Казначейські операції В Азії, особливо Південно -Східній Азії, у 2025 та 2026 роках переходять у складний і розвивається ландшафт, що формується економічними, геополітичними та технологічними силами. У регіоні спостерігається ослаблення інфляції та процентних ставок, але залишається оскарженим посиленою геополітичною напругою, особливо між США та Китаєм, які впливають на нестабільність валюти та стратегії ланцюгів поставок.
Ринки облігацій в Азії демонструють позитивні основи, але стикаються з уразливістю від фіскального дефіциту та боргових ризиків. Функції казначейства Потрібно адаптуватися до зростання кіберзагроз, вимог цифрової трансформації та складності управління грошовим потоком у різних юрисдикціях.
Одночасно виникають можливості з посилення діяльності з МіО, галузеві зміщення до технології та інфраструктури та інноваційних методів фінансування, таких як зелене фінансування та структури альтернативних угод. Щоб досягти успіху, лідери казначейства повинні підвищити управління ризиками, оптимізувати структури капіталу та розвивати таланти з новими навичками для підтримки стійкості та захоплення перспектив зростання.
Трансформація казначейства та цифровізація
Наміт КамраФінансовий директор PT Indorama Polychem Indonesia та кантрі -лідерство корпоративного банкінгу, казначейства та ризиків для Indorama Ventures (Індонезійські дочірні компанії),Зауважує, що казначейські функції в Азії зазнають значної трансформації, керованої технологічним прогресом та розвиваються економічними умовами.
“Компанії все частіше приймають цифрові інструменти для поліпшення прогнозування грошових потоків, автоматизації примирення та ефективнішого управління ліквідністю”, – додає він. Він підкреслює появу інформаційних панелей, що підтримуються AI, які забезпечують видимість грошових коштів у режимі реального часу та динамічний аналіз сценаріїв, що дозволяє більш обґрунтоване прийняття рішень у мінливих умовах.
Камра підкреслює: “Якщо готівка є королем, дані є королевою; нам потрібно гарантувати, що ми оптимально керуємо грошовими коштами, і даними. Користувачі та ті, хто приймає рішення, переходять від просто даних до” даних у режимі реального часу “-для швидшого та точного прийняття рішень”.
Він зазначає, що функції казначейства стають більш розумними та більш автоматизованими з припливом програмного забезпечення та допоміжними інструментами; “Хоча темп все ще потрібно підібрати, проте напрямок ідеальний. Розумні та інтелектуальні казначейські рішення доступні та отримувати все більше і більше прийнятності користувачами”.
Що стосується масштабованості, він вважає, що є великі взуття для заповнення, а Азія має довгий шлях.
Управління ліквідністю на тлі полегшення процентних ставок
Оскільки процентні ставки, як очікується, полегшать на таких ринках, як Індонезія, Камра радить казначейським командам зосередитись на покращенні грошовий потік Прогнозування точності та переоцінки Інвестиційна політика. Він рекомендує використовувати вдосконалені інструменти прогнозування, інтегровані з даними в режимі реального часу, для покращення прогнозів грошових потоків та більш ефективного виділення коштів.
“Крім того, диверсифікація на дещо довгострокові або вищі придатні інструменти, такі як короткочасні облігації або високоякісний комерційний папір, можуть запропонувати кращу віддачу, зберігаючи надійні рамки управління ризиками”,-продовжує він.
Камра підкреслює, що оптимізація ліквідності виходить за рамки швидкого перетворення грошових коштів від продажів; Він охоплює управління обома сторонами балансу – оплата, дебіторська заборгованість, оборот товару, надлишок розгортання грошових коштів та управління капітальними витратами.
“Управління ліквідністю зараз спостерігається в тандемі з ефективністю оборотного капіталу”, – каже він, підкреслюючи важливість таких показників, як коефіцієнт DSO, DPO та DIO. “Сказавши, що будь -який цикл процентних ставок, оптимальне використання ліквідності має ключове значення”, – додає він.
Пом'якшення ризиків від напруженості США та нестабільності валюти
Постійна торговельна напруженість США вводить значні ризики для азіатського бізнесу. Камра радить фахівців з казначейства застосовувати динамічні стратегії хеджування, використовуючи форвардні контракти та варіанти для пом'якшення впливу валюти.
Він також рекомендує диверсифікувати ланцюги поставок та вивчати альтернативні ринки для зменшення залежності від мінливих регіонів, зміна, яка може представляти зміну парадигми, якщо напруга посилюється.
Наміт Камра
“Динаміка ланцюгів поставок змінюється, і корпорації намагаються перенести канали закупівель та поставок з однієї країни в іншу, навіть від одного континенту на інший. Це буде зміна парадигми, якщо напруга посилиться.” Наміт Камра
Враховуючи послаблення долара та мінливості США у таких валютах, як індонезійська рупія, своєчасне та точне вимірювання ризику та хеджування ризику є критичними.
Використання цифрової трансформації для ефективності казначейства
Цифрова трансформація революціонізує казначейські операції в Азії. Kamra висвітлює інновації Fintech, які дозволяють виплати в режимі реального часу, автоматизоване примирення та прогнозовану аналітику для динамічного управління ризиками. Інтеграційні платформи, що з'єднують ERP та банки, забезпечують безперебійні, в режимі реального часу, посилюючи прийняття рішень.
“Моделі ризику, орієнтовані на AI, що працюють на даних, використовуючи ML, NLP та інші методи AI, підтримують моделі прогнозування ризику ліквідності, прогнозування майбутніх грошових потоків та підвищення тривоги дефіциту ліквідності та пасток, які очікуються в майбутньому”,-висловлює Камра.
“Інтеграційні платформи, що з'єднують ERP та банки, забезпечують безперебійні розуміння в режимі реального часу, що покращують прийняття рішень. Моделі ризику, що працюють на AI, використовуючи машинне навчання та обробку природних мов підтримують ризику ліквідності та попередження казначейських команд про потенційні дефіцит”. Наміт Камра
Для мультирусдикційних операцій надійна дисципліна казначейства є важливою, включаючи належні валютні огорожі, використання міжміських фондів та пов'язане з ними фінансування партії.
З точки зору Поліпшення грошових потоківвін зауважує, що функція казначейства розвивається, щоб включити цілісний підхід з інтеграцією в режимі реального часу з банками “через API з відкритим банкінгом, що дозволяє прямувати банківські канали та швидкі GPI, що дозволяють відстежувати платежі в режимі реального часу для транскордонних операцій”.
Посилення кібербезпеки та запобігання шахрайству
З кібератаками та фінансовим шахрайством, що піднімається, Камра підкреслює необхідність надійних заходів кібербезпеки. Безпечні платіжні системи, що поєднують дозволений блокчейн з цифровими валютами Центрального банку, можуть підвищити безпеку транзакцій та ефективність роботи. “Регулярне навчання для працівників казначейства є життєво важливим для визнання та пом'якшення загроз”, – продовжує він.
Kamra висвітлює останні напади викупу в Індонезії як попередження та наголошує на важливості системного контролю для запобігання вигаданих грошових переказів, дублікатів платежів та ризиків оплати. “Крім того, захист даних набирає тягу не тільки з корпоративної сторони, але і з регуляторами, які придумують суворі та чіткі правила з цього приводу. Нам потрібно серйозно сприймати захист даних та забезпечити дотримання його повного”, – стверджує він.
Врівноваження зростання M&A з фінансовою стійкістю
Камра підкреслює важливість фінансової дисципліни та стратегічної ясності при переслідуванні зростання M&A. Придбання повинно узгоджуватися з довгостроковими цілями та пріоритетами капіталу.
“Сувора належна ретельність, чітке розуміння ризиків інтеграції та розсудливе управління ліквідністю є основоположними для забезпечення того, щоб ініціативи щодо зростання не загрожують нашій фінансової стійкості”, – продовжує він.
Він додає, що інтеграція після змагань повинна зосередитись на захопленні синергій та оперативної ефективності для забезпечення стійкої вартості акціонерів.
Зв'язок з розривами талантів та підвищення кваліфікації казначейських команд
Еволюціонуючий казначейський ландшафт вимагає постійного підвищення кваліфікації. Камра зазначає, що фахівці з казначейства повинні поєднувати знання фінансів з технологічною здатністю.
“Еволюціонуючий ландшафт казначейських операцій потребує постійного підвищення кваліфікації казначейських команд. Інвестування в навчальні програми, орієнтовані на аналітику даних, просунуті методи прогнозування та використання Системи управління скарбницями (TMS) є важливим, – каже Камра.
Крім того, він вважає, що співпраця з навчальними закладами та галузевими органами може надавати спеціалізовані курси та сертифікати. Камра називає це “модернізацією навчання та талантів” необхідним для майбутньої готовності.
Оптимізація банківських відносин на тлі зростання процентних ставок
У середовищі з високою процентною ставкою Камра радить казначейським командам застосовувати проактивний та стратегічний підхід до ліквідності та управління ризиками. “Залучення рано та послідовно з нашими банківськими партнерами дозволяє нам забезпечити конкурентні умови як для фінансування, так і для хеджування”.
Регулярні огляди банківських структур та розвитку ринку забезпечують стратегії капіталу, які залишаються економічно вигідними та узгоджуються з цілями зростання. Він наголошує на критичному важливості всебічного хеджування для багатоквартирної та багаторічної експозиції.
Адаптація до тривалих високих процентних ставок та інфляції
Камра визнає, що стійкість високих процентних ставок з 2022 року збільшила витрати на казначейство та уповільнила інвестиції в капітал. Однак деякі економіки починають бачити зниження ставок. Інфляція переважно під контролем, за винятком деяких країн.
Для підтримки операційної ефективності казначери повинні оптимізувати оборотні кошти, розширюючи умови оплати постачальників, прискорення дебіторської заборгованості та зменшення запасів. “Крім того, переоцінка планів капітальних витрат та визначення пріоритетів інвестицій, які пропонують найвищу віддачу, можуть допомогти пом'якшити вплив інфляції на прибутковість”, – додає він.
Він стверджує, що співпраця серед казначей, банків, регуляторів та постачальників фінтехів є важливим для розробки стійких рішень.
Що стосується впливу на динаміку казначейства, Камра твердо вірить у нові тенденції, такі як децентралізовані фінанси, Автоматизовані інструменти торгівлі фінансуваннярозумні контракти, CRM-системи, керовані AI та блокчейн у ланцюгах поставок. “Це могло б зробити чудеса, якщо добре адаптується з конфіденційністю даних та кібербезпекою, добре охопленими”, – продовжує він.
Більш широкий ринок контекст
Підтримуючи відомості Камри, звіт Азіатського банку розвитку в червні 2024 р. Про розвиток ринку облігацій зазначає, що ринки облігацій Південно -Східної Азії розширюються, але залишаються відносно невеликими порівняно з рисами інших економік Східної Азії.
Видача державних облігацій В ASEAN значно збільшився в 1 кварталі 2024 року, керовані такими країнами, як Філіппіни. Тим часом ринки корпоративних облігацій показали відновлення, підтримуване виданням у Китаї, Гонконгу та Сінгапурі. Однак фіскальний дефіцит та ризики боргу залишаються занепокоєнням, які можуть вплинути на стабільність ринку.
Розширена аналітика, ШІ та автоматизація стають важливими, оскільки платники стикаються
Нью -Йорк, 1 червня 2025 р. (Newswire.com) –
Оскільки платники охорони здоров’я стикаються з посиленим регуляторним наглядом, зростанням витрат на охорону здоров'я та розвиваються складності коригування ризику, дослідження Black Book сьогодні оголосили про свої 2025 рейтинг провідних постачальників програмного забезпечення для коригування ризиків та кодування. Ці рішення стали важливими для платників, які шукають точних, сумісних та фінансово оптимізованих практик кодування через Medicare Advantage, медичну допомогу, плани ринку ACA та комерційних страховиків.
Згідно з останнім опитуванням платників Black Book, проведеним між Q4 2024 та Q1 2025, з відповідями від 1,108 старших керівників платників, фінансових службовців та лідерів коригування ризиків, 92% вказали на те, що вдосконалена аналітика та інструменти штучного інтелекту (AI) зараз є критичними для точного оцінювання ризику, покращеної ефективності кодування та підтримки реалізації.
“Плани охорони здоров'я терміново інвестують у технологічні рішення, які забезпечують точні, прогнозні та повністю сумісні практики коригування та кодування ризику”, – сказав Дуг Браун, президент Black Book Research. “Оптимізоване кодування не тільки забезпечує дотримання регуляторних норм, але суттєво впливає на фінансову стабільність, розподіл ресурсів та якість догляду за членами”.
Обсяг та можливість програмного забезпечення для регулювання ризику та кодування оптимізації
Опитування підкреслює зростаючий акцент на декількох основних сферах, де рішення для програмного забезпечення платників можуть різко підвищити продуктивність:
Точний оцінка ризику: 94% респондентів підкреслили точність у HCC (ієрархічних умовах) та RAF (коефіцієнт коригування ризику), оцінюючи як найвищий пріоритет.
Відповідність регулювання: 89% підкреслили важливість програмного забезпечення, здатного до постійного моніторингу відповідності, автоматизованих аудитів та перевірки кодування.
Прогнозування аналітики: 87% платників надають пріоритетні розвинені рішення аналітики, які передбачають ризик та дозволяють проактивне управління групами населення.
Автоматизовані процеси кодування: 70% відзначили необхідність автоматизації для зменшення помилок вручну, впорядкування робочих процесів та прискорення точності кодування.
Сумісність та інтеграція даних: 66% повідомили про сумісність як необхідну, забезпечуючи безперебійний потік даних серед постачальників, платників та регуляторних органів.
Топ -10 постачальників коригування ризику та оптимізації кодування (рейтинг за задоволеністю клієнтів та продуктивністю)
Edifecs – Розрізняли свої надійні рішення щодо взаємодії та аналітику коригування ризику в режимі реального часу, які впорядковують робочі процеси платників та забезпечують регуляторну точність.
Апіксіо – Визнаний своєю аналітикою коригування ризику AI, використовуючи обробку природної мови (NLP) для різкого покращення точності кодування та стратифікації ризику.
Scio Health Analytics (EXL) – Високо оцінений для прогнозного моделювання та всебічних інструментів аналітики, які значно підвищують точність кодування, фінансове прогнозування та управління відповідністю.
Адвокат – похвалили свою інтегровану платформу коригування ризику, пропонуючи аналітику в режимі реального часу, автоматизовані огляди діаграм та прогнозну ідентифікацію ризику.
Змінити охорону здоров'я – оцінюється для складних можливостей оптимізації кодування та аналітики, значно зменшуючи ризики аудиту та підвищення точності доходу.
Інновацер – Відзначено для розширеної аналітики та інтегрованих робочих процесів, які безперешкодно з'єднують потоки даних платників, оптимізуючи стратегії управління ризиками.
Незайманий – Аплодують на масштабовані платформи аналітики та комплексну сумісність, підвищення точності в оцінці ризику та дотримання нормативних норм.
Коттити – Визнаний за його глибоку аналітику та точну перевірку даних, що дозволяє платникам точно фіксувати ризик та впорядкувати дотримання кодування.
З – Визнаний за надійні засоби коригування ризику та кодування ризику, які безперешкодно інтегруються в системах платників, забезпечуючи точність та дотримання.
Талікс – Відомий своїми інноваційними рішеннями з коригування ризику, орієнтованими на NLP, які забезпечують точне кодування, зменшення ризику дотримання та максимізації цілісності доходу.
“Програмне забезпечення з коригування ризику та кодування оптимізації стало стратегічним імперативом для платників, спрямованих на процвітання в сучасному регуляторному та конкурентному середовищі охорони здоров'я”, – додав Браун. “Використання цих технологій позичає платників не лише для досягнення відповідності, але для реалізації суттєвих вдосконалень фінансових результатів, ефективності операцій та управління охороною здоров'я.”
Про дослідження чорної книги
Дослідження Black Book забезпечують неупереджену, що стосується натовпу, що стосується технологій охорони здоров’я, послуг та аутсорсингу. Починаючи з 2004 року, Black Book опитувала понад 1 мільйон користувачів та покупців технологій охорони здоров’я, підтримуючи сувору незалежність без фінансування постачальників, консультаційних підписки або домовленостей щодо підвищення продуктивності. Щоб ліцензувати повний повний звіт про коригування ризику та кодування 2025 р. Та детальні показники продуктивності постачальника, відвідайте: https://blackbookmarketresearch.com
Порушення даних – це вже не рідкісні події, а постійна проблема.
Ми спостерігаємо регулярні інциденти в державних компаніях у різних секторах, включаючи охорону здоров'я, роздрібну торгівлю та фінанси. Хоча погані актори, безумовно, винні, ці корпорації не повністю без вини. Вони часто полегшують хакерам доступу до даних користувачів, не в змозі їх належним чином захистити.
Нещодавній приклад з'явився, коли дослідник кібербезпеки виявив відкриту базу даних, що містить понад 184 мільйони облікових даних.
Приєднуйтесь до безкоштовного звіту Cyberguy: Отримайте мої експертні поради, критичні сповіщення про безпеку та ексклюзивні угоди – плюс миттєвий доступ до мого безкоштовного посібника з виживання в Ultimate Scam, коли ви зареєструєтесь!
Ілюстрація хакера на роботі.(Курт “Кібергуй” Кнаутссон)
Як була розкрита база даних і що вона містила
Дослідник кібербезпеки Єремія Фаулер має виявлений Наявність відкритої бази даних, що містить 184,162,718 мільйонів облікових даних. Сюди входять адреси електронної пошти, паролі, імена користувачів та URL -адреси для платформ, таких як Google, Microsoft, Apple, Facebook та Snapchat.
Інформація також охоплює банківські послуги, медичні платформи та державні рахунки. Найбільш шокуюче, весь набір даних залишався абсолютно незабезпеченим. Не було ні шифрування, не потрібно аутентифікації та не було форми контролю доступу. Це був просто звичайний текстовий файл, який сидів в Інтернеті, щоб хтось знайшов.
19 мільярдів паролів просочилися в Інтернеті: як захистити себе
Фаулер розмістив базу даних під час звичайного сканування публічно оголених активів. Те, що він знайшов, було приголомшливим. Файл включав сотні мільйонів унікальних записів, що містять облікові дані користувачів, пов'язані з найбільшими в світі технологічними та комунікаційними платформами. Були також реквізити облікових записів щодо фінансових послуг та офіційних порталів, якими користуються державні установи.
Файл не був захищений жодним чином. Кожен, хто виявив посилання, може відкрити його в браузері та миттєво переглядати конфіденційні особисті дані. Жодна програмна експлуатація не потрібна. Жодного пароля просили. Він був таким же відкритим, як публічний документ.
Ілюстрація хакера на роботі.(Курт “Кібергуй” Кнаутссон)
200 мільйонів записів соціальних медіа просочилися в основному порушенні даних X
Звідки взялися дані
Фаулер вважає, що дані були зібрані за допомогою Infostealer. Цим легким інструментам надають перевагу кіберзлочинці за їх здатність мовчки витягти облікові дані входу та іншу приватну інформацію з компрометованих пристроїв. Після викрадення дані часто продаються на темних веб -форумах або використовуються в цільових атаках.
Після повідомлення про порушення постачальник хостингу швидко видалив доступ до файлу. Однак власник бази даних залишається невідомим. Постачальник не розголосив, хто його завантажив, чи база даних є частиною законного архіву, який був випадково опублікований. Фаулер не міг визначити, чи це результат недбалості чи операції з шкідливим наміром.
Щоб перевірити дані, Фаулер зв’язався з деякими особами, переліченими у записах. Кілька підтвердили, що інформація була точною. Це підтвердження перетворює те, що може здатися абстрактною статистикою, на щось дуже реальне. Вони не були застарілими або неактуальними деталями. Це були живі дані, які могли дозволити кожному викрадати особисті рахунки за лічені секунди.
1,7 мільярда паролів просочилися в темній павутині, і чому ваш ризикує
Увійдіть на планшет.(Курт “Кібергуй” Кнаутссон)
Фірма з персоналу підтверджує 4 -метрові записи, викриті у великому хакі
6 способів захистити себе після порушення даних
1. Змініть свій пароль на кожній платформі: Якщо ваші облікові дані входу були викриті, недостатньо змінити пароль лише на одному обліковому записі. Кіберзлочинці часто намагаються однакові комбінації на різних платформах, сподіваючись отримати доступ через повторно використані облікові дані. Почніть з оновлення найважливіших облікових записів, електронної пошти, банкінгу, хмарного зберігання та соціальних медіа, а потім перейдіть до інших. Використовуйте новий, унікальний пароль для кожної платформи та уникайте варіацій старих паролів, оскільки вони все ще можуть бути передбачуваними. Подумайте про використання a Менеджер паролів Для створення та зберігання складних паролів.
Наш Менеджер паролів з рейтингом забезпечує потужний захист, щоб допомогти захистити ваші рахунки. Він має Моніторинг порушення даних у режимі реального часу Щоб попередити вас, чи були оголені деталі вашого входу, плюс вбудований Сканер порушення даних Це перевіряє збережені електронні листи, паролі та інформацію про кредитну карту проти відомих баз даних витоку. Перевірка здоров’я пароля також виділяє слабкі, повторно використані або компрометовані паролі, щоб ви могли зміцнити свої онлайн -захисні сили лише кількома кліками. Отримайте більше деталей про мою Найкращі рецензовані експерти з менеджерів паролів 2025 тут.
2. Увімкніть двофакторну автентифікацію: Двофакторна автентифікаціяабо 2FA – це критична функція безпеки, яка різко знижує ризик несанкціонованого доступу. Навіть якщо у когось є ваш пароль, він не зможе увійти без другого кроку перевірки, як правило, одноразовий код, надісланий на ваш телефон або додаток автентифікатора. Увімкніть 2FA про всі послуги, які підтримують його, особливо вашу електронну пошту, фінансові рахунки та будь -яка послуга, яка зберігає конфіденційні персональні дані.
3. Слідкуйте за незвичайною діяльністю облікового запису: Після порушення поширене, щоб компрометовані рахунки використовувались для спаму, афери чи крадіжок особи. Зверніть пильну увагу на такі знаки, як спроби входу з незнайомих місць, запити на скидання пароля Ви не ініціювали або несподівані повідомлення, надіслані з ваших облікових записів. Більшість платформ дозволяють переглянути історію входу та підключені пристрої. Якщо ви щось бачите, негайно вживайте заходів, змінивши пароль і відкликавши підозрілі сеанси.
4. Інвестуйте в послуги з видалення персональних даних: Ви також повинні розглянути службу видалення даних. Враховуючи масштаб і частоту порушень, як описані вище, покладатися лише на особисту обережність, вже недостатньо. Автоматизовані послуги з видалення даних можуть забезпечити важливий додатковий рівень оборони, постійно скануючи та допомагаючи усунути вашу оголену інформацію від веб -сайтів брокера даних та інших інтернет -джерел. Хоча жодна послуга не обіцяє видалити всі ваші дані з Інтернету, наявність послуги з видалення – це чудово, якщо ви хочете постійно контролювати та автоматизувати процес видалення вашої інформації з сотень сайтів постійно протягом більш тривалого періоду часу. Перегляньте мої найкращі вибори для служб видалення даних тут.
Отримати Безкоштовне сканування Щоб дізнатися, чи ваша особиста інформація вже в Інтернеті.
5. Уникайте натискання на підозрілі посилання та використовуйте сильне антивірусне програмне забезпечення: Однією з найпоширеніших загроз після порушення є фішинг. Кіберзлочинці часто використовують інформацію з просочених баз даних для розробки переконливих електронних листів, які закликають вас перевірити свій обліковий запис або скинути пароль. Ніколи не натисніть на посилання або завантажуйте вкладення з невідомими чи підозрілими джерелами. Натомість відвідайте веб -сайти, ввівши URL -адресу безпосередньо у свій браузер.
Найкращий спосіб захистити себе від шкідливих посилань – це встановити сильне антивірусне програмне забезпечення, встановлене на всіх ваших пристроях. Цей захист також може попередити вас про фішинг -електронні листи та афери викупу, зберігаючи вашу особисту інформацію та цифрові активи в безпеці. Отримайте мої вибори для найкращих переможців захисту від антивірусу 2025 для пристроїв Windows, Mac, Android та iOS.
6. Оновлюйте своє програмне забезпечення та пристрої: Багато кібератак використовують відомі вразливості в застарілому програмному забезпеченні. Операційні системи, браузери, антивірусні програми та навіть додатки потрібно регулярно оновлювати для виправлення недоліків безпеки. Увімкніть автоматичні оновлення, де це можливо, щоб ви захищались, як тільки виправиться. Залишатися з вашим програмним забезпеченням – це один з найпростіших та найефективніших способів блокувати зловмисне програмне забезпечення, викупне програмне забезпечення та шпигунство від проникнення вашої системи.
Хакери, що використовують зловмисне програмне забезпечення для викрадення даних з флеш -накопичувачів USB
КЛЮЧ КОРТУВАННЯ
Безпека – це не лише відповідальність компаній та хостинг -провайдерів. Користувачі повинні приймати кращі практики, включаючи унікальні паролі, багатофакторну автентифікацію та регулярні огляди їх цифрового сліду. Небажане опромінення понад 184 мільйони облікових даних – це не просто помилка. Це приклад того, наскільки крихкі наші системи залишаються, коли навіть базовий захист відсутній. В епоху, коли штучний інтелект, квантові обчислення та глобальне підключення є переробкою технології, неприпустимо, що звичайні текстові файли, що містять фінансові та урядові облікові дані, все ще залишаються сидіти в Інтернеті.
Клацніть тут, щоб отримати додаток Fox News
Чи відчуваєте ви, що компанії роблять достатньо, щоб захистити ваші дані від хакерів та інших кіберзагроз? Повідомте нас, написавши нас наCyberguy.com/contact
Щоб отримати більше моїх технічних порад та сповіщень про безпеку, підпишіться на мій бюлетень з доповіді про Cyberguy, відправившись до Cyberguy.com/newsletter
Задавайте Курта або дайте нам знати, які історії ви хотіли б висвітлювати.
Слідкуйте за Куртом на його соціальних каналах:
Відповіді на найзахисніші запитання кібергуї:
Новий від Курта:
Copyright 2025 Cyberguy.com. Усі права захищені.
Курт “Cyberguy” Knutsson-це нагородний технологічний журналіст, який має глибоку любов до технологій, спорядження та гаджетів, які покращують життя завдяки своєму внеску в Box News & Fox Business, починаючи з ранку на “Fox & Friends”. Отримали технічне запитання? Отримайте безкоштовний інформаційний бюлетень Курта, поділіться своїм голосом, ідеєю історії чи коментарем на Cyberguy.com.
Приєднуйтесь до наших щоденних та щотижневих бюлетенів для останніх оновлень та ексклюзивного контенту щодо провідного охоплення AI. Дізнайтеся більше
Token Monster, нова платформа AI Chatbot, запустила свій Alpha Preview, спрямований на зміну того, як користувачі взаємодіють з великими мовними моделями (LLMS).
Розроблений Меттом Шумером, співзасновником та генеральним директором InthersIeAi та його хітом помічника з написання AI HyperWrite AI, ключовою точкою продажу Token Monster є його здатність маршрутизувати користувача до найкращих доступних LLM для виконання завдань, що забезпечують розширені результати шляхом використання сильних сторін декількох моделей.
В даний час є сім основних LLMS через Token Monster. Після того, як користувач вводить щось у вікно оперативного входу, Token Monster використовує попередні програми, розроблені через ітературу самим Шумером для автоматичного аналізу введення користувача, вирішити, яка комбінація декількох доступних моделей та пов’язаних інструментів найкраще підходить для цього, а потім забезпечити комбіновану реагування на використання сильних сторін зазначених моделей. Доступні LLM включають:
Антропічний клод 3,5 сонет
Антропічний клод 3,5 опус
OpenAI GPT-4.1
OpenAI GPT-4o
Здивування AI PPLX (для досліджень)
OpenAI O3 (для міркувань)
Google Gemini 2.5 Pro
На відміну від інших платформ Chatbot, Token Monster автоматично визначає, який LLM найкраще підходить для конкретних завдань-а також які інструменти, підключені до LLM, були б корисними, такими як веб-пошук або середовище кодування-та оркеструє багатомодельний робочий процес.
“Ми просто будуємо роз'єми до всього, а потім система, яка вирішує, що використовувати, коли”, – сказав Шумер.
Наприклад, він може використовувати Claude для творчості, O3 для міркувань та PPLX для досліджень, серед інших. Цей підхід усуває необхідність користувачів для вибору правильної моделі для кожного підказки, спрощуючи процес для всіх, хто хоче якісних, індивідуальних результатів.
Основні моменти функції
Попередній перегляд Alpha, який наразі безкоштовно зареєструватися на tokenmonster.ai, дозволяє користувачам завантажувати діапазон типів файлів, включаючи Excel, PowerPoint та Docs.
Він також включає такі функції, як вилучення веб-сторінки, стійкі сеанси розмови та “швидкий режим”, який автоматично ставиться до найкращої моделі без введення користувача.
В основі монстра Token-OpenRouter, стороння служба, яка виступає в якості ворота до декількох LLM, і в яку Шюмер вклав невелику суму, за його визнанням.
Ця архітектура дозволяє Token Monster скористатися різноманітними моделями різних постачальників без необхідності створювати окремі інтеграції для кожного.
Ціни та доступність
На даний момент, Token Monster не стягує плоску щомісячну плату.
Натомість користувачі платять лише за жетони, які вони споживають за допомогою OpenRouter, що робить його гнучким для різного рівня використання.
За словами Шумера, ця модель надихнула Cline, інструментом, який дозволяє користувачам висококласних витрат отримати доступ до необмеженої потужності AI, що дозволяє їм досягти кращих результатів, просто використовуючи більш обчислювальні ресурси.
Багатоетапні робочі процеси дають більш багаті відповіді LLM
Робочі процеси AI Token Monster виходять за рамки простої оперативної маршрутизації.
В одному з прикладів чат -бот може розпочатися з етапу досліджень за допомогою API веб -пошуку, передати ці дані на O3 для ідентифікації інформаційних прогалин, а потім створити контур з Gemini 2.5 Pro, проекту текст з Claude Opus та вдосконалити його за допомогою Sonnet Claude 3.5.
Ця багатоетапна оркестрація розроблена для того, щоб надати більш багаті, більш повні відповіді, ніж один LLM, можливо, зможе генерувати самостійно.
Платформа також включає можливість збереження сеансів, при цьому дані надійно зберігаються за допомогою сервісної бази даних Supabase Online Source. Це гарантує, що користувачі можуть повернутися до поточних проектів, не втрачаючи своєї роботи, при цьому надаючи їм контроль над тим, які дані зберігаються та що є ефемерним.
Нетрадиційний генеральний директор
У помітному експерименті лідерство Token Monster було передано моделі Claude Antropic.
Шумер оголосив, що зобов’язаний дотримуватися кожного рішення, прийнятого “генеральним директором Клодом”, називаючи це тестом, щоб побачити, чи може AI ефективно керувати бізнесом.
“Або ми назавжди революціонізували керівництво, або зробили величезну помилку”, – написав він на X.
Виходить із суперечки 70-B суперечки
Запуск Token Monster настає менше ніж через рік після того, як Шумер зіткнувся з суперечкою щодо його запуску та остаточним втягуванням Meflection 70B, тонко налаштованою версією Meta's Llama 3.1, яка спочатку була рекламована як найбільш високоефективна модель з відкритим кодом у світі, але яка швидко стала підпорядкованою критиці та звинуваченням у третій частині, а також відновлювальними показниками.
Шумер вибачився і сказав, що проблеми народжуються з помилок, зроблених через швидкість. Епізод підкреслив виклики та ризики швидкого розвитку ШІ та важливість прозорості у випусках моделей.
Інтеграції MCP наступні
Шумер заявив, що його команда на Token Monster також вивчає нові можливості, такі як інтеграція з серверами протоколу контексту моделі (MCP), які дозволяють веб-сайтам та компаніям використовувати LLM використовувати свої знання, інструменти та продукти для досягнення завдань вищого порядку, ніж просто генерація тексту або зображень.
Це дозволило б Token Monster зв’язатися з внутрішніми даними та послугами користувача, відкритим можливостями для вирішення таких завдань, як управління квитками на підтримку клієнтів або взаємодіючи з іншими бізнес -системами.
Шумер підкреслив, що монстр Token все ще дуже сильно на ранніх стадіях. Незважаючи на те, що він вже підтримує набір потужних функцій, платформа залишається альфа -продуктом і, як очікується, побачить швидкі ітерації та оновлення, оскільки більше користувачів надають зворотній зв'язок. “Ми будемо продовжувати ітерувати і додавати речі”, – сказав він.
Перспективний експеримент
Для користувачів, які хочуть скористатися комбінованою потужністю декількох LLMS без клопоту перемикання моделі, Token Monster може стати привабливим вибором. Він призначений для роботи для людей, які не хочуть витрачати години на налаштування підказок або тестування різних моделей, натомість дозволяючи автоматизованій маршрутизації системи та багатоетапних робочих процесів обробляти складність.
У міру зростання можливостей Token Monster буде цікаво побачити, як користувачі та підприємства його приймають-і як його експеримент з каструлями управління AI-під керівництвом. Наразі це перспективне доповнення до швидко розширюваного ландшафту чатів та цифрових асистентів.
Щоденні уявлення про випадки використання бізнесу з VB щодня
Якщо ви хочете вразити свого начальника, VB Daily вас висвітлював. Ми даємо вам внутрішній совок про те, що роблять компанії з генеративним ШІ, від регуляторних змін до практичних розгортань, щоб ви могли поділитися розумінням для максимальної рентабельності інвестицій.
Прочитайте нашу політику конфіденційності
Дякуємо за підписку. Перегляньте більше інформаційних бюлетенів VB тут.
Редвуд-Сіті, штат Каліфорнія, 30 травня 2025 р.-Snorkel AI оголосив про загальну доступність двох нових пропозицій продуктів на платформі розробки даних Snorkel AI: Snorkel оцінювати та експерти з Snorkel AS-A-A-Service. Ці запускають свою місію, щоб перетворити знання на спеціалізовані AI – командні команди переходять від прототипу до виробництва в масштабі, використовуючи технологію розробки програм Snorkel AI.
Крім того, Snorkel AI оголосив, що зібрав 100 мільйонів доларів фінансування серії D за оцінкою 1,3 мільярда доларів на чолі з додаванням. Це нове фінансування сприятиме постійним дослідженням та інноваціям при оцінці та настройці спеціалізованих систем AI з експертними даними.
У той час як великі мовні моделі (LLM) пропонують величезний потенціал, підприємства не можуть впевнено розгорнути їх “з полиці” для спеціалізованих ділових випадків. За словами Gartner, до 2026 року організації, які не в змозі встановити масштабовані практики даних про ШІ, побачать, що понад 60% проектів ШІ покинуті. Досягнення AI, готових до виробництва, вимагають конкретних доменів даних для дрібнозернистої оцінки та методології налаштування моделі.
“Ми спостерігаємо сплеск імпульсу навколо агента АІ, але спеціалізовані агенти підприємства не готові до виробництва в більшості установок”,-сказав Алекс Ратнер, співзасновник та генеральний директор Snorkel AI. “Підприємствам потрібні дані, що стосуються домену та досвід, щоб зробити це реальністю. Ми раді забезпечити цю потребу та допомогти інноваторам AI розробити експертні дані, щоб залучити їхні LLM та агентські системи у виробництво з нашими новими пропозиціями, які завершують уніфікований стек розробки даних Snorkel”.
Оцініть підводку
Snorkel AI розширює свою платформу розробки даних AI із загальною доступністю оцінки Snorkel, що дозволяє користувачам будувати спеціалізовану, тонкозернисту оцінку моделей та агентів. Працюючи від унікального програмного підходу AI Snorkel AI до кураторних даних AI готових даних, ця нова пропозиція дозволяє підприємствам масштабувати свої робочі процеси оцінювання, щоб впевнено розгорнути системи AI на виробництво.
Оцінка Snorkel включає програмний інструмент для створення базових наборів даних, розробку спеціалізованих оцінювачів та корекції режиму помилок. Ці інструменти допомагають користувачам вийти за рамки загальних наборів даних та поза полицями підходи “LLM-AS-A-Judge” для ефективного побудови діючих оцінок, що стосуються домену.
“Щоб розблокувати повний потенціал Клода, нам потрібні нові підходи до оцінювання з доменним досвідом та відгуками людини”, – сказала Кейт Дженсен, керівник відділу доходів Anthropic. “Anthropic прагне працювати з інноваторами, такими як Snorkel AI, щоб забезпечити вдосконалення, надійні системи AI, надійні та узгоджені до потреб підприємств”.
Дані експертів Snorkel AS-A-Service
Expert Snorkel Expert Data-A-A-Service-це рішення з білої руки для доставки експертних наборів даних для оцінки системи та настройки кордонів AI на підприємства. Провідні розробники LLM вже співпрацюють з Snorkel AI для створення наборів даних для розширених міркувань, використання агенційних інструментів, взаємодії користувачів з багатоплином та знання, що стосуються домену.
Пропозиція поєднує мережу Snorkel з висококваліфікованих експертів з предметів з унікальною програмою технологічної платформи для маркування даних та контролю якості, що дозволяє ефективно доставити спеціалізовані набори даних. Snorkel Expert Data-A-A-Service оснащує підприємства для змішування внутрішніх знань та даних із власними наборами даних, розробленими за допомогою аутсорсингової експертизи.
Фінансування серії D Snorkel AI та імпульс ринку
Розгортання цих нових пропозицій підкреслює комерційний імпульс Snorkel AI. Сьогодні компанія також оголосила, що зібрала 100 мільйонів доларів на фінансування серії D за оцінкою 1,3 мільярда доларів, яку очолили додавання, за участю компанії Prosperity 7 Ventures, існуючих інвесторів Greylock та LightSpeed, та існуючих стратегічних інвесторів, включаючи BNY та QBE Ventures. Раунд приносить загальне фінансування Snorkel AI до 237 мільйонів доларів з моменту заснування в 2019 році. Цей новий капітал підтримує розширення компанії з її інженерних, досліджень та виїздів на ринок для своєї єдиної платформи розробки даних AI.
“З такими інноваціями, як оцінюють дані Snorkel Expert-AS-A Service та Snorkel, Snorkel AI дозволяє організаціям більш ефективно будувати моделі AI та забезпечити їх виконання на найвищих рівнях у спеціалізованих, реальних програмах”,-сказав Тодд Арфман, партнер на додаток. “Цей потужний, орієнтований на дані підхід прискорює розгортання надійного ШІ в масштабі-і ми з гордістю співпрацюємо з Snorkel AI, коли вони переосмислюють те, що можливо в AI Enterprise”.
Про Snorkel AI
Snorkel AI будує платформу розробки даних Snorkel AI для оцінки та настройки спеціалізованого AI у масштабі. Пропозиції Snorkel AI, включаючи Snorkel Evestation та Snorkel Expert Data-A-Service, прискорення оцінки та налаштування спеціалізованих систем AI з експертними даними-командні команди переходять від прототипу до виробництва в масштабі шляхом використання технології розробки програм Snorkel AI.
Дослідники Genomics England відіграли ключову роль у розробці нового інструменту штучного інтелекту, відомого як Savana, який використовує дані про довгі читання, щоб знайти конкретні зміни в ДНК людини, пов'язаної з раком. Інструмент може швидко та точно проаналізувати генетичну інформацію з зразків пацієнтів, щоб допомогти діагностувати рак та інформувати підходи до лікування.
ТЕХНОЛОГІЇ ДЛОГО ЧИТАННЯ ПОСЛІДЖЕННЯ ДЛЯ ДОГАТЕЛЬНОГО БЕЗПЕЧНОГО ДИСКУВАННЯ ДНК. Ці методи можуть покращити здібності дослідників виявити складні генетичні зміни геномів раку. Однак складна структура геномів раку означає, що стандартні інструменти аналізу можуть призвести до помилкових позитивних результатів та ненадійних інтерпретацій даних. Ці оманливі результати можуть поставити під загрозу розуміння того, як розвиваються пухлини, реагують на лікування та обмежити здібності до діагностики та лікування раку.
Дослідження під керівництвом Європейського інституту біоінформатики EMBL та опубліковано в Методи природиБув розроблений та протестований дослідниками Інституту разом з Genomics England у співпраці з клінічними партнерами в університетському коледжі Лондона, Королівській національній ортопедній лікарні, Інституто де Медикіна Молекулярна Жоао Лобо Антунес та Бостонська дитяча лікарня.
Дослідницька група порівнювала результати Савани з довгого читання з секвенуванням одних і тих же зразків, проаналізованих за допомогою конструкції аналізу даних цілого генома, який використовується для доставки клінічних звітів. Отримані результати були дуже послідовними в різних технологіях, демонструючи, що Савана працює нарівні з нинішніми клінічними стандартами, виявляючи додаткові зміни, що стосуються раку.
Genomics England досліджувала використання Савани як частину своєї роботи, розглядаючи клінічний потенціал довгого читання технології секвенування для підтримки раніше, більш швидкої діагностики раку, а також надання даних для дослідників для перевірки точності нового інструменту.
Це аудіо автоматично створене. Будь ласка, повідомте нас, якщо у вас є відгук.
Полозити короткий:
NVIDIA готується до постачання клієнтів підприємства за допомогою потужності AI обробки на тлі поспіху на розгортання агентських інструментів, заявив генеральний директор компанії Дженсен Хуанг під час заклику доходів за Q1 2026 року на тримісячний період, що закінчився 27 квітня.
“Дуже важко перенести дані кожної компанії в хмару, тому ми збираємось перемістити AI на підприємство”, – сказав Хуанг. “Ми побачимо, що AI перейде в Enterprise, який є на премії, тому що стільки даних все ще є на премії”.
Гігант GPU побачив, що щоквартальний дохід збільшився на 69% за рік до 44,1 мільярда доларів, коли рівень використання AI зросла. “Робочі навантаження AI сильно перейшли до висновку, і Factory Buildouts сприяє значним доходом”, – заявили під час дзвінка NVIDIA EVP та фінансового директора Колетта Кресса.
Дайвінг розуміння:
Фортуни NVIDIA злетіли в останні два з половиною роки, керовані масовими інвестиціями в технічний сектор в інфраструктурі центру обробки даних, оптимізованих AI, для навчання та розгортання великих мовних моделей. У той час як Heperscaler Hunger для GPU залишається надійним, компанія робить ставку на ринок підприємств, щоб забрати оберти.
Великі хмарні постачальники встановили в середньому приблизно 72 000 GPUS NVIDIA Blackwell на тиждень протягом кварталу і на шляху до збільшення споживання, повідомляє Кресс. “Microsoft, наприклад, вже розгорнула десятки тисяч графічних процесорів Блеквелла і, як очікується, збільшить до сотень тисяч GB200 з OpenAi як одним із його ключових клієнтів”, – сказав Кресс.
Доходи NVIDIA злетіли до 44,1 млрд. Доларів за два з половиною роки
Дохід за квартал, мільярди
Грейс Grace Blackwell Superchip, випущений рік тому,-це процесор високої ємності, який забезпечує більшу стійку, розроблену для обробки найбільш обчислювальних навантажень AI, таких як тренування з модель. У березні NVIDIA представила свого наступника, більш потужну систему стійок GB300 NVL72.
Хмарні постачальники почали відбирати нові процесори на початку цього місяця, і Nvidia очікує, що відправлення розпочнуться пізніше цього кварталу, сказав Кресс.
По мірі того, як його слід серед гіперкалерів продовжував розширюватися, Nvidia додав до свого портфоліо продуктів підприємства та підробили більш глибокі партнерські стосунки. У травні компанія розгорнула лінійку ноутбуків та робочих станцій, що працюють на GPU, звернувшись до своїх партнерів з виробництва ПК для доставки клієнтів підприємств.
“Enterprise AI просто злітає”,-сказав Хуанг у середу, вказуючи на нову лінійку локальних апаратних засобів AI. Кресс рекламував партнерство з розвитку AI, яку компанія в березні була введена в бренди Yum.
NVIDIA допоможе корпоративним батьком KFC, Pizza Hut та Taco Bell розгорнути AI у 500 ресторанах цього року та 61 000 локацій з часом, щоб “впорядкувати замовлення, оптимізувати операції та покращити обслуговування”,-сказав Кресс.
Ініціатива являє собою крок у великі ліги AI для брендів Yum. У минулому році компанія працювала з неназваним стартапом AI, щоб створити чат-чат Taco Bell-Drive-tru. Він також відзначив перший набіг NVIDIA в ресторанному бізнесі, згідно з повідомленням.
Yum використовував технологію NVIDIA, щоб живити свою власну байт за платформою Yum та включити голосові агенти AI, інструменти комп'ютерного зору та можливості аналітики продуктивності.
“Enterprise AI повинен бути розгортається на премії та інтегрована з його існуючим”,-сказав Хуанг. “Це обчислення, зберігання та мережа. Ми нарешті зібрали їх усі три, і ми збираємося на ринок з цим”.
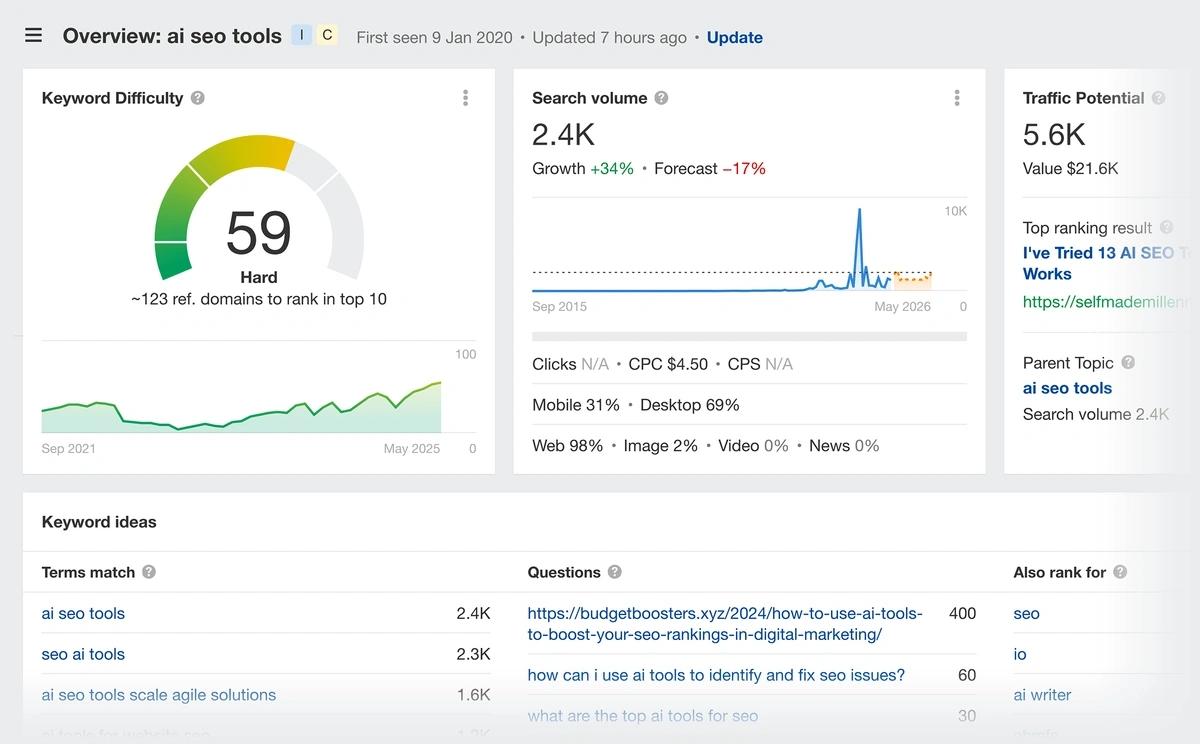
Планувальник ключових слів Google та AHREFS – це два інструменти оптимізації пошукових систем (SEO), які часто рекомендуються для маркетологів для початківців. Хоча можна отримати чудові ідеї ключових слів за допомогою будь -якої платформи, є чіткі обмеження для обох.
Зробити правильний вибір між планувальником ключових слів Google та AHREFS є важливим, якщо ви хочете побачити довгостроковий успіх SEO.
Отримати більше Пошуковий рух
Використовуйте ключові слова Trending, щоб створити вміст, яку прагне ваша аудиторія.
Ключові відмінності між планувальником ключових слів Google проти AHREFS
Найбільша різниця між планувальником ключових слів Google та AHREFS полягає в тому, що планувальник ключових слів Google строго є інструментом досліджень, тоді як AHREFS дозволяє досліджувати та відстежувати конкретні умови.
Те, як дві платформи джерела своїх даних також відрізняються.
Дані планування ключових слів Google надходять від оголошень Google. Використовуючи інструмент, ви технічно бачите інформацію, пов’язану з ключовими словами та пошуком оплати за клік (PPC).
З іншого боку, AHREFS збирає дані з декількох джерел: власні пошукові гусениці, планувальник ключових слів Google, тенденції Google, консоль пошуку Google тощо.
Планувальник ключових слів Google також відрізняється ціною. Планувальник ключових слів Google – це безкоштовний інструмент, тоді як Ahrefs Paywall підтримує багато його функцій.
Однак, Ahrefs пропонує безкоштовний план, який підходить для багатьох власників малого бізнесу та маркетологів.
Google Ключові слова планувальник проти Ahrefs з першого погляду
Планувальник ключових слів Google
Ахрефс
Джерело даних
Оголошення Google
Ahrefs Crawlers, Google
Найкраще
Рекламні кампанії PPC, легкі дослідження SEO, ключові слова з низьким складом
Інтенсивне дослідження ключових слів SEO та PPC, ключові слова з низьким складом
Додаткові інструменти
Планувальник оголошень Google
Аудит сайту, аналіз конкуренції, моніторинг бренду, аналіз зворотного посилання, відстеження рангів, місцева стратегія SEO та інструменти AI Assistant Content Assistant
Популярність
23% зростання інтересу за останні 10 років
1,417% зростання відсотків за останні 10 років
Модель ціноутворення
Безкоштовний
Оплачувана (безкоштовна версія доступна з обмеженнями)
Первинна аудиторія
Фахівці з маркетингу пошукових систем (SEM), власники бізнесу
Професіонали SEO, SEM -професіонали, власники бізнесу, цифрові маркетологи
Як використовувати планувальник ключових слів Google для досліджень SEO
Використання планувальника ключових слів Google для досліджень SEO просте – для цього потрібен лише безкоштовний обліковий запис Google Ads. Вам не потрібно платити за будь -які оголошення, щоб використовувати інструмент.
Використовуючи планувальник ключових слів, у вас буде можливість розпочати пошук із терміном або доменом веб -сайту.
Дослідження ключових слів, орієнтованих на термін
Введіть будь -яке цільове ключове слово, що цікавить, у планувальник ключових слів Google, щоб створити список пов'язаних термінів.
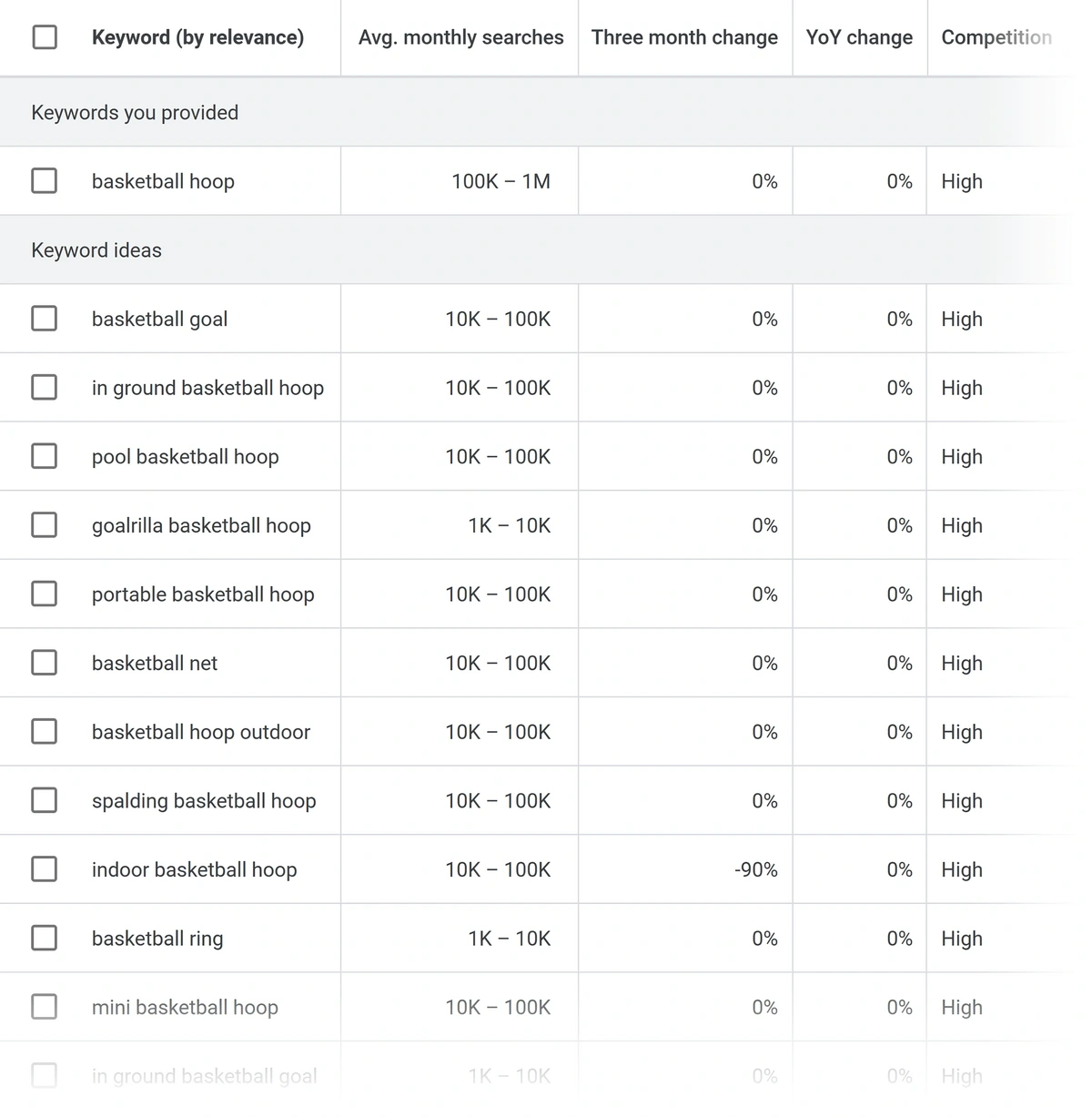
Ви зможете побачити цінні відомості, які включають:
Середні дані про обсяг пошуку
Швидкість змін протягом трьох місяців
Зміни за рік
Рівень конкуренції (ключові слова)
Реклама частка враження
Діапазони ставок КПП
Щоб зробити ваші результати більш точними, ви можете додавати свій домен кожного разу, коли ви запускаєте пошук ключових слів. Це видалить будь -які ключові слова, які не пов'язані з вашими продуктами, послугами чи вмістом.
Ви також можете передати ключові слова до звіту про “прогноз”. Ці звіти дають вам додаткову інформацію, включаючи очікувану популярність терміна в майбутньому. Звіт про прогноз також дозволяє бачити:
Обсяг пошуку ключових слів за місцем розташування
Очікуване використання пристроїв пошуковими особами
Популярність за місцем розташування
Використання планувальника ключових слів Google може допомогти вам знайти найкращі пов'язані ключові слова, які можна використовувати для SEO та інших цифрових маркетингових кампаній.
Порада: Пошук термінів, пов’язаних з продуктом, у планувальній формі Google Ключові слова дає вам уявлення про те, що цікавлять клієнтів, включаючи розміри, кольори тощо.
Дослідження ключових слів, орієнтованих на веб-сайт
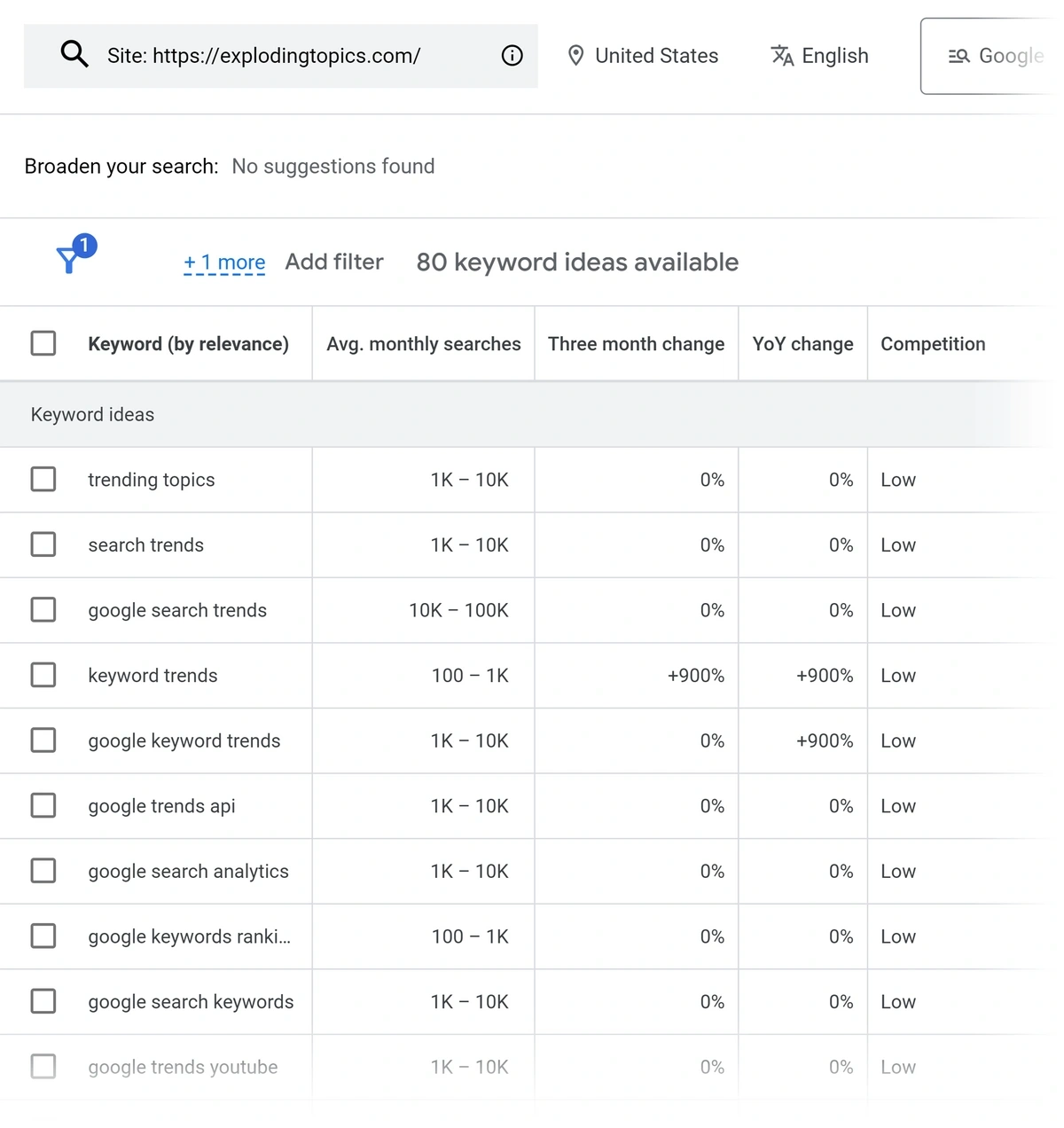
Ви також можете генерувати списки ключових слів за допомогою вашого веб -сайту – або весь домен, або на одній сторінці.
Ви отримаєте список ключових слів, пов’язаних з вашим сайтом, хоча планувальник ключових слів Google не покаже вам, як ваш сайт займає ці умови. (Щоб побачити інформацію про позицію, вам потрібно буде використовувати такий інструмент, як Ahrefs або Semrush.)
Порада: Якщо вам потрібно швидко побачити основні показники ключових слів, спробуйте наш безкоштовний інструмент дослідження ключових слів! Це покаже вам пов'язані умови, обсяг пошуку, рівень конкуренції, вартість клацання (CPC), загальні результати та тенденції.
Однак пам’ятайте, що планувальник ключових слів Google показує вам дані, специфічні для пошуку Google. Це не відображає популярності різних термінів у соціальних мережах чи інших платформах. Щоб побачити це, вам знадобиться такий інструмент, як вибухаючі теми.
Теми, що вибухають, показують вам історичні дані про тенденцію за останні 15 років, а також прогнозовані прогнози популярності. Ми підтримуємо базу даних помітних тем, але ви також можете шукати будь -який термін за допомогою нашого інструменту аналізу тенденцій.
Одна велика проблема з планувальником ключових слів Google
Оскільки планувальник ключових слів Google є інструментом PPC, оцінки конкуренції, які він показує, призначені для платних оголошень. Проблема тут полягає в тому, що ключове слово може мати високий рівень конкуренції КПК та низький показник труднощів з органічним пошуком одночасно.
Бажати Шпигун на вашу конкуренцію?
Вивчіть статистику трафіку веб -сайтів конкурентів, відкрийте пункти зростання та розширюйте частку ринку.
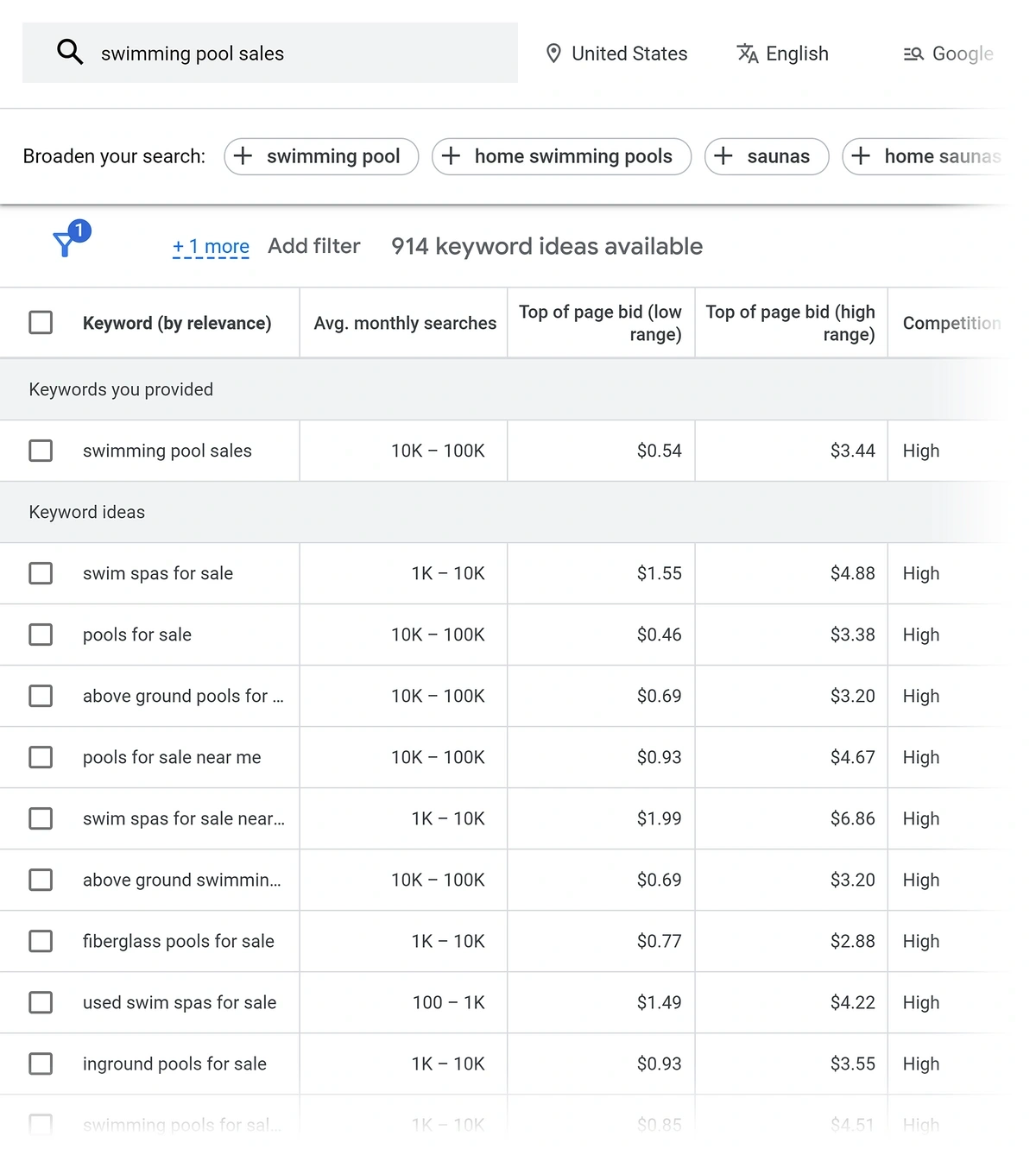
Давайте використаємо термін «продажі басейну» як приклад. Я пишу це в травні, тому літні відпустки та дні басейну на увазі людей. З точки зору оплачуваної реклами, це дуже конкурентне ключове слово. Можливо, мені доведеться платити понад три долари за клацання, щоб запустити рекламу на цей термін.
Але той самий термін має низький показник складності ключових слів для органічного пошуку, як ми бачимо на цьому скріншоті з інструменту огляду ключового слова Semrush:
Ми також можемо побачити, що органічний пошуковий трафік для “продажів басейну” нижчий, ніж платний рекламний трафік, який повідомляє Google Planner. Однак це не обов'язково погано, і допомагає зробити ключове слово менш конкурентоспроможним.
Якби я використовував планувальник ключових слів Google, я можу пропустити це ключове слово і залишити його поза своєю стратегією SEO. Це було б помилкою! Дані органічних ключових слів вказують на те, що я можу обґрунтовано оцінювати свій веб -сайт за цим терміном за допомогою цільового контент -маркетингу або місцевих зусиль SEO. Якби я проігнорував ключове слово, я б пропустив зв’язок з (і продажем) новими клієнтами.
Google ключових слів Плюс і мінуси планувальників
Професії планувальника ключових слів Google
Планувальник ключових слів Google
Безкоштовний
Обмежена функціональність
Показує фактичні та проектовані дані ключових слів
Технічно призначений для КПП, а не органічних досліджень SEO
Швидко генерує списки пов'язаних термінів
Можливо, вам доведеться просіяти дані КПП, які не пов'язані з вашими потребами в SEO
Дозволяє сканувати ключові слова, пов’язані з вашим сайтом
Дані надходять з одного джерела (Google)
Повідомлені дані про ключове слово КПК можуть не відповідати обсягу органічного пошуку та конкуренції
Як використовувати AHREFS для SEO -досліджень
Ви можете використовувати AHREFS для дослідження ключових слів і відстежувати ранг вашого сайту за ці терміни в одному місці.
Пошук ключових слів за допомогою AHREFS
Інструмент провідника ключових слів AHREFS надає набагато детальніше про пошукові терміни, ніж планувальник ключових слів Google. (Ahrefs порівнянні з таким інструментом, як Semrush.) Ви можете використовувати AHREFS, щоб знайти як ключові слова короткого, так і довгохводу.
Використання провідника ключових слів простий – тип в одному або декількох пошукових термінах, щоб розпочати дослідження.
Отриманий список покаже вам ключові показники щодо кожного терміна, включаючи:
Намір пошуку (мета пошуку)
Обсяг пошуку ключових слів
Конкуренція (труднощі)
Тенденції популярності
Пов’язані теми
Сторінки з деталями ключових слів використовують барвисту діаграму, яка показує вам конкретні труднощі ключового слова та тарифи конкуренції. Це відрізняється від планувальника ключових слів Google, що лише зазначає, що ключове слово – це низька, середня або висока конкуренція.
Відстеження ключових слів у ahrefs
Ви можете зберегти будь -яке з ключових слів, які ви досліджуєте в AHREFS, і додати їх до списку відстеження позицій. У поєднанні з ключовими словами вашого сайту вже класифікується (який ви також можете ідентифікувати за допомогою AHREFS), ви можете краще оцінити вплив своїх SEO зусиль.
Миттєво аналізувати Будь -який ринок
Можливість відстеження та вимірювання змін положення є важливою при розробці та моніторингу стратегії SEO. Ось чому я завжди рекомендую, щоб кожен, хто серйозно ставиться до своїх SEO, інвестує в платний інструмент, як Ahrefs або Semrush. Планувальник ключових слів Google не вирізає його.
Ahrefs ціноутворення
На відміну від планувальника ключових слів Google, Ahrefs не є безкоштовним інструментом. Компанія пропонує безкоштовний план, який дозволяє стежити за здоров’ям вашого веб -сайту та його статусом на сторінці результатів пошукових систем (SERP), але ви не можете провести жодного дослідження ключових слів.
Щоб отримати максимальну користь від Ahrefs, вам потрібен платний план. Параметри починаються від 108 доларів на місяць, коли виставляються щорічно.
Ahrefs Pros and Cons
Ahrefs pro
Ахрефс мінусів
Дуже детальні результати досліджень ключових слів
Обмежене безкоштовне використання
Легкий аналіз конкурентів
Платні плани можуть бути дорогими
Окремі органічні показники SEO та PPC
Інтерфейс може бути надзвичайним для нових користувачів
Додаткові інструменти для аудиту сайтів, аудиту зворотного зв'язку, оптимізації вмісту тощо
Поширення
Наскільки надійний планувальник ключових слів Google?
Планувальник ключових слів Google – це надійний спосіб пошуку даних ключових слів PPC, оскільки він витягує свою інформацію безпосередньо з платформи пошукової системи Google та рекламних оголошень. Це хороший спосіб отримати загальне відчуття до органічного пошукового ландшафту – але деякі ключові слова матимуть дуже різні органічні та оплачені обсяги пошуку та ставки конкуренції.
Чи точні дані про обсяг обсягу AHREFS?
Так, Ahrefs – це надійне джерело інформації про ключові слова. Звіт AHREFS вказував, що дані їх обсягу пошуку були “приблизно точними” протягом 60% часу, тоді як планувальник ключових слів Google “різко завищував” обсяг пошуку протягом 50% часу.
Однак, важливо зазначити, що всі показники трафіку ключових слів в кінцевому рахунку є оцінкою. Такі інструменти, як AHREFS, використовують різні сканери та джерела даних для складання найімовірніших темпів пошуку та темпів змагань, але вони можуть змінюватися з часом.
Які ще інструменти для дослідження ключових слів?
Планувальник ключових слів Google – одна з небагатьох альтернатив AHREFS, яка абсолютно безкоштовна. Ahrefs та Semrush пропонують безкоштовні плани, які дозволяють вам безкоштовно використовувати частину функцій інструменту. Багато інших інструментів SEO, як -от рейтинг SE, потребують платного плану при реєстрації.
Що врахувати при виборі інструменту дослідження ключових слів
Важливо враховувати довгострокові цілі при оцінці найкращого інструменту ключових слів для ваших потреб. Якщо вас цікавить короткострокові рекламні кампанії або перевіряєте том ключового слова в одному місці в часі, то планувальник ключових слів Google добре обслуговуватиме ваші потреби. Але якщо ви хочете вдосконалити SEO свого сайту в довгостроковій перспективі, вам краще обслуговуватиме Ahrefs.
Ви також захочете розглянути показники, важливі для вашої роботи. Планувальник ключових слів Google показує вам базові дані та дані про конкуренцію, але він не розбиває для вас сторінку результатів пошукової системи (SERP). І ні планувальник ключових слів Google, ні Ahrefs в даний час не можуть показувати вам багатоканальні дані про тенденцію та де ваш сайт стоїть у результатах Chatgpt.
Ви можете побачити всі ці дані – Seo, PPC, LLM та прогнози тенденції – на одному місці, коли ви використовуєте комбінацію теми Semrush та вибуху. Semrush пропонує щедрий безкоштовний план, але ви також можете захопити розширену 14-денну безкоштовну пробну версію за допомогою нашого ексклюзивного коду купона. Додайте безкоштовну семиденну пробну версію вибухаючих тем Pro одночасно, щоб розблокувати дивовижний рівень даних-і подивіться, як саме ви можете зробити з правильними інструментами SEO.
Боулдер, штат Колорада, 28 травня 2025 р.-Логіка спектрів, глобальний лідер у галузі управління даними та рішень для зберігання даних, сьогодні оголосила про підтримку технології стрічки LTO-10 у своєму повному портфоліо бібліотек стрічки*, включаючи спектри Tfinity, Spectra T950, Cube Spectra та моделі стека спектрів.
LTO-10 представляє новий архітектурний фундамент для стрічки, що забезпечує 30 терабайт (ТБ) рідної ємності та 400 Мб/с швидкість передачі на картридж-розширення стратегічного бачення спектрів для забезпечення масштабованої, стійкої та кібер-резервної тривалої архівної архіви для збереження довгострокових даних.
За допомогою цього оголошення Spectra Logic продовжує своє лідерство в інноваційних стрічках, забезпечуючи десяте покоління технології LTO – віха, яка відзначає 25 років з моменту створення формату. Від LTO-1 у 2000 році до LTO-10 у 2025 році формат забезпечив 300-кратне збільшення потужності на картридж, демонструючи неперевершену розширюваність та надійність в центрі обробки даних.
По мірі того, як вимоги до збереження даних посилюються в різних галузях, що керуються навчальними моделями AI, сенсорними мережами, дотриманням та аналітикою довгохводу, організації потребують більш масштабованої, економічно ефективної інфраструктури для управління масовим зростанням даних без шкоди для стійкості чи безпеки.
LTO-10 забезпечує 66% збільшення потужності на картридж порівняно з технологією LTO-9 попереднього покоління, забезпечуючи значно більшу щільність зберігання та пропонуючи найменшу загальну вартість потужності порівняно з об'єктами на основі жорсткого диска та хмарними послугами холодного зберігання. Підтримувані інтерфейси включають волоконний канал 32 ГБ/с та 12 ГБ/с SAS.
Моделі, оснащені SAS, є сумісними з оптичним SAS-перемикачем SPECTRA OSW-2400, що дозволяє значною додатковою економією на сполученні до кінця між серверами та стрічковими приводами, розташованими в відстані центру обробки даних до 10 000 м2 (107 639 кв. Футів).
У той час як хмара та диск залишаються життєздатними для навантажень на високому доступі, вони все частіше ставляться до підвищення довгострокових витрат на зберігання хмар, систем, що голодують з енергією та ескалації кібер-ризиків. LTO-10 підтверджує справу на локальних архівах, що базується на об'єктах, що дозволяє організаціям репатріювати архівні дані з хмари та зменшувати експлуатаційні витрати, відновлюючи контроль над довгоживими активами даних.
Технологія LTO-10 також може підвищити зусилля щодо стійкості порівняно з дисками для дисків, що споживають на 90% менше енергії на Petabyte, ніж порівнянні підприємства на підприємстві щорічно. У масштабах переміщення локального зберігання холодного зберігання на стрічку може заощадити значну потужність, збільшуючи наявну енергію для підживлення АІ та інших ініціатив зростання або заощадження врожаю.
“Логіка Spectra продовжує рухати м'яч вперед з неймовірними масштабами та потужністю”, – сказав Стівен Фоскетт, президент бізнес -підрозділу Tech Field Day, Futurum Group. “LTO-10-це головна виграш для клієнтів Spectra Logic, оскільки вони можуть модернізувати існуючі бібліотеки стрічок для набагато більшої потужності в одному сліді. Завдяки цьому безпроблемному шляху оновлення клієнти можуть модернізувати захист даних та архівне середовище за меншими витратами та впливу на екологію”.
LTO-10 ідеально підходить для широкого спектру організацій, що працюють на передньому плані відкриття та інновацій, керованих даними, такі як високоефективні обчислювальні лабораторії, агентства з прогнозування погоди, науково-дослідні університети, космічні агентства та фармацевтичні дослідницькі групи. Він також добре розташований для трубопроводів штучного інтелекту, архіву медіа та розважальних активів, а також для зниження вартості інфраструктури для зберігання гіпершарів та хмарного холодного зберігання.
“Цього року відзначається 25 років з моменту запуску LTO-1 у 2000 році та дебют LTO-10-десятого покоління-зменшує чудову довголіття та інновації стандарту LTO”,-сказав Натан Томпсон, генеральний директор і засновник спектра логіки. “З 300-кратним збільшенням потужності на картридж за цей час LTO виявився однією з найбільш стійких, розширюваних та економічно ефективних технологій в ІТ. І оскільки AI прискорює масштаб неструктурованого збереження даних, LTO-10 саме тоді, коли світ йому найбільше потребує”.
Сертифіковані медіа Spectra для LTO-10
Spectra запропонує LTO-10 Media під час запуску через свою перевірену сертифіковану медіа-програму. Кожен картридж LTO-10 проходить суворий процес огляду та перевірки. Кожен картридж повністю інтегрований із програмним забезпеченням LifeCycle (MLM) Spectra Media Management (MLM), яке проактивно відстежує, керує та надає звіти про всі аспекти використання стрічки та стан здоров'я. MLM допомагає ефективно керувати стрічками від початку до кінця безперервними оцінками більш ніж 40 різних показників протягом усього життя кожної стрічки. Усі сертифіковані Spectra Media мають гарантію заміни довічної заміни від дефектів медіа.
Наявність
Технологія LTO-10 доступна для негайного замовлення. Клієнти можуть додати накопичувачі LTO-10 до будь-яких нових бібліотек Spectra Builds або оновлення існуючих систем, використовуючи функції Fiber Channel повного висоти або параметри приводу SAS. Початкові поставки накопичувачів LTO-10 та сертифікованих ЗМІ розпочнуться в червні 2025 року.
Для отримання додаткової інформації або для планування консультації з продажу відвідайте www.spectralogic.com/contact.
*Бібліотеки, що негайно підтримують LTO-10, включають спектри Tfinity, Tfinity Exascale, Tfinity Plus, T950, T950V, T680, T380, T200, Cube Spectra та Spectra Stack.
Про спектри логіки
Спеціальні інновації для зберігання даних протягом більше 40 років, спектра логіка допомагає організаціям модернізувати свою ІТ-інфраструктуру та захищати та зберігати свої дані за допомогою широкого портфеля рішень, що дозволяють їм керувати, мігрують, зберігають та зберігати довгострокові дані бізнесу, а також функції, щоб змусити їх викупити стромі, чи в усіх локусах. Щоб дізнатися більше, відвідайте www.spectralogic.com.
Недавній PLOS -біологія Стаття Катарін Чен, Марія Торо-Морено та Расі Субраманіам досліджували це саме питання, описуючи переваги та обмеження-використання github в академічній мокрої лабораторії. Серед переваг: 1) співпрацяз кількома дослідниками, здатними внести свій внесок у один і той же проект, не перезаписавшись один одного; 2) доступністьоскільки основні функції Github вільні у використанні; і 3) простота на бортузавдяки великій документації та навчальній посібниках для початківців. Для тих, хто зацікавлений у глибці в системі, більш детально доступно у подальшій публікації від групи, наявної як попередній друк.
Однак, є застереження. Для лабораторій, що працюють з конфіденційними даними, особливо залучаючи людських суб'єктів – Github – це не місце для зберігання захищеної інформації про здоров'я. І хоча доступні ресурси, вивчення Github все ще може створювати перешкоду для тих, хто не має обчислювального походження.
Марія Торо-Морено, докторантура в лабораторії Субраманіама, вважає Github як практичним інструментом для майбутнього. “Кожна лабораторія працює по -різному, а знання з управління лабораторіями зазвичай надходять лише через прямий досвід”, – каже вона. “Вчені рідко документують ці практичні аспекти займання науки, тому ці знання часто втрачаються. Пошук github корисним у нашій роботі, ми хотіли поділитися своїм досвідом – особливо для постдоків, починаючи думати про те, як вони будуть керувати своїми майбутніми лабораторіями”.
Github, можливо, почався як інструмент для кодерів, але його потенціал значно перевищує вікно терміналу. Для вчених -лавок, які стикаються з такими проблемами, такими як погана відтворюваність, неорганізовані дані та знання, втрачені в переході, прийняття систем контролю версій, таких як Github, можуть бути тихою революцією в тому, як ми документуємо, ділимося та співпрацюємо. У міру того, як наука зростає більш взаємопов'язаною, інструменти, які ми використовуємо, повинні відображати це – а іноді найпотужніші рішення надходять з мислення поза піпеткою.










 Крім того, Snorkel AI оголосив, що зібрав 100 мільйонів доларів фінансування серії D за оцінкою 1,3 мільярда доларів на чолі з додаванням. Це нове фінансування сприятиме постійним дослідженням та інноваціям при оцінці та настройці спеціалізованих систем AI з експертними даними.
Крім того, Snorkel AI оголосив, що зібрав 100 мільйонів доларів фінансування серії D за оцінкою 1,3 мільярда доларів на чолі з додаванням. Це нове фінансування сприятиме постійним дослідженням та інноваціям при оцінці та настройці спеціалізованих систем AI з експертними даними.




 LTO-10 представляє новий архітектурний фундамент для стрічки, що забезпечує 30 терабайт (ТБ) рідної ємності та 400 Мб/с швидкість передачі на картридж-розширення стратегічного бачення спектрів для забезпечення масштабованої, стійкої та кібер-резервної тривалої архівної архіви для збереження довгострокових даних.
LTO-10 представляє новий архітектурний фундамент для стрічки, що забезпечує 30 терабайт (ТБ) рідної ємності та 400 Мб/с швидкість передачі на картридж-розширення стратегічного бачення спектрів для забезпечення масштабованої, стійкої та кібер-резервної тривалої архівної архіви для збереження довгострокових даних.