами сечі. В той час E. coli Залишається найпоширенішим збудником, стафілококом ауреус та коагулазо-негативними стафілококами є більш поширеними, що відображає тенденцію грам-позитивних коккі, щоб викликати інфекції крові.
У дихальних культурах (рис. 3С), Pseudomonas aeruginosa є найбільш часто ізольованим збудником, можливо, пов'язаним із зміщенням відбору серед пацієнтів, які проходили тестування дихальної культури з неінвазивних (наприклад, індукованих мокротиння), так і інвазивних (наприклад, бронхоальвеолярних промивання). Відмінність між мукоїдним та не мукоїдним Pseudomonas aeruginosa спостерігається, ймовірно, що відображає зміни стандартів звітності про мікробіологію. Мукоїдні штами є клінічно значущими, особливо при хронічних дихальних інфекціях. Інші помітні організми включають Klebsiella pneumoniae і Staphylococcus aureusобидва вони залишаються стабільними внесками на дихальні інфекції протягом усього періоду дослідження.