Далі йде процес робочого процесу з використанням кодування Vibe для створення програми:
1. Виберіть помічник кодування AI: Виберіть таку платформу, як Toprit, Github Copilot або Cursor на основі технічних потреб та вимог інтеграції.
2. Визначте вимоги: Чітко вкажіть бажаний результат простою мовою. Специфіка та чіткість підказки безпосередньо впливають на якість коду, що генерується AI.
3. Огляд та вдосконалення: AI виробляє початковий код, який потім переглядається та вдосконалюється людськими експертами. Цей ітеративний процес гарантує, що програмне забезпечення відповідає стандартам експлуатації та безпеки.
4. Розгортання та монітор: Після остаточного огляду код розгортається у виробничому середовищі. Постійний моніторинг та зворотній зв'язок допомагають додатково оптимізувати рішення.
Точка 3 вище є критичною. Незважаючи на те, що кодування Vibe для загальних завдань має тенденцію бути дуже надійним, ви завжди повинні мати експерти з програмування, що переглядають код перед впровадженням.
ВІДПОВІДАЛЬНІ Проблеми та міркування
Хоча кодування Vibe пропонує значні переваги, це не без проблем. Найважливішими є:
Якість коду та безпеку: Код, що генерується AI, може містити вразливості або неефективність. Дослідження показують, що фрагменти коду, що генеруються AI, мають недоліки безпеки, підкреслюючи потребу в нагляді за людьми та суворим тестуванням.
Обмеження складності: Кодування Vibe перевершує стандартні завдання, але може боротися з вузькоспеціалізованими або новими технічними проблемами, які потребують глибокого досвіду домену.
Залежність від даних про навчання: Якість та актуальність коду, що генерується AI, залежать від даних, що використовуються для підготовки основних моделей. Застарілі або упереджені дані можуть призвести до неоптимальних рішень.
Потрібен людський нагляд: Справжня творчість, вирівнювання цілей та критичне мислення залишаються сферою людських експертів. Кодування Vibe слід розглядати як інструмент для спільної роботи, а не заміну кваліфікованих інженерів.
Дотримання нормативних норм: Для таких галузей, як фармацевтичні препарати та медичні пристрої, де розробка програмного забезпечення повинна дотримуватися суворих регуляторних стандартів, кодування Vibe представляє додаткові проблеми. FDA 21 CFR Частина 11 встановлює вимоги до електронних записів та електронних підписів, щоб забезпечити їх надійність, надійність та еквівалентність паперовим записам. Код, що використовується AI, використовується в системах, що підлягають цим правилам, повинен бути ретельно затверджений, задокументований та аудований для відповідності вимогам частини 11, включаючи підтримку аудиторських стежок, забезпечення цілісності даних та впровадження належного контролю доступу. Недотримання цих стандартів може призвести до питань невідповідності, що робить людський нагляд та надійні процеси перевірки ще більш критичними в регульованих умовах.
Майбутнє кодування Vibe у виробництві
Кодування Vibe все ще знаходиться на ранніх стадіях, але його вплив на виробництво вже очевидний. У міру того, як моделі AI стають більш досконалими та мультимодальними – включаючи голосові, текстові та візуальні входи – потенціал для інтуїтивного, швидкого та спільного розробки програмного забезпечення лише зросте. Виробники, які охоплюють такий підхід, будуть добре розташовані, щоб вести в епоху розумних заводів та промисловості 4.0.
Ніхіл Махія є членом Mesa International та експертом з виробництва SAP з виробництва SAP з більш ніж 16 років спеціалізованого досвіду оптимізації виробничих процесів за допомогою SAP Solutions.
Нації, що розвиваються, кидають виклик десятиліттям Big Tech, що тривають у глобальних даних, вимагаючи зберігання інформації їх громадян на місцевому рівні. Цей крок зумовлений усвідомленням того, що країни віддавали свій найцінніший ресурс для технологічних гігантів для створення ринкової капіталізації на трильйон доларів.
У квітні Нігерія попросила Google, Microsoft та Amazon встановити конкретні терміни відкриття центрів обробки даних у країні. Нігерія робить цю вимогу близько чотирьох років, але компанії поки що не змогли виконати свої обіцянки. Тепер Нігерія створила робочу групу з компаніями, щоб переконатися, що дані зберігаються в її берегах.
“Ми не сказали їм більше відмову-що нам потрібна дорожня карта, коли вони приїжджають до Нігерії”,-сказав Кашіфу Інува Абдуллахі, генеральний директор технологічного регулятора Нігерії, Національне агентство з розвитку інформаційних технологій, Решта світу.
Інші країни, що розвиваються, включаючи Індію, Південну Африку та В'єтнам, також реалізували подібні правила, що вимагають, щоб компанії зберігали дані на місцях. Центральний банк Індії вимагає, щоб платіжні компанії приймали фінансові дані в країні, тоді як В'єтнам зобов'язує, щоб іноземні телекомунікації, електронна комерція та постачальники платежів в Інтернеті створювали місцеві офіси та зберігають дані користувачів у межах своїх берегів протягом принаймні 24 місяців.
Ми більше не сказали їм не відмови – нам потрібна дорожня карта, коли вони приїжджають до Нігерії.
Amazon та Google відмовилися коментувати глобальні виклики до своєї бізнес -моделі. В електронному листі до Решта світуMicrosoft заявила, що розгорнула крайові вузли в Нігерії для посилення локального зв’язку, зменшення затримки та підтримки проживання даних. “Ми виступаємо за спільним, регіонально інтегрованим підходом, співпрацюючи з урядами для розробки регіональних та пан-африканських рамок, які підтримують безпечні транскордонні потоки даних”,-йдеться в електронному листі.
Експерти вважають, що відштовхування урядів підкреслює більш широку обізнаність про економіку вилучення даних. Країни, які колись вітали іноземні технологічні інвестиції без умов, зараз шукають конкретних переваг для своїх громадян.
“Все більше і більше африканських країн, включаючи Африканський Союз, сьогодні прийшли до висновку, що вони відчувають, що їхні дані та економічні вигоди, що випливають із цих даних Решта світу. “Занепокоєння полягає в тому, що економічна вигода стосується лише великих платформ, які часто не знаходяться в цій країні”.
Як повідомляється, більшість даних, отриманих від африканських користувачів Інтернету, сидять у центрах обробки даних у Європі та на Близькому Сході. Зараз кілька африканських країн витрачають мільйони на створення нових центрів обробки даних, використовуючи державні гроші та міжнародні позики. Африканський банк розвитку став головним фінансувачем, розглядаючи ці проекти як засіб для цифрової незалежності, заявив Фолашаде Суше, старший науковий співробітник в школі уряду Блаватнік університету Оксфордського університету.
Серед кількох підприємств Конго отримав 77 мільйонів доларів за перший національний центр даних Центральної Африки, а Африканський банк розвитку інвестував 52 мільйони доларів у технологічний парк на суму 60 мільйонів доларів у Кабо -Верде. Africa50, континентальна інвестиційна фірма, ввів 15 мільйонів доларів в Єгипетський центр обробки даних Рая. Міжнародна фінансова корпорація Світового банку інвестувала 100 мільйонів доларів – найбільшу інвестицію, але в Африку – в Raxio Group, компанію центрів обробки даних, яка працює щонайменше в шести африканських країнах, включаючи Уганду, Анголу, Кот -д'Івуарі та Ефіопію.
Робоча група, розпочата Абдуллахі в Нігерії, мала на меті прискорити дотримання та досягти угоди про те, що компанії повинні або будувати власні заклади, або допомогти місцевим операторам Нігерії модернізувати свої та використовувати їх. Хоча технічні гіганти стверджували, що місцеві варіанти зберігання були недостатньо хорошими, вони не змогли пояснити, які поліпшення потрібні, сказав Абдуллахі. Чиновники Нігерії вважали це тактикою, розробленою для уникнення дорогих інвестицій.
“Вони сказали, що спільно з існуючими центрами обробки даних було б чудовим способом почати, але центри обробки даних не відповідали їх вимогам”,-сказав Абдуллахі. “Таким чином, ми сказали їм або інвестувати в інфраструктуру, щоб задовольнити наші суверенні потреби, або ми закриємо їх і використовуватимемо місцевих провайдерів”.
Незважаючи на те, що багато африканських урядів наполягають на місцевому зберіганні даних, це не обов'язково призводить до кращого захисту, оскільки іноземні компанії часто залишаються основними бенефіціарами, створюючи протиріччя в зусиллях цифрового суверенітету.
“Поширеність іноземних технологічних фірм в Африці, з їхнім доступом до цінних даних користувачів, розкриває африканські уряди та громадян до вразливості даних та національної безпеки”, – сказав Суше.
Google, Amazon та Microsoft використали слабкі закони в країнах, що розвиваються, нічого не повертаючи, сказав професор університету Південної Африки Колін Тхакуур Решта світу. Вони скористалися країнами, які не розуміли, наскільки цінною буде інформація їх громадян.
Більшість цих міжнародних компаній експлуатували прогалини в кібер -законах.
“Більшість цих міжнародних компаній, які домінують у зборі даних та житла в усьому світі, використовували прогалини в кібер -законах для узурпування та продавати їх без наслідків”, – сказав Такуур. “Однак поштовх до суверенітету даних дозволяє країні відновити та забезпечити внутрішні дані, пов'язані з її громадянами та компаніями”.
Багато країн, що розвиваються, були занадто повільними, щоб оновлювати свої закони, оскільки технологія швидко просунулася. Уряди, які не передбачили Інтернет -буму, зараз намагаються писати нові закони, які можуть ефективно керувати компаніями, сказав Такуур.
“Ніхто не очікував успіху Інтернету та соціальних медіа, а тепер АІ”, – сказав він. “Наша проблема полягає в тому, що ми, як континент, занадто повільні, щоб змінити свою регуляторну основу”.
Південна Африка – єдина африканська країна, де Amazon, Microsoft та Google побудували власні центри обробки даних, додаючи на ринок, який оцінюється в 2,28 мільярда доларів у 2023 році, повідомляє фірма з досліджень ринку Arizton Advisory & Intelligence. Завдяки “величезному споживчому ринку, підтримуючому регуляторному середовищу для місцевого зберігання даних та динамічним сектором технологій”, Південноафриканський ринок обробки даних може залучити до 2029 року інвестиції в розмірі 3,7 мільярдів доларів, заявив у звіті дослідник ринку в Чикаго.
Нещодавно Microsoft пообіцяла побудувати центр обробки даних у Кенії через партнерство з G42, провідною компанією AI та Cloud Cloud Computing United Arab Emirates. Економічні фактори впливають на те, де технологічні компанії вирішують інвестувати, заявив Юсра Хаяті, інвестиційний директор Africa50.
“Наприклад, Південна Африка має значну інфраструктуру, яка відповідає вимогам, особливо з точки зору волоконного кабелю, що є основою зберігання даних”, – сказав Хаяті Решта світу. “Також для більшості цих компаній Південна Африка представляє свій найбільший ринок з точки зору доходу та попиту на послуги”.
Нігерія та інші африканські країни стикаються з перешкодами для залучення великих інвестицій, оскільки вони повинні довести, що вони мають стабільні закони, хороша інфраструктура та достатня кількість бізнесу, щоб зробити дорогі центри обробки даних вигідними,-сказав Брюс Айоте, засновник та генеральний директор компанії Abuja Provider Suburban Cloud.
“Попит Нігерії все ще фрагментується невизначеністю щодо примусового виконання, транскордонних правил передачі даних та стимулів для локалізації”,-сказав Айонот Решта світу. “Без чітких, стабільних правил глобальні фірми залишаються обережними”.
Останніми роками в нігерійських містах з'явилися високоякісні центри даних таких компаній, як Mainone, Open Access Centers, Rack Center та Galaxy, а також китайський технологічний гігант Huawei, що відповідає міжнародним стандартам надійності та безпеки. Зараз ці заклади обслуговують банки, телекомунікаційні компанії та фірми з фінансових технологій, які потребують швидких, місцевих хостинг -послуг.
Цього місяця MTN, найбільша телекомунікаційна компанія в Африці, запустила те, що вона назвала найбільшим центром обробки даних Західної Африки та хмарною послугою для конкуренції Amazon, Google та Microsoft. Проект коштує 235 мільйонів доларів.
Попит на місцеві хмарні послуги зростає через високу вартість міжнародних постачальників та підвищення обізнаності про суверенітет даних.
“Нігерія досягає постійного прогресу до досягнення суверенітету даних, але поточна ємність центру обробки даних ще не є повністю ефективною або широко поширеною, щоб підтримувати його в масштабі”, – сказав Айонот.
Коралогікспровідний постачальник платформи спостереження повного стека, оголошує про стратегічну угоду про співпрацю (SCA) з AWS, орієнтовану на всебічну, вдосконалену спостережливість та моніторинг. Разом Coralogix та AWS доставлять масштабовані рішення, що працюють на AI, які допомагають організаціям залишатися перед потенційними проблемами та загрозами безпеки.
Цей SCA має на меті переходити підприємства, що перевищують те, що можуть запропонувати сучасні платформи спостереження: статичні, основні моделі машинного навчання для виявлення аномалії, які погано оснащені для складних ітеративних систем. Завдяки інтеграції з Amazon BedRock, Coralogix передає проактивне, автоматизований підхід, що працює на AI, до спостереження, який фокусується на скороченні простоїв, прискорення розуміння та підвищення надійності системи.
Більш конкретно, Coralogix та AWS прицілили розробку повністю інтегрованого рішення для AWS WAF та Amazon Cloudfront, що приносить рідну видимість AWS в потенційні загрози. Обробляючи великі обсяги даних про моніторинг WAF, EDGE та реальних користувачів за допомогою аналітики Coralogix, користувачі AWS WAF та Amazon CloudFront виграють від точної, економічно ефективної ідентифікації загрози безпеці.
“Ми в захваті від роботи з AWS у наданні клієнтам найдосконалішої, поза межами спостереження та моніторингу безпеки для Amazon CloudFront та AWS WAF”,-сказала Аріель Ассараф, генеральний директор Coralogix. “Не тільки клієнти AWS доступні доступні набагато більше даних, ніж раніше, але вони також можуть впевнено визначити реальні загрози за лічені секунди та автоматизувати реконструкцію, використовуючи повну спостережливість Coralogix та вдосконалені рішення щодо сповіщення. Ця співпраця підкреслює нашу прихильність до забезпечення вищого рівня для хмарних середовищ, що є як ефективним та доступним”.
З видимістю в AWS, що розміщується, на PREM та гібридному середовищі на кожному етапі хмарної міграції, Coralogix дає можливість організаціям впевнено виконувати свої цілі цифрової трансформації, повідомляє компанія. Coralogix використовує різноманітні послуги AWS AWS-включаючи Amazon Simple Service Service (Amazon S3), Amazon Data Firehose та AWS Lambda-запропонувати швидкий, масштабований, економічно ефективний моніторинг даних та аналіз даних, зазначила компанія. Як результат, Coralogix може витягувати показники та теги з понад 100 служб AWS, створюючи цілісний погляд на всю екосистему підприємства, підкріплену за допомогою спостережливості без тертя.
“AWS та Coralogix діляться єдиною місією: розширення можливостей організацій приймати стратегічні рішення сьогодні, які рухаються завтрашніми інноваціями. Наша співпраця присвячена керівництву клієнтів на кожному етапі своєї хмарної мандрівки, вирішуючи негайну інфраструктуру, при цьому прокладаючи шлях для майбутніх технологій, як AI”, “Еллісон Джонсон, старший менеджер, технічні партнери – Americas в AWS. “Інтегруючи платформу Coralogix з неперевершеною шкалою та підтримкою від AWS, ми пропонуємо потужне рішення, яке спрощує модернізацію додатків, забезпечує плавні хмарні міграції та прискорює прийняття ШІ. Це співпраця оснащує організації для орієнтації на складність цифрової трансформації з більшою ефективністю, допомагаючи їм залишатися пахлими та конкурентними у всесвітньому світі, що спричиняє,”.
Щоб дізнатися більше про Coralogix та AWS, відвідайте https://coralogix.com/.
Оголошення публічного попереднього перегляду глибоких досліджень в Azure AI Foundry-API та SDK-пропозиція на основі SDK вдосконалених можливостей агентських досліджень OpenAI.
Розблокувати автоматизацію веб-досліджень в масштабах підприємств
Сьогодні ми раді повідомити про публічний попередній перегляд Глибоке дослідження в Azure AI Foundry—А, на основі API API та набору програмного забезпечення (SDK) пропонування розширених агентських дослідницьких можливостей OpenAI, повністю інтегрованих з агентською платформою Azure Enterprise.
За допомогою глибоких досліджень розробники можуть будувати агенти, які глибоко планують, аналізують та синтезують інформацію з усього веб-сайту-ауттоматичні складні дослідницькі завдання, генерують прозорі, аудиторські результати та безперешкодно складають багатоетапні робочі процеси з іншими інструментами та агентами Azure AI Foundry.
Агенти AI та робота з знаннями: зустріч з наступною межею автоматизації досліджень
Генеративні AI та великі мовні моделі зробили дослідження та аналіз швидше, ніж будь -коли, що живлять такі рішення, як Chatgpt Deep Research та дослідник у Microsoft 365 Copilot для людей та команд. Ці інструменти перетворюють повсякденну продуктивність та робочі процеси для документів для мільйонів користувачів.
По мірі того, як організації прагнуть зробити наступний крок-інтегруючи глибокі дослідження безпосередньо у свої бізнес-програми, автоматизуючи багатоетапні процеси та керуючи знаннями в масштабах підприємства-потреба в програмованому, складеному та аудиторському автоматизації досліджень стає зрозумілою.
Тут приходять Foundry та Deep Research Ai-Foundry та Deep Research: пропонуючи гнучкість для вбудовування, розширення та оркестрування досліджень світового класу як послуги у всій вашій екосистемі підприємства-і підключіть її до своїх даних та ваших систем.
Глибокі дослідницькі можливості в службі агента AI AI AI
Deep Research в службі Foundry Agent побудовано для розробників, які хочуть вийти за межі вікна чату. Пропонуючи глибокі дослідження як композиційний інструмент агента через API та SDK, Foundry AiSure AI дозволяє клієнтам:
Автоматизуйте дослідження веб-масштабу Використовуючи найкращу модель дослідження, обґрунтовану пошуком Bing, з кожним розумінням простежуваним та підтримуючим джерелом.
Програмно будувати агенти Це може бути викликано додатками, робочими процесами чи іншими агентами-перетворюючи глибокі дослідження багаторазового, готового до виробництва.
Оркеструвати складні робочі процеси: Складіть глибокі дослідницькі агенти з логічними додатками, функціями Azure та іншими роз'ємом служби Foundry Agent для автоматизації звітності, сповіщень тощо.
Забезпечити управління підприємствами: Завдяки безпеці, відповідності та спостереження AI AI AI, клієнти отримують повний контроль та прозорість щодо того, як проводять дослідження.
На відміну від упакованих помічників чату, глибокі дослідження в службі ливарних агентів можуть розвиватися з вашими потребами – готові до автоматизації, розширення та інтеграції з майбутніми внутрішніми джерелами даних, коли ми розширюємо підтримку.
Як це працює: архітектура та потік агента
Глибокі дослідження в службі агентів Foundry Agent є архітованою для гнучкості, прозорості та складності – тому ви можете автоматизувати дослідження, які є настільки надійними, як вимагає ваш бізнес.
По суті, глибока модель досліджень, O3-Deep-дослідження, оркеструє a Багатоступеневий дослідницький трубопровід Це щільно інтегрується з заземленням з пошуком Bing та використовує останні моделі OpenAI:
Уточнення намірів та обстеження завдання: Коли програма користувача або нижче за течією подає дослідницький запит, агент використовує моделі серії GPT, включаючи GPT-4O та GPT-4.1 для уточнення питання, збирайте додатковий контекст, якщо це необхідно, і точно обсягуйте дослідницьке завдання. Це гарантує, що результати агента є як релевантним, так і діючим, і що кожен пошук оптимізований для вашого бізнес -сценарію.
Веб -заземлення з пошуком Bing: Після того, як завдання буде піддано, агент надійно викликає заземлення інструментом пошуку Bing, щоб зібрати кураторний набір високоякісних, останніх веб-даних. Це гарантує, що модель досліджень працює з фундаменту авторитетних, сучасних джерел-ні галюцинацій із нестабільного або нерелевантного вмісту.
Виконання задач глибокого дослідження: Модель O3-Deep-дослідницької моделі запускає виконання дослідницьких завдань. Це передбачає мислення, аналіз та синтезу інформації у всіх виявлених джерелах. На відміну від простого узагальнення, це причини, що покроковують, повороти, коли він стикається з новими уявленнями, і складає всебічну відповідь, чутливу до нюансів, неоднозначності та нових моделей у даних.
Прозорість, безпека та відповідність: Кінцевий вихід – це структурований звіт, який документує не лише відповідь, але й шлях міркувань моделі, цитати джерела та будь -які роз'яснення, що вимагаються під час сеансу. Це робить кожну відповідь повністю аудиторською-обов'язковою для регульованих галузей та випадків використання високих ставок.
Програмна інтеграція та склад: Виявляючи глибокі дослідження як API, Azure AI Foundry надає вам можливість посилатися на дослідження з будь -якого місця – бізнес -додатки, внутрішні портали, інструменти автоматизації робочого процесу або як частина більшої екосистеми агента. Наприклад, ви можете запустити дослідницький агент як частину багатоагентного ланцюга: один агент виконує глибокий веб-аналіз, інший генерує слайд-колоду з функціями Azure, а третій електронний лист-результат, які приймають рішення з програмами Azure Logic. Ця складність є справжньою зміною ігор: дослідження вже не є посібником, одноразовим завданням, а будівельним блоком для цифрової трансформації та безперервного інтелекту.
Ця гнучка архітектура означає, що глибокі дослідження можуть бути безперешкодно вбудовані в широкий спектр робочих процесів та додатків підприємства. Вже організації в галузях промисловості оцінюють, як ці програмовані дослідницькі агенти можуть впорядкувати високоцінні сценарії-від аналізу ринку та конкурентного інтелекту, до масштабної аналітики та регуляторної звітності.
Ціни на глибокі дослідження (модель: O3-DEEP-дослідницькі) є таким:
Введення: 10,00 доларів за 1 млн.
Кешований вхід: 2,50 долара на 1 млн.
Вихід: $ 40,00 на 1 млн.
Токени з пошуку стягуються з введенням цінів на маркер для моделі, що використовується.Ви окремо понесете заряди за заземлення з пошуком Bing та базовою моделлю GPT, яка використовується для уточнення питань.
Почніть з глибоких досліджень
Глибоке дослідження Зараз доступний у обмеженому публічному попередньому перегляді для клієнтів служби служби агента AI AI. Для початку:
Ми не можемо дочекатися, щоб побачити інноваційні рішення, які ви побудуєте. Слідкуйте за історіями клієнтів, нових функцій та майбутніх вдосконалень, які продовжуватимуть розблокувати наступне покоління агентів AI Enterprise.
Минуло трохи більше року, як CERN, де проживають великий адронний колайдер (LHC), став базою для трирічної пілотної фази відкритого квантового інституту (OQI). OQI-це ініціатива, орієнтована на багато зацікавлених сторін, глобальна, наукова дипломатія, основні цілі якої включають забезпечення квантового обчислювального доступу для всіх та прискорення додатків для людства.
Виступаючи з комп'ютером щотижня у червні на вступному форумі Quantum Datacentre Alliance, який проводився на електростанції Баттерсі в Лондоні, Арчана Шарма, старший радник з питань відносин з міжнародними організаціями та головним вченим CERN, описала OQI як “оцінку того, де ми опинилися в квантовій обчислювальній частині, квантових, квантових комп'ютерів”.
«Місія Церна – це фізика частинок», – каже вона. “Ми не можемо просто закрити фізику частинок і розпочати роботу на квантових комп'ютерах”.
Але Шарма вважає, що може існувати потенційні синергії між розвитком квантових технологій та дослідженнями, що проводяться в CERN. Прискорення прискорювачів частинок відбувається через різні сили, каже вона. “Усі процеси, що відбуваються під час прискорення, – це дуже багато квантової механіки”.
Більше того, квантова механіка – це магія, яка дозволяє різним детекторам прискорювача частинок збору результатів експериментів, які проводять вчені в CERN.
І існує величезна кількість даних, що виробляються цими експериментами. Насправді, технологія, розроблена для підтримки експериментів з фізики частинок у CERN, що називається White Rabbit, встановлюється для досягнення виправлення помилок у квантових обчисленнях. Білий Кролик-це система точного часу з відкритим кодом, яка може похвалитися суб-наносекундною точністю, яка розподіляється через Ethernet.
Британська фірма з квантових мережевих технологій NU Quantum нещодавно приєдналася до співпраці Білого кролика CERN. Технологія від CERN пропонує Nu Quantum спосіб доставки синхронізації на необхідному рівні для масштабування квантових обчислювальних мереж.
Обчислення в галузі фізики частинок
Мережа вийшла з ідеї від Тіма Бернерс-Лі, коли він був у CERN, і сьогодні в будинку LHC підтримує кілька сховища Github і розробив ряд платформ з відкритим кодом у своєму проведенні досліджень фізики частинок.
Обчислення – один із трьох стовпів CERN. “Перший [pillar] – це дослідження, – каже Шарма. А потім є обчислення ».
Шарма каже, що CERN розвиває свої можливості обчислювального центру для задоволення потреб інфраструктури, що вимагається експериментами.
“Нам потрібно переконатися, що ми розглядаємо хороші дані та записуємо хороші дані”, – каже вона, що означає, що CERN повинен знизити дані з 40 мільйонів зіткнень в секунду до приблизно 1000 спочатку, а потім до 100.
Ця обробка повинна відбуватися надзвичайно швидко, перш ніж буде виявлено наступне зіткнення прискорювача частинок. Вона каже, що час обробки становить близько 2,5 мілісекунд.
Датчики, щоб використовувати термінологію CERN, є “каналами”, і для обробки на експеримент є 100 000 цих каналів. CERN покладається на розпізнавання шаблонів та машинне навчання, щоб допомогти в обробці величезних наборів даних, вироблених під час експериментів, та створити моделювання моделей, як пояснює Шарма: “Це найбільший інструмент, який ми маємо. Ми провели багато моделювання для створення моделей, які розповідають нам, як читати кожне зіткнення”.
“Нам потрібно переконатися, що ми розглядаємо хороші дані та записуємо хороші дані”
Арчана Шарма, Церн
По суті, моделі та моделювання дозволяють CERN впорядкувати збір тригерних даних або зіткнень, визначених як крихітні електричні сигнали від датчиків по 100 000 каналів, які потребують обробки під час експерименту.
Дані тригера використовуються для реконструкції, де підсумовуються вимірювання енергії від датчиків. Реконструкція – це ефективно моделювання експерименту за допомогою спостережуваних даних. У Enterprise IT таке налаштування може вважатися прикладом цифрового близнюка. Однак Шама каже, що моделювання CERN є близьким, але не може бути повністю класифіковане як цифровий близнюк.
“Ми не зовсім цифровий близнюк, оскільки програмне забезпечення для фізики є ймовірнісним. Ми намагаємось бути максимально близькими”, – каже вона.
Добре, погане і явно неправильно
У світі обробки даних завдання, яке є в руці, є однією з прогнозних аналітики, оскільки вона побудована на науці, використовуючи теорію прогнозування. “Ми стоїмо на плечах прогнозів – ми вимірюємо і підтверджуємо те, що нам кажуть проти того, що прогнозує теорія”, – каже Шарма.
Або спостереження, засновані на даних, зібраних з експерименту, підтримують теорію, або щось не так. Шарма каже, що неправильний результат може означати, що теорія не є правильною і потребує налаштування, або це може означати, що в самому LHC є помилки калібрування.
LHC збирається вступити на фазу «технічної зупинки», трирічне відключення, де вона буде модернізована для підтримки нової науки. За словами Шарма, однією областю вдосконалення є в 10 разів покращення світності, що, за її словами, дозволить йому зібрати в 10 разів більше даних.
Поряд з роботою, яка буде потрібна інфраструктура та детектори CERN, Шама каже, що комп'ютерний центр CERN також готується до величезного збільшення даних, які потрібно буде обробити.
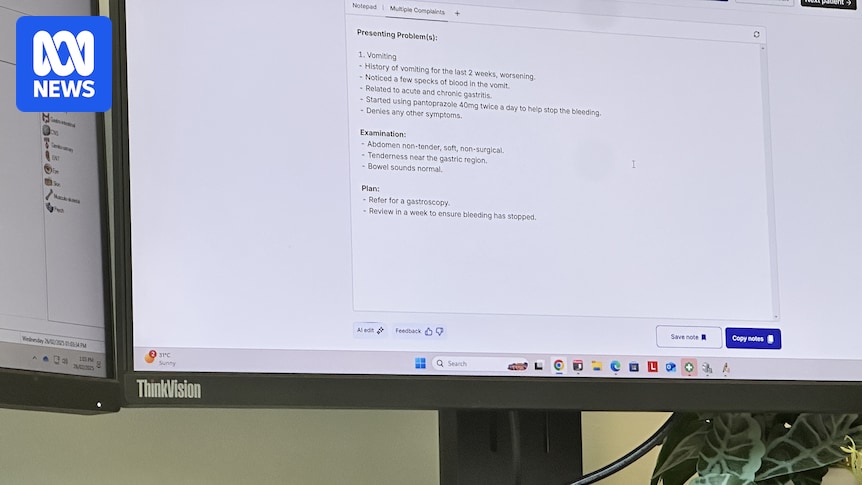
Штучний інтелект, здається, є скрізь у ці дні – тому не дивно, що інновації пробилися до сектору охорони здоров'я.
Його останнє підприємство? AI -книжники.
Від лікарень до клінік лікарів загальної практики, інструмент похвалив лікарі, які допомагають полегшити навантаження на зворотне навантаження.
Д -р Бен Кондон, який зараз працює в австралійській компанії з охорони здоров’я, вперше наткнувся на ШІ під час зміни в сільському відділенні надзвичайних ситуацій у західній австралійській австралійській мові.
“Мене здуло, наскільки це допомогло, з точки зору надання мені додаткового набору рук … написати всі мої нотатки”, – сказав він.
Але експерти попередили, що існують реальні ризики: інформація про пацієнтів із порушень даних може отримати досить копійку в темній павутині, і технологія має потенціал для отримання “оманливої” інформації.
Як це працює?
Як випливає з назви, AI -писар використовує програмне забезпечення для переписування консультацій між лікарями та пацієнтами в режимі реального часу – трохи схожим на друкарську залу.
Потім він може створити медичну записку для лікаря, щоб переглянути та схвалити додати до медичного запису пацієнта.
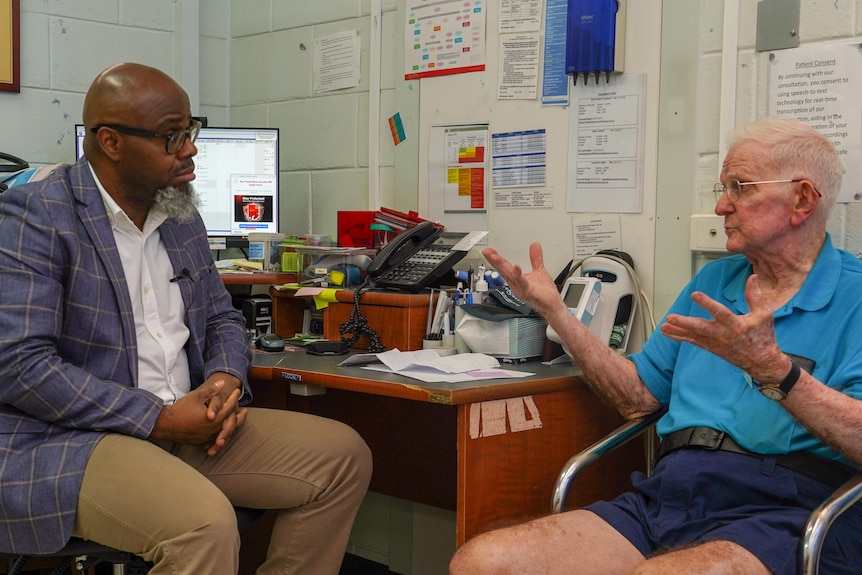
GPS та лікарні взялися за допомогою записів AI Speech to Text, щоб полегшити адміністративне навантаження на клініцистів. (ABC News: Емілі Добсон)
“Я б легко сказав [it can save] Години в зміні, – сказав доктор Кондон.
“Це дійсно відчутно … в 15-хвилинній консультації ви, як правило, пишете нотатки протягом 8-10 хвилин, це скорочує його до хвилини або менше.
“Підсилюється через зміну, це досить важливо”.
За даними Квінслендського здоров'я, три лікарні та медичні послуги в даний час пілотують записи AI.
Президент Квінсленду Австралійської медичної асоціації, доктор Нік Йім, заявив, що цей крок “революціонує” так, як працюють лікарі та пацієнти.
Він сказав, що це доповнило постійне впровадження інших цифрових інновацій, таких як інтегрований електронний медичний запис (IEMR).
“IEMR надає базову систему, на якій можна додати інструменти AI … Розгортання вже роками, і ми вітаємо новини, які зараз є на 80 сайтах по всій HHSS”, – сказав д -р Йім.
“Ці інструменти можуть робити помилки”
Хоча експерти визнають, що інструменти для зменшення навантаження на перевантажених лікарів можуть заповнити важливий розрив, вони також попередили про потенційні підводні камені.
Саїд Ахлахпур, доцент університету Квінсленду та експерт з питань охорони здоров'я та охорони здоров’я, заявив, що він обережно оптимістично оптимістично ставиться до зростання використання технології.
“Є негайні вигоди [but] З цього приводу, ризики справжні, і у мене є кілька основних проблем – вони поділяють багато клініцистів, юридичних експертів та регуляторів конфіденційності “, – сказав він.
Д -р Ахлахпур досліджував порушення даних про здоров'я та згоду на пацієнтів протягом багатьох років. (Поставляється: доктор Саїд Ахлахпур)
Наразі AI -книжники не регулюються Адміністрацією терапевтичних товарів (TGA), тому юридична відповідальність за все, що створюється програмним забезпеченням, лежить з лікарем, додав доктор Ахлахпур.
“Ці інструменти можуть робити помилки, особливо з сильними акцентами, галасливими кімнатами або медичним жаргоном.
ЩоAI -книжники можуть неправильно трактувати або опустити клінічно важливу інформацію, наприклад, заплутані назви наркотиків, неправильно класифікація симптомів або навіть галюцинацію вмісту.Що
Нещодавній огляд Коледжу загальної практики Королівської Австралії зазначив, що показники галюцинації – оманливі результати, що утворюються інструментами ШІ – коливаються від 0,8 відсотка до майже 4 відсотків.
Д -р Ахлахпур сказав, що це може призвести до помилок у записах та ризиках безпеки пацієнтів.
“На відміну від другорядних помилок, ці помилки можуть мати серйозні наслідки, якщо їх не виправити в медичному записі пацієнта”, – сказав він.
Зберігання даних у безпеці
Нещодавно авіакомпанія Qantas стала жертвою основної атаки даних – останній випадок у довгому списку інцидентів, де приватна інформація просочилася в Інтернеті.
У міру того, як спроби злому та порушення даних стають більш поширеними, а використання ШІ в галузі охорони здоров'я зростає, як захистити інформацію про пацієнтів залишається ключовим питанням.
Завантаження …
Д -р Саїд Ахлахпур сказав, що, поки є гарантії, це зводиться до того, як індивідуальні клініки та медичні послуги їх реалізують.
“Лікарні та клініки потребують хороших внутрішніх систем: належна підготовка, ІТ-безпека, багатофакторна автентифікація та сучасні повідомлення про конфіденційність”,-сказав він.
“Вибір поважних матеріалів постачальника теж – той, який зберігає дані локально, використовує шифрування та не використовує дані пацієнтів для навчання ШІ без згоди.”
Д -р Ахлахпур заявив, що не знає жодних повідомлених порушень даних, пов’язаних із технологією AI Scribe в Австралії, але більш широкий сектор охорони здоров'я спостерігав серйозні випадки.
“Медичні записи особливо цінні в темній павутині, часто коштують у 20 – 100 разів більше, ніж викрадені дані про кредитну карту”,.
FАбо найдовше, Аргентина славилася своїм прекрасним футболом, шамболічною економікою та популістською політикою. Зовсім недавно вона займала глобальну розмову з дещо інших причин. Перший – це радикальний, лібертаріанський президент, Хав'єр Майлі, який пообіцяв принципово реструктурувати економіку, що сильно хворіє, – що перейшло від одного з найбагатших у світі на межі 20то століття до рішучого посереднього в 21святий. Друга – це величезне багатство в природних ресурсах.
Країна є третиною літієвого трикутника-разом з Болівією та Чилі-і є домом для другого за величиною басейном сланцевої нафти у світі після Техасу та Нью-Мексико в США. Жоден прем'єр -міністр Індії не був в Аргентині на двосторонній візит за 57 років. Тепер, Аргентина має значення. І тому Нарендра Моді поїхала туди 5 липня.
Поєднання економіки, багатої ресурсами та ліберальної економічної політики є потужною. Кожна країна світу шукає ресурси. У той же час, націоналізм ресурсів зростає, і країни не схильні бути ліберальними у обміні цими ресурсами. Еволюція технологій означала, що глобальна економіка сприйняла рішучий поворот до сценарію, який буде мінеральним та ресурсним інтенсивним. Технології енергетичного переходу, незалежно від інфраструктури відновлюваної енергії чи електромобілів, потребують більше корисних копалин, включаючи літій.
Показати повну статтю
Технології та інфраструктура, пов'язані з штучним інтелектом, такими як великі центри обробки даних, потребують багато корисних копалин, включаючи мідь. У той же час спостерігається природне зростання звичайних цілей для корисних копалин, металів та енергії. І існує постійно зростаючий розрив між попитом та пропозицією.
Мінеральні амбіції Індії
Як і інші великі економіки, Індія також шукає стабільного постачання критичних корисних копалин для своїх виробничих амбіцій. Це, безумовно, зацікавлений у придбанні деякого літію Аргентини. Зрештою, країна має третій за величиною заповідник літію у світі.
Але це також повинно спровокувати дві нитки мислення для політики в Індії. По-перше, настав час відмовитися від ресурсного песимізму. Індія має багату геологію, порівнянну з одними з найкращих у світі, включаючи Канаду та Австралію. Просто ми не досліджували достатньо під нашою поверхнею. Нам потрібно надати розвідку великий поштовх. Для цього політика розвідки повинна бути не врахована з аукціонів. На аукціоні щось невідоме. Настав час вийти за рамки покладання на дві державні компанії для розвідки мінералів. Приватному сектору потрібно брати участь. Але це зробить це лише в тому випадку, якщо те, що він знаходить під час розвідки, може бути вільно монетизоване.
По -друге, Індії потрібно зафіксувати потенціал для плавання. Видобувані мінерали не використовуються, поки вони не будуть оброблені в плавучих металах, використовуючи велику кількість енергії. Просунута економіка неохоче ставилася до виплатів і не має конкурентоспроможності для бізнесу, який має низьку націнку.
Китай захопив дуже велику частину всієї обробки частини ланцюга вартості для критичних мінералів. Індія також повинна стати обробним центром. Уряд може придумати прогресивну політику, включаючи легкий доступ до землі, швидкі дозволи та певну підтримку виробництва, що належать вітчизняним чи іноземним інвесторам.
Також читайте:Повернення доходів завищення повинно бути закликом до пробудження для тих, хто керує індійською економікою
Уроки з Аргентини
Нещодавній досвід Аргентини у використанні нафти зСланцевий басейн Ваки Муерта також проводить важливі уроки. Відбулося масове підвищення результатів з того часу, коли Майлі став президентом. І це багато в чому через новий режим політики, який регулює всі великі інвестиції, включаючи нафту. Режим осей більшість аспектів урядового контролю, включаючи обмеження цін та обмеження щодо репатріації прибутку. Але суттєво це гарантує регуляторну стабільність та податкові пільги протягом 30 років. Помірний фіскальний режим з довгостроковою визначеністю є ключовим для зростання цього сектору.
Уряд Індії вніс внесення змін до своїх законів на нафту, щоб узгодити їх із світовими найкращими стандартами. Вперше це визначить пріоритет виробництва над доходом. Якщо це може скоротити час, необхідний для пробілів або перейти до системи самоцертифікації, Індія ще могла б мати нафтогазовий бум, більший за Аргентину.
Важливість розблокування сектору ресурсів полягає в збільшенні, який він може надати ВВП, робочих місцях та доходів уряду. Насправді президент Майлі бере участь у доходах, отриманих від сектору ресурсів, щоб підтримати бюджет Аргентини та створити фіскальну кімнату, щоб придушити вплив його жорстких структурних реформ.
Для Індії, яка завжди стикається з тиском на фіскальному фронті, розблокування повного ресурсного потенціалу Індії може створити простір для більшої кількості витрат. На честь уряду, він дуже відповідав за фіскальне управління, але, враховуючи часті заклики до добробуту, додаткові ресурси (без збільшення податків на приватних осіб чи компаній) можуть допомогти стійким витратам, а в свою чергу, допомогти створити більш родючі підстави для наступного раунду ринкових реформ.
Автор – головний економіст, Веданта. Його ручка X – @nayyardhiraj. Погляди є особистими.
Білки працюють у координації для каталізації та регулювання всіх біологічних активності та керування клітинними функціями. Колективна поведінка білків вивчається за допомогою білкових-білкових взаємодії (PPI), які забезпечують розуміння їх регуляторної поведінки. Konnect2Prot (K2P)-це веб-додаток, який генерує специфічну для контекстної мережі PPI з списку білків як введення. Він визначає впливові розповсюджувачі у створеній мережі та виявляє їх біологічне та топологічне значення. Тут ми повідомляємо про функції, додані до K2P з першого випуску. Спираючись на основу свого попередника, K2P 2.0 тепер інтегрує диференціальний аналіз експресії генів, тим самим подолавши розрив між регуляцією генів та активністю на рівні білка, забезпечуючи цілісний погляд на те, як транскрипція змінює поведінку паливних клітин. Konnect2Prot 2.0 вільно доступний за адресою: https://konnect2prot_v2.thsti.in.
Нові продажі автомобілів Tesla у Британії зросли щорічно в червні на тлі більш широкого відновлення на ринку електромобілів, що показали дані, показані в п'ятницю, оскільки минулого місяця американський виробник розпочав доставку своєї оновленої моделі y.
В цілому, нова реєстрація автомобілів у Великобританії зросла на 6,7% у червні з року раніше до 191 316 одиниць, повідомляє Товариство виробників та торговців, або SMMT, у звіті, що посилюється попитом на електромобілі з акумулятора.
Незважаючи на те, що продажі залишалися нижче рівня до ковистів, це був найкращий червень з 2019 року. Попит на електромобілі акумулятора зросла на 39% до 47 354 одиниць, причому кожен з яких покупці стали електричними, повідомляє SMMT.
Tesla побачив свої найкращі продажі у червні у Великобританії з 2019 року, повідомили Товариство виробників та торговців. William – Quard.adobe.com
“Однак, що зростання EV все ще зумовлюється значною підтримкою галузі з виробниками, які використовують кожен канал та нестійкі знижки для підвищення активності, але вона залишається нижче рівнів мандатів”, – заявив у звіті виконавчий директор SMMT Майк Хоуз.
У червні Tesla продала 7 719 одиниць, що на 14% порівняно з роком раніше, повідомляє SMMT. Дані дослідницької групи New Automotive на початку дня показали збільшення на 12% у червні до 7 891 одиниць.
SMMT та New Automotive використовують різні джерела даних та методи розрахунку, пояснюючи відмінності в опублікованих малюнках.
Незважаючи на зростання в червні, продажі у Великобританії Tesla досі знизилися майже на 2% цього року, тоді як суперники китайського суперника збільшилися майже в чотири рази до 2498 одиниць, повідомляє New Automotive.
Минулого місяця Tesla продала 7 719 транспортних засобів у Великобританії. Рейтерс
У першій половині 2025 року продажі американського автовиробника Ford зросли найшвидше серед своїх конкурентів у Британії, зросли більше ніж у чотири рази з роком раніше, заявив New Automotive.
“Подальше зростання продажів та сектор покладатимуться на збільшення та вдосконалених зарядних приміщень для збільшення основного прийняття електромобілів”, – сказав Джеймі Гамільтон, автомобільний партнер та керівник електромобілів у Deloitte.
Торгова угода США-UK знизить деякі тарифи на імпорт з Британії, у тому числі для британських виробників автомобілів, які тепер зможуть експортувати до США за зниженою 10% тарифною квотою з попередніх 27,5%, набули чинності на цьому тижні.
Рула Халаф, редактор FT, вибирає свої улюблені історії в цьому щотижневому бюлетені.
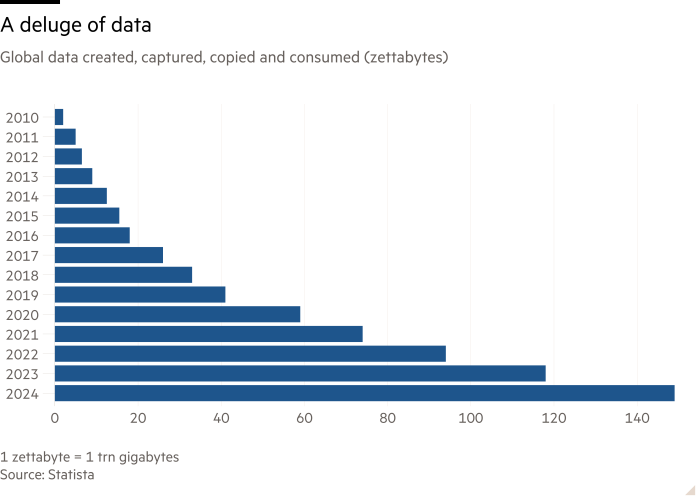
Уряд Великобританії хоче продати анонімізовані публічні дані. Це має сенс. Є багато, і більше накопичується щохвилини. Зробивши дохід промисловості, Європейська комісія проектує, що компанії Великобританії отримають дохід у розмірі 30 млрд. Євро в цьому році; Додайте в ЄС, і це 145 млрд. Євро.
Що стосується урядів, то як вони можуть поставити ціну на інформацію? Дані можуть бути нафтою цього століття, але воно не надходить у бочки за щоденною ціною. Нафта коштує однаково, чи є покупець авіакомпанія чи виробник іграшок; Значення даних часто диктується тим, як воно буде використовуватися. Він не вичерпається і “не є суперним”, тобто заданий набір даних може використовуватися одночасно декількома сторонами.
Є також часове значення даних. Один із прикладів: дані, на які можна діяти на ринках капіталу, мають максимальну корисність – і прибуток – для тих, хто може спершу діяти на ньому.
Так чи інакше, це вигідно. Gartner, американська консультація, яка живе поза його даними та дослідницькими можливостями, кремує валову маржу 74 відсотків у сегменті. Це така прибутковість, пов’язана з недорогими підприємствами, такими як програмне забезпечення Enterprise, де користувачі, як правило, сплачують періодичні збори, а вартість додавання нового клієнта незначна.
Пристосовано, постачальники даних, що рекламують як послугу (DAAS). Це найкраще працює на моделі підписки, кращим маршрутом для постачальників даних, що стосуються галузі, таких як Bloomberg для фінансів або подібних до Nielsen для реклами. Усі, крім декількох відсоткових пунктів доходів від досліджень Gartner, також надходять з цього джерела.
Деякі урядові дані можуть бути придатними і для продажу на цій основі. Інші, менш високочастотні дані можуть не-наприклад, заплановані 137-МН-динозавр та інші зразки, що оцифровувались у Музеї природознавства. Навіть, здавалося б, основні набори даних несуть великі витрати: оцифрування аналогових записів, догляд за центром обробки даних та використання датчиків або інших інструментів для зйомки інформації.
Ключовим завданням буде створення обміну даними, який дозволяє постачальникам даних та користувачам знайти певну ціну очищення. Це в ідеалі буде коефіцієнт змінних, таких як вартість виробництва, обслуговування та цінність для кінцевих користувачів, що дозволяє орієнтуватися на дані.
Зусилля щодо розвитку таких бірж ще не мають набути тяги. У Китаї є багато, де дані розглядаються як фактор виробництва поряд із землею та працею, але обсяги є самотворними. Глобальна біржа великих даних Guiyang Glober Guiyang-одна з близько 50 в китайській провінції-набрала майже той самий оборот у своїй десятирічній історії, що й за тиждень або близько того.
Природно, ніхто не настільки вмілий у даних про соки, як велика техніка. Наприклад, мета -платформи переходять від обслуговування даних користувачів до рекламодавців до виконання всього самого шебангу – розгортання штучного інтелекту для написання та ілюстрації оголошень, пристосованих до користувачів на основі їх даних. Цей варіант не відкритий для урядів. І все -таки, якщо ви не можете їх перемогти, надання їм цифрових виборів та лопат – це досить гарна друга найкраща.