Ось швидкий огляд інструментів з відкритим кодом на базі AI, які забезпечують посилений захист мережевих систем проти ряду кібер-атак.
Програми штучного інтелекту (AI) за допомогою розширених чатів є нормою сьогодні в галузях, таких як охорона здоров'я, роздрібна торгівля та фінанси. Запуск Chatgpt від OpenAI супроводжувався випуском багатьох чатів AI для декількох програм. Деякі з основних випусків, що слідували за чатом, включають Близнюки, здивування, чатпдф, болт і милий. Наразі численні чат -боти розробляються і незабаром будуть запущені для декількох доменів.
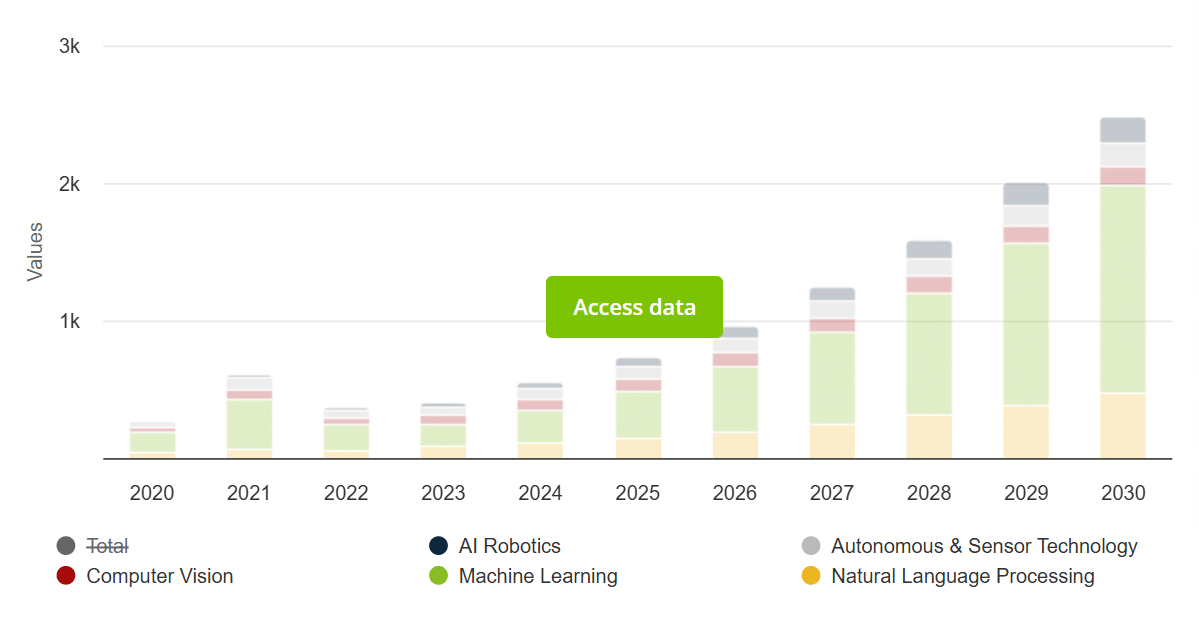
Глобальний розмір ринку AI був оцінений приблизно в 200 мільярдів доларів у 2023 році, і, за прогнозами, він зросте в CAGR близько 36% між 2023 та 2030 роками.
Малюнок 1: Глобальний ринок штучного інтелекту (Джерело: GrandViewResearch)
AI в кібербезпеці та мережевій криміналістиці
AI не тільки корисний для написання контенту, але й для додатків, пов'язаних з цифровою криміналістикою та управлінням мережею. Він може бути використаний для кібер -криміналістики, мережевої аналітики та інформаційної безпеки (табл. 1).
AI в кібербезпеці та мережевій криміналістиці
Кібер-обман
Оцінка кібер-ризику, орієнтованого на AI
5G та IoT
AI-керований SOC (Центр операцій з безпеки)
Тестування на проникнення
Виявлення та відповідь кінцевої точки, що працює на AI (EDR)
Брандмауери та IDS/IPS
Оптимізація SIEM, що працює на AI
Змагальне виявлення AI
Виявлення аномалії
Автоматизована відповідність конфіденційності даних
Автоматизована реакція інциденту
Автоматизоване управління патчами
Виявлення ботнету
Автоматизація хмарної безпеки
Оцінка кібер -ризику
Безпека DNS
Темний моніторинг веб -сайтів
Технологія обману
Виявлення Deepfake
Цифрова криміналістика
Зашифрований аналіз трафіку
Аналіз журналів криміналістики
Виявлення шахрайства
Управління ідентичністю та доступом (IAM)
Виявлення інсайдерської загрози
Аналіз зловмисного програмного забезпечення
Аналіз мережевого трафіку
Фішинг -виявлення
Прогнозування розвідки
Квантова криптографія
Захист викупу
Безпечні DevOps (Devsecops)
Інформація про безпеку та управління подіями (SIEM)
Безпека ланцюгів поставок
Виявлення та профілактика загрози
Полювання на загрозу
Аналітика поведінки користувачів (UBA)
Голос та чат -безпека
Нульова довіра безпеки
Самоосвітній ШІ для адаптивної безпеки
Таблиця 1: Ключові програми та випадки використання ШІ в кібербезпеці та управлінні мережею
Нижче наведено кілька інструментів з відкритим кодом, що базуються на AI, які є популярними для кібер-криміналістики та аналітики мережі.
Інтелектуальна розвідка та SIEM (Інформація про безпеку та управління подіями) Інструменти
Вазу (https://wazuh.com)
Wazuh-це інструмент моніторингу з відкритим кодом, інтегрований із безпекою кінцевої точки, що працює на AI, аналізу та оцінках журналу. Він використовує розширене виявлення та реагування (XDR), а також можливості безпеки та управління подіями (SIEM), щоб запропонувати єдину платформу для різноманітного захисту.
Малюнок 2: Розмір ринку та використання випадків штучного інтелекту (Джерело: Статистика)Малюнок 3: Вазух
Його функції безпеки кінцевої точки включають виявлення зловмисного програмного забезпечення, оцінку конфігурації та моніторинг цілісності файлів.Відповідність регуляторних норм, реагування на інциденти та гігієна ІТ складають свої операції з безпеки. Він також пропонує аналіз даних про журнал, полювання на загрози та виявлення вразливості.Хмарні функції безпеки включають управління поставою, захист контейнерів та захист навантаження.
Wazuh інтегрує комплексні механізми безпеки для декількох кінцевих точок та цифрової інфраструктури і може бути використаний для високопродуктивної безпеки та додатків на основі конфіденційності.
Нещастя (https://www.misp-project.org/)
MISP-це високопродуктивна платформа для розвідки, аналітики та оцінок, що використовують AI, використовуючи AI для виявлення та співвідношення кіберзагроз.
Він використовується в різних програмах цифрової криміналістики для зберігання, обміну та співпраці над операціями на основі шкідливих програм та кібербезпеки. Він працює над аналітикою та запобіганням кібер -шахрайств, погроз та нападів.
Малюнок 4: MISP
Аналіз мережевого трафіку та інструменти виявлення вторгнень
За курс (zeek.org/)
Zeek – це інтегрований інструмент для аналізу трафіку та моніторингу мережі. Платформа використовується для аналітики та прогнозування зловмисного програмного забезпечення та підозрілого трафіку в мережі та цифровій інфраструктурі.
Хропіти(Snort.org/)
Це система виявлення вторгнень (IDS) для виявлення загроз мережі. Моделі на основі AI можуть використовувати його для управління мережею та аналітики.
Сурфорд(suricata.io/)
Цей інструмент IDS/IPS з відкритим кодом має функції виявлення загрози та інтегрується з AI для глибокої аналітики даних та цифрової інфраструктури.
Дітям (virustotal.github.io/yara/)
Яра орієнтована на зловмисне програмне забезпечення та класифікує напади, пов'язані з конкретними підписами мережі. Механізми, засновані на правилах, можна запрограмувати в цей інструмент, щоб напади можна було ефективно оцінити.
ВІДЧИНЕНО(OpenVas.org/)
OpenVAS-це багатофункціональний сканер для виявлення різних типів вразливості та атак у мережевому середовищі. Він може оцінювати та визначити пріоритетні різні протоколи.
Квапка(clamav.net/)
Clamav-це високопродуктивна платформа, яка використовується для виявлення та глибокої оцінки шкідливих програм, вірусів, троянців та зловмисних загроз. Він може бути використаний для сканування файлів та аналітики підписів.
Інструмент моніторингу безпеки та моніторингу журналів кінцевої точки
оскій (Osquery.io/)
Osquery використовується для тестування, аналітики та безпеки кінцевої точки та фокусується на безпеці потоків та витоках пам'яті. Він може бути використаний для запиту систем для зйомки критичної інформації, яка потім аналізується на застосування на основі криміналістики та прогнозовану аналітику.
Малюнок 6: Оскій
Ці інструменти та рамки можуть використовуватися залежно від проблеми безпеки, таких як зловмисне програмне забезпечення, троянці, вразливості, файли журналів тощо.
У галузі, де одна погана партія може означати мільйони втрат, або, що ще гірше, надійні та контекстні AI є критичним компонентом у створенні безпечнішої, розумнішої ланцюга поставок.
Штучний інтелект (AI) вже не є амбіцією майбутнього стану для промисловості продовольства та напоїв (F&B); Це тут. А бренди, що переносять, починають використовувати його для досягнення якості, безпеки та регуляторних гарантій, які ми, як споживачі, вимагаємо продукції, яку ми їмо та п'ємо. Сила великих мовних моделей (LLMS) незаперечна, але справжній прорив не в їх загальних можливостях. Натомість мова йде про те, як їх можна стратегічно адаптувати для вирішення проблем, пов'язаних з галузями, не жертвуючи безпекою, швидкістю чи довірою.
Для галузі, настільки складної та високорегульованої, як F&B, навчання моделі AI з власних даних є дорогим та технічно залученим, і вона може ввести потенційні ризики конфіденційності. Краща альтернатива, що виникає як чітка найкраща практика,-це застосування «рівня знань», що використовує комерційні LLM, поряд із структурами даних, які забезпечують галузевий контекст, семантичну чіткість та інтелект, що стосується домену. Це може приймати декілька форм, але все більш важлива частина головоломки-це техніка, відома як покоління, що виходить з пошуку (RAG), яка дозволяє користувачам поєднувати переваги сучасного генеративного ШІ з точністю, контролем та гарантуванням, необхідними для безпеки харчових продуктів та дотримання.
Поза межами галасу: там, де генеративний ШІ може не вистачати
LLM довели свою корисність у широкому спектрі додатків – від написання електронних листів до кодування та обслуговування клієнтів, але вони лише такі хороші, як і дані, з якими вони повинні працювати. LLM, який навчається на великих наборах даних, що виникають, наприклад, з платформ соціальних медіа, може не дати точних відповідей на більш вузькі, більш технічні питання. Це стає викликом при роботі з складною мовою, контекстом та регуляторними нюансами галузі F&B.
У справі з заявами про алерген, дотриманням рівня інгредієнтів або оцінками ризику постачальника, AI, що не має достатньо хороших. Моделі загального призначення можуть дати правдоподібно звучав, але небезпечно неточні результати: галюцинації. У контексті безпеки харчових продуктів це не просто технічна вигадка – це відповідальність і ризик не варто взяти.
Застосування AI у високорегульованих галузях, таких як F&B, вимагає AI, обґрунтованого фактами, щільно підданих завданням, що знаходиться в руці, і переконливо точним. Ось де архітектури, що знаходяться в домені, такі як ганчірка.
Див. Також: Основні уроки для побудови ефективних ганчіркових систем
Чому ганчір має значення в контексті F&B
Покоління, що надходить, покоління мостить розрив між можливостями AI та специфічними потребами в галузі. Замість того, щоб тренувати модель, яка передбачає навчання її з нуля, використовуючи масові власні набори даних, RAG використовує попередньо підготовлений LLM як двигун міркувань. Потім ця модель підключена до ретельно структурованого, зовнішнього сховища даних: “шар знань”.
Коли користувач ставить питання або ініціює робочий процес, модель не покладається на загальну підготовку. Натомість він отримує відповідну інформацію з рівня знань і використовує її для керівництва та підтвердження його відповіді. Це гарантує, що результати є контекстуально актуальним, так і фактично обґрунтованим у даних, які найбільше мають значення для бізнесу.
Ще одним важливим аспектом рівня знань є те, що він може містити інформацію, характерну для даної компанії, але в безпечній, федеральній структурі, яка забезпечує конфіденційність даних. LLMS можна запобігти доступу (і запам'ятовувати) фірмової інформації, але відповіді, які вони генерують, все ще можуть бути підтверджені для точності щодо даних про рівень знань. Для F&B це означає, що рівень знань може включати в себе галузеві ресурси, такі як регуляторні бази даних, але також може (якщо користувач вибирає) включати більш конфіденційну інформацію, отриману з специфікацій інгредієнтів, документації постачальників, записів аудиту тощо.
Високі ставки відповідності
Бренди F&B стикаються з деякими найвибагливішими регуляторними середовищами будь -якої галузі. Між Законом про модернізацію безпеки харчових продуктів FDA, міжнародними стандартами, такими як Регламент вирубки лісів Європейського Союзу, та вимоги, що накладені на клієнтів, відповідність є рухомою ціллю. Додати складність управління сотнями чи тисячами постачальників, що охоплюють все, від упаковки до інгредієнтів у глобальних ланцюгах поставок; Не дивно, що команди часто намагаються не відставати.
У світі їжі та напоїв ручні процеси все ще є нормою для всього, від затвердження постачальників до відповідності специфікацій та перевірки документів. Нещодавнє опитування показало, що 48% постачальників все ще використовують ручні електронні таблиці для управління щоденними завданнями, процесами та обміном документами. Понад дві третини (71%) визнають, що застарілі процеси іноді або часто створюють проблеми у своїй щоденній роботі. Ці завдання є важливими, але трудомісткими і часто схильними до людських помилок.
Рішення AI, що знаходяться в домені, що працюють від архітектури шарів знань, можуть автоматизувати та покращити ці робочі процеси. Наприклад, AI може позначити невідповідності між документами постачальника та специфікаціями продукції, запобігаючи помилкам, перш ніж вони вступають у виробничий процес. AI також може перехресно перевірити вміст упаковки для дотримання регіональних законів, сканування сертифікатів, історії аудиту та зовнішніх джерел, таких як відкликання, ідентифікація постачальників ризику.
Швидше, безпечніше, розумніше
Застосування підходу з шару знань пропонує найкращі з обох світів: спритність та сила LLMS без складності чи ризиків, пов'язаних з навчанням LLM з нуля. Не потрібно передавати обсяги чутливих даних для навчання обсягу. Натомість підприємства зберігають повний контроль над своєю фірмовою інформацією, яка індексується та отримується на вимогу і ніколи не зберігається і не змінюється самим LLM.
Архітектура також дозволяє набагато швидше розгортати рішення. Будівництво та навчання на замовлення модель може зайняти місяці та значну інвестицію. На відміну від цього, система на основі ганчірки може працювати в частку часу, що дозволяє командам швидко реалізувати цінність і поступово масштабувати. Оскільки ШІ витягується з кураторного, надійного джерела, результати є більш надійними, що є важливим для галузі високих ставок, де неправильні припущення можуть призвести до регуляторних штрафів або відкликання продукту.
Важливо також зазначити, що розвиток ШІ не стоїть на місці. Просуваючись вперед, системи AI не тільки використовуватимуть структуровані дані для підтвердження їх висновків, але й зможуть застосувати процеси логіки, наборів правил та визначення відносин для сприяння точності обчислення, що дозволяє системам швидко вирішувати складні сценарії оптимізації та інші проблеми швидко та ефективно.
Спеціалізований інтелект – це конкурентна перевага F&B
Одним з найбільш перспективних аспектів такого підходу є перетворення внутрішніх даних компанії на справжній стратегічний актив. Хоча він заснований на комодизованій основоположній моделі, значення полягає в тому, що належить до неї. Унікальна сукупність технічних характеристик, політики, записів аудиту та оперативних знань та оперативних знань стає диференціатором.
На практиці це означає, що дві компанії, що використовують один і той же LLM, можуть генерувати різні результати, якщо одна внутрішньо інвестує в створення міцного структурованого рівня знань, а інший – ні.
Він також відкриває двері для інновацій у прогнозному управлінні ризиками. Поєднуючи історичні дані, продуктивність постачальників та зовнішні сигнали, ці системи можуть почати передбачити потенційні проблеми, перш ніж вони відбудуться, позначаючи тенденції або аномалії, які потребуватимуть людських команд днів або тижнів, щоб розкрити вручну.
Заключне слово про AI та індустрію F&B
Тиск на бренди для інновацій та доставки безпечніших продуктів харчування та напоїв ніколи не зникне і не стане простішим. Очікування споживачів навколо прозорості зростає. Регулюючий контроль затягується. У той час як об'єм та швидкість даних продовжують зростати.
У цьому контексті точний, застосований AI-це не просто приємна. Це швидко стає важливою частиною інфраструктури для будь-якої організації, серйозної щодо того, щоб залишатися сумісними, конкурентоспроможними та готовими до майбутнього. Успіх вимагає продуманого підходу до управління даними, чіткого розуміння того, де AI додає цінності, та зобов'язання створити правильну основу знань.
У галузі, де одна погана партія може означати мільйони втрат, або, що ще гірше, надійний ШІ не є лише технологічною віхою. Це критичний інгредієнт у створенні безпечнішого, розумнішого ланцюга поставок.
Зокрема, інструменти штучного інтелекту (AI) викликали інтерес у всій території правління, викликаючи питання, що змінюють парадигму в бізнесі та академічній роботі та дослідженні, а також більш широкі соціальні та етичні наслідки алгоритмів машинного навчання та інноваційних порушень.
“Через 10 років ми побачимо більше реального впливу, який AI матиме на наших робочих місцях”, – сказав Кейн. “Зараз у нас є доказ концепції та розробки прикладів, але знадобиться час, щоб набори навичок були повністю оптимізовані для ШІ. Хороша новина полягає в тому, що ще не пізно, і кожен повинен вчитися”.
Ось чому Кейн включає аналітику на базі AI на курсах виконавчої освіти в кампусі UGA's Buckhead. Більшість студентів виконавчої влади, за його словами, не використовували такі інструменти, як Chatgpt або інші моделі вивчення мови, і він заохочує практичну практику.
“Багато професіоналів не встигли перевірити ці інструменти, або їх організація перешкоджає цьому”, – сказав він. “Наша аудиторія стає для них пісочницею для навчання. Це навички, які всі знадобляться, і вони повинні бути вчинені в кожній частині навчальної структури в цей момент”.
Наприклад, IIBAI може слугувати тестуванням для великих вищих навчальних закладів, включаючи UGA, щоб зрозуміти, як АІ та інші інструменти можна ефективно інтегрувати в інструкцію.
“У нас ніколи не було такого ресурсу, і всі ми намагаємось знайти правильний шлях вперед”, – сказав Корнуелл. “Хоча це залишається викликом, нам потрібно допомогти людям орієнтуватися”.
Робота з галузевими групами також спонукала до нового способу викладання та включення аналітики даних у навчальну програму бакалаврату. Кілька років тому співпрацюючи з Центром академічних ресурсів EY, професор Маргарет Христос розробила та інтегровані конкретні технологічні справи, що стосуються своїх курсів з бухгалтерської аналітики, які продовжують розвиватися і сьогодні.
Професор Маргарет Христос
“Використання навчальної програми, що базується на випадках, та включення вмісту в реальному світі до класів було надзвичайно корисним для студентів для розвитку мислення аналітики”,-сказав Христос, директор школи бухгалтерського обліку Террі коледжу.
Студенти вчаться розуміти питання фірми, готувати відповідні дані, застосовувати відповідні аналітичні методи даних та чітко повідомляти про результати із зацікавленими сторонами. Ключове мислення та ретельний аналіз є ключовими.
“Наша професія принципово змінюється, і те, як наші випускники працюють дуже орієнтовані на дані”,-сказала вона. “Зараз ми можемо розглянути набагато більш повні та складні дані, ніж раніше, і наш набір навичок повинен змінитися, щоб відобразити це”.
Наприклад, у 2020 році дослідження Христос та його колеги проаналізували, як безпілотники використовуються аудиторами сільського господарства для підрахунку великої рогатої худоби. Раніше працівники фермерських господарств та аудиторів вимагали фізично рахувати худобу. Тепер безпілотники та інші нові інструменти можуть зафіксувати зображення та кількість підрахунків, що призводить до кращої ефективності та точності та меншого стресу для тварин.
“Ми бачимо так багато цікавих способів використання нових технологій разом із традиційними методами бухгалтерського обліку та аналітики”, – сказав Христос. “Ми тільки починаємо дряпати поверхню того, що можливо – і як різні зацікавлені сторони ставляться до цього”.
Моделі змінюються, і компанії незабаром можуть скористатися більш ефективними та економічно ефективними варіантами.
Ландшафт AI у 2024 році зазнав надзвичайного зсуву, оскільки почали з'являтися невеликі, економічно ефективні моделі, що кидає виклик домінуванням великих, голодних даних систем AI, які, як ми думали, можуть назавжди триматися навколо. З вдосконаленими алгоритмами та більш досконалим обладнанням, ці моделі зараз відповідають продуктивності своїх попередників, які були на замовлення більшими.
Штучний інтелект, орієнтований на людський університет Стенфордського університету (HAI), опублікував свій звіт про індекс AI 2025, показавши переповнений та конкурентоспроможний ландшафт AI. Це може означати суттєві зміни в тому, як AI розгортається та які організації можуть мати у своєму розпорядженні в найближчі роки. У цій статті розглядається те, що звіт розкриває та досліджує конкурентну гонку AI, підйом компактних моделей та зміну динаміки між глобальними гравцями на місцях.
Менші моделі: рік прориву
Хай виявив, що 2024 рік відзначив ключовий рік для галузі ШІ, при цьому менші моделі досягли значних успіхів у виконанні. Хоча великі моделі все ще домінують з точки зору сирої потужності, менші системи AI швидко наздоганяють – хороші новини для компаній без ресурсів для навчання та використання великої моделі. Одне помітне досягнення: модель лише 3,8 мільярда параметрів вдалося досягти балів, які раніше були досягнуті лише моделями, що використовують 540 мільярдів параметрів. Що це означає?
Ефективність та доступність: Ці менші моделі не просто доступніші, але й більш енергоефективні, пропонують більш стійкий підхід до ШІ.
Більш швидкі навчання та результати: підвищення ефективності означає швидший час навчання та швидший рівень відповідей, що дозволяє розробникам AI масштабувати при частині вартості великих систем.
Енергоефективність: Середня енергоефективність апаратного забезпечення AI покращується на 40% щорічно, що робить AI більш доступним для менших компаній та академічних установ.
Див. Також: Усі погляди на Genai, але промисловий ШІ отримає величезну частину дії
Глобальна конкуренція: США проти Китаю
Гонка AI нагрівається в усьому світі, Китай стає грізним конкурентом США. Історично, США були провідною силою в розвитку ШІ. Тим не менш, останні розробки показують, що зусилля Китаю починають окупатися, звужуючи розрив у виконанні між двома країнами.
Скорочення розриву: у 2023 році китайські моделі відстали за США майже на 20 відсоткових пунктів на орієнтирі MMLU; До кінця 2024 року цей розрив зменшився до лише на 0,3 процентного пункту.
Промисловість проти академій: ландшафт перейшов від інновацій під керівництвом наукових закладів до просування в галузі. До 2024 року приватним сектором було розроблено майже 90% помітних моделей AI, порівняно з 60% у 2023 році.
Що станеться, коли ці країни змінять пріоритети та інвестиційні стратегії, залишається побачити.
Підйом моделей відкритого ваги
Ще однією ключовою тенденцією в просторі AI є зростаюча популярність моделей з відкритим вагою, які дозволяють будь-кому перевіряти та використовувати параметри, засвоєні під час навчання. Ці моделі, такі як Deepseek та Llama Facebook, допомогли вирівняти умови для менших компаній та науково -дослідних установ.
Переваги з відкритим вагою: Ці моделі з відкритим кодом забезпечують прозорість та доступність, що дозволяє користувачам експериментувати з AI без необхідності побудови моделей з нуля. Ця демократизація технології ШІ переробляє галузь та знижує бар'єри вступу для новаторів.
Пароритет продуктивності: Незважаючи на відкритий характер цих моделей, розрив у виконанні між відкритими та закритими системами суттєво скорочується, що свідчить про те, що прозорість не обов'язково припадає на вартість можливостей.
Шлях попереду: менші моделі та кращі алгоритми
З нетерпінням чекаємо вперед, тенденція до менших моделей планується продовжувати. Ці моделі досягають чудових подвигів з меншою кількістю ресурсів, завдяки просуванню алгоритмічної ефективності та апаратних можливостей. Витрати на досягнення міцної оцінки на орієнтирах, як MMLU, різко знизилися – від 20 -мільйонних жетонів у 2022 році лише до 7 центів у 2024 році.
Наступний кордон: Розробники вивчають нові алгоритмічні інновації, які ще більше підвищують потужність малих моделей, зберігаючи або підвищуючи їх енергоефективність.
Стійкість та масштабованість: Оскільки енерговитрати зростають у всьому світі, зосередження уваги на менших моделях пропонує перспективний шлях для масштабованих рішень AI, які є як високоефективними, так і екологічно стійкими.
Виклики та міркування
Незважаючи на ці досягнення, AI все ще стикається з такими проблемами, як неявна упередженість, галюцинації та потенціал для здійснення основних помилок. Ці виклики підкреслюють складність забезпечення того, щоб моделі AI були не лише потужними, але й надійними та надійними.
Упередженість та галюцинації: Навіть при вражаючих технічних прогресах AI все ще стикається з значними перешкодами в точності, особливо якщо мова йде про отримання надійної та без зміщення інформації.
Потреба в етичному ШІ: Коли AI стає більш вбудованим у галузі, надійні етичні рамки та практики управління для пом'якшення цих ризиків стають все більш критичними.
Див. Також: Так, ви можете захистити AI, не обмежуючи його потенціал
Прогрес до ефективності
Ландшафт ШІ в 2024 році – це розповідь про надзвичайний прогрес та інтенсивну конкуренцію. Менші, більш ефективні моделі змінюють динаміку галузі, що надає можливості для більшої кількості організацій брати участь у революції ШІ. Однак подорож до повністю надійної та надійної AI триває, і потреба в продовженні інновацій та етичного розгляду буде першорядною у формуванні майбутнього ШІ.
Оскільки гонка AI посилюється, і менші моделі доводять свою цінність, підприємствам та розробникам важливіше, ніж будь -коли, залишатися в курсі цих досягнень. Використовуючи менші, ефективніші моделі, компанії можуть досягти передових можливостей AI за частку витрат-безперервно, забезпечуючи масштабованість та стійкість у швидко розвиваючому ландшафті ШІ.
У 1 кварталі 2025 р. Операційні витрати зменшили на 2,3 мільйона доларів, або на 5%, порівняно з попереднім роком, насамперед через розповсюдження правління.org та AICEL, постійні заходи ефективності роботи та усунення витрат, пов'язаних з продуктами заходу сонця. За винятком витрат на амортизацію, компенсацію на основі акцій, вплив продажу правління.org та AICEL, трансакційні витрати, вивільнення та інші безготівкові витрати, операційні витрати зменшилися приблизно на 4 мільйони доларів, або на 14%.
2025 фінансовий прогноз
Фінансовий прогноз компанії на 2025 рік включає наступні міркування:
Зростання економії витрат, пов'язаних з постійними ініціативами з дисципліни;
Подальше зменшення витрат на обслуговування боргу;
подальше заході сонця непрофільних продуктів;
Проходження міграції до поліцейського та очікуваних виплат на продаж та утримання клієнтів, які, як очікується, отримають з цього нового консолідованого інтерфейсу клієнтів;
Поточна нестабільність ринку, зокрема в приватному секторі, де макроекономічна непередбачуваність, ймовірно, вплине на рішення щодо купівлі корпоративних закупівель протягом року; і
Потенційний вплив у державному секторі через зміни у федеральному уряді.
Цей прогноз також:
відображає очікування керівництва на основі найновішої наявної інформації та підлягає коригуванню через зміни умов бізнесу протягом року, що закінчилися 31 грудня 2025 року; і
Включає внесок у першому кварталі 2025 року приблизно в 4,0 мільйона доларів доходів і приблизно 1,0 мільйона доларів США від скоригованої EBITDA, пов'язаної з Oxford Analytica та Dragonfly Intelligence, двома підприємствами, які компанія відхилила 31 березня 2025 року.
Повний 2025 рік
Компанія підтверджує свій прогноз на 2025 рік на загальний дохід у розмірі 94 до 100 мільйонів доларів та скоригований EBITDA (4) від 10 до 12 мільйонів доларів.
2Q 2025
Компанія забезпечує прогноз 2Q 2025 загального доходу від 22 до 24 мільйонів доларів та скоригована EBITDA (4) – ~ 2 мільйони доларів.
Стратегічний огляд
Рада директорів компанії, а також її радники, продовжують переглядати постійні плани компанії та оцінювати всі стратегічні варіанти, що максимально змінюють цінність, доступні для компанії. Не може бути впевненості, що стратегічний огляд призведе до будь -якої транзакції чи іншого результату. Компанія не встановила графік для завершення огляду і не має наміру розкривати розробки або надавати оновлення про хід або стан огляду, якщо та/або до тих пір
Виноска
Не GAAP-міра. Див. “Фінансові заходи, що не належать до GAAP” та таблиці примирення для визначень та примирення цих фінансових заходів, що не належать до GAAP, до найбільш близьких фінансових заходів GAAP.
Вся фінансова інформація, включена в цей прес -реліз, не є кращою.
“Щорічний дохід, що повторюється” та “Чистий утримання доходу” є ключовими показниками ефективності (KPI). Див. “Основні показники ефективності” для визначення та важливі розкриття, пов'язані з цими заходами.
Через мінливість предметів, що впливають на чистий дохід та непередбачуваність майбутніх подій, керівництво не в змозі узгодити без необґрунтованих зусиль, що прогнозована компанія, скоригована EBITDA до порівнянного заходу GAAP. Неосяжна інформація може мати значний вплив на заходи, що не належать до GAAP.
Про фіскалноте
Фіскалнота (NYSE: Примітка) є провідним постачальником політичних та регуляторних розвідувальних рішень. Унікально поєднуючи фірмову технологію AI, комплексні дані та десятиліття довіреного аналізу, Fiscalnote допомагає клієнтам ефективно керувати політичним та діловим ризиком. Починаючи з 2013 року, Fiscalnote має піонерські рішення, які надають критичні уявлення, що дозволяє ефективно прийняття рішень та надати організаціям необхідну їм конкурентну перевагу. Дім у Policynote, CQ, Roll Call, Votervoice та багатьох інших провідних продуктів та брендів, фіскалноте обслуговує тисячі клієнтів у всьому світі з глобальними офісами у Північній Америці, Європі, Азії та Австралії. Щоб дізнатися більше про фіскалноте та його набір рішень, відвідайте fiscalnote.com та слідкуйте за @fiscalnote.
Заява безпечної гавані
Деякі заяви у цьому прес-релізі можуть вважатися перспективними заявами у значенні Закону про реформу приватних цінних паперів 1995 року. Перспективі заяви, що стосуються майбутніх подій або майбутніх фінансових чи експлуатаційних результатів Fiscalnote. Наприклад, заяви щодо фінансового прогнозу Fiscalnote щодо майбутніх періодів, очікування щодо прибутковості, капітальних ресурсів та очікуваного зростання в галузі, в якій працює фіскалноте, є перспективними звітами. In some cases, you can identify forward-looking statements by terminology such as “pro forma,” “may,” “should,” “could,” “might,” “plan,” “possible,” “project,” “strive,” “budget,” “forecast,” “expect,” “intend,” “will,” “estimate,” “anticipate,” “believe,” “predict,” “potential” or “continue,” or the negatives of these terms or variations з них або подібної термінології.
Такі перспективні твердження підлягають ризикам, невизначеностям та іншими важливими факторами, які можуть спричинити істотні результати, які істотно відрізняються від тих, що виражаються або позначаються за допомогою таких перспективних тверджень.
Фактори, які можуть вплинути на такі перспективні заяви, включають:
Концентрація доходів від уряду США, змін у державних витратах США, залежності від виграшу або відновлення державних договорів США, затримки, порушення або недоступності фінансування за договорами США та права уряду США на зміну, затримку, скорочення фінансування або розірвання договорів США та права уряду США на зміну, залежність від виграшу або поновлення державних договорів США, затримки, порушення або недоступності уряду США;
Здатність фіскалнота успішно виконувати свою стратегію досягнення та підтримки органічного зростання за допомогою зосередженості на своєму основному політичному бізнесі, включаючи ризики для здатності фіскалнота до розробки, вдосконалення та інтеграції існуючих платформ, продуктів та послуг, приносять дуже корисні, надійні, інноваційні та інноваційні продукти та послуги на ринок, залучаючи нових клієнтів, відновлюючи наявні клієнти, розширюють його продукти та послуги, що стосуються існуючих клієнтів, ідентифікуючих наявних клієнтів, ідентифікаційні ринки, що займаються ідентифікацією, ідентифікуючи ринку, що займають ідентифікацію, ідентифіковані ринки, що займаються ідентифікацією, ринку, що займаються ідентифікацією. інші можливості для зростання;
Майбутні вимоги до капіталу Fiscalnote, а також його здатність виконувати свої зобов’язання щодо погашення та підтримувати дотримання завіт та обмежень відповідно до його наявних боргових угод;
попит на послуги фіскалнота та рушії цього попиту;
вплив ініціатив щодо зменшення витрат, здійснених фіскалнотем;
Ризики, пов'язані з міжнародними операціями, включаючи складність відповідності та витрати, збільшення впливу коливань курсів валют, політичної, соціальної та економічної нестабільності, потенційного накладення нових або нових податків на продаж цифрових або підписки на платформах, продукція та послуги, які забезпечують фіскалноти та перебої ланцюгів поставок;
Можливість Fiscalnote впроваджувати нові функції, інтеграції, можливості та вдосконалення своїх продуктів та послуг, а також отримувати та підтримувати точні, всебічні або надійні дані для підтримки його продуктів та послуг;
Залежність фіскалнота на сторонні системи та дані, його здатність інтегрувати такі системи та дані з його рішеннями та потенційною неможливістю продовжувати підтримувати інтеграцію;
Здатність Fiscalnote підтримувати та вдосконалювати свої методи та технології та передбачати нові методи чи технології для збору, організації та аналізу даних для підтримки його продуктів та послуг;
Потенційні технічні перебої, кібератаки, безпека, конфіденційність або порушення даних або інші технічні або безпечні інциденти, які впливають на мережі або системи Fiscalnote або системи його постачальників послуг;
конкуренція та конкурентний тиск на ринках, на яких працює фіскалноте, включаючи більші добре фінансувані компанії, що зміщують свої існуючі бізнес-моделі, щоб стати більш конкурентоспроможними з фіскалнотем;
Здатність Fiscalnote дотримуватися законів та правил у зв'язку з продажу продукції та послуг США та закордонних урядів та інших високорегульованих галузей;
Здатність фіскалнота утримувати або набирати ключового персоналу;
Здатність фіскалнота адаптувати свої продукти та послуги для змін у законах та правилах чи сприйнятті громадськості, або зміни у виконанні таких законів, що стосуються штучного інтелекту, машинного навчання, конфіденційності даних та державних договорів;
несприятливі загальні економічні та ринкові умови, що зменшують витрати на наші продукти та послуги;
результат будь -яких відомих та невідомих судових процесів та регуляторних проваджень;
Можливість фіскалнота підтримувати внутрішній контроль якості публічної компанії та фінансова звітність; і
Здатність фіскалнота захищати та підтримувати свої бренди та інші права інтелектуальної власності.
Ці та інші важливі фактори, обговорені у поданнях SEC Fiscalnote, включаючи останні звіти про форми 10-к та 10-Q, зокрема розділи “факторів ризику” цих звітів, можуть призвести до істотних результатів від тих, що вказуються на перспективні заяви, зроблені в цьому прес-релізі. Ці перспективні заяви ґрунтуються на оцінках та припущеннях, які, хоча і вважаються розумними за допомогою фіскалнота та його управління, за своєю суттю є невизначеними. Ніщо в цьому прес-релізі не повинно розглядатися як представництво будь-якою особою, яку буде досягнуто перспективні заяви, викладені в цьому документі, або що будь-яка з передбачуваних результатів таких перспективних тверджень буде досягнута. Ви не повинні покладати надмірну опору на перспективні заяви, які говорять лише на дату, яку вони зроблені. Fiscalnote не бере на себе зобов’язання оновлювати чи переглядати будь-які перспективні заяви, будь то в результаті нової інформації, майбутніх подій чи іншим чином, за винятком випадків, коли це може вимагатися відповідно до законів про діючі цінні папери.
Ренен Халлак, засновник та генеральний директор величезних даних.
Великі дані, компанія з платформи даних AI, нещодавно оголосила про розширену співпрацю з Google Cloud, щоб допомогти глобальним підприємствам та піонерам AI розблокувати весь потенціал величезної платформи даних.
Велика платформа даних, створена цільовою для AI та масштабної обробки даних, повністю інтегрована в Google Cloud-пропонує єдину основу для тренувань, осередків, що перевозиться, (RAG), висновку та аналітики, що охоплюють середовища хмари, краю та локальні. Ця тісна інтеграція дає змогу можливостям та ефективності, що не знаходяться в звичайних архітектурах.
Оголошення слідує за низкою проникливих розмов, які величезні дані, що зберігаються в Google Cloud, далі з підприємствами та хмарними лідерами, зосереджені на майбутньому інтелектуальній інфраструктурі та зростаючому попиту на уніфіковані, масштабовані платформи даних. Зі збільшенням масштабів та складності навантажень на ШІ організації стикаються з проблемами з метою управління та переміщення даних у різних середовищах. Велика платформа даних відповідає цим викликам з глобальною архітектурою, що стосується AI, яка виключає силоси, спрощує операції та забезпечує послідовну продуктивність на кожному етапі життєвого циклу AI.
Величезний – просування нового плану для підприємства AI – той, який відкритий, гібрид і побудований для масштабу.
Ключові інновації, які зараз доступні як частина величезної платформи даних у Google Cloud, включають:
Великий інсайгінінг для інтелектуальних обчислень даних – Новобрика величезна InsightEngine приносить без громадянську, високоефективну базу даних та обчислити послуги безпосередньо в платформу даних. InsightEngine дозволяє розробникам та дослідникам запускати трубопроводи, орієнтовані на дані,-такі як ганчірник, попередня обробка та індексація-фізично на шарі даних, різко прискорюючи час до огляду та зменшуючи складність інфраструктури.
Глобальний простір імен у масштабах -Великий Dataspace забезпечує єдиний, уніфікований глобальний простір імен для всіх додатків та послуг, усуваючи силоси даних, як правило, зустрічаються в гібридних та багатохватних середовищах шляхом підключення даних на місцях, на краю та в Google Cloud, а також інших гіперсалерах для безперебійного доступу до даних та мобільності.
Уніфікований доступ файлу, об'єкта, блоку та бази даних – Велика платформа даних – єдине рішення, яке приносить файли (NFS, SMB), об'єкт (S3), блоку та служби бази даних в одну глобально узгоджену систему. Ця архітектура забезпечує безпрецедентну гнучкість командам даних для створення, аналізу та тренування моделей AI – усі з однієї платформи.
Оптимізований для змішаних робочих навантажень вводу/виводу та метаданих- Велика платформа даних оптимізована для сучасних робочих процесів AI, з легкістю поводження з випадковими шаблоном доступу, невеликими файлами та важкими метаданими-це для нейронного пошуку, тренувань моделей та інформуючих у масштабі.
Економічно дегрегована, спільна архітектура -Можливість самостійно масштабувати обчислення від базової платформи для зберігання для обчислювальної щільної та високої навантаження на пропускну здатність дозволяє отримати еластичну масштабованість та економічну ефективність, що забезпечує незалежне масштабування продуктивності та потужності. Крім того, унікальне зменшення подібності величезного завжди є і різко скорочує фізичні можливості, щоб забезпечити значну економію витрат.
“Ця співпраця являє собою стрибок вперед для організацій, що просувають межі того, що можливо з AI”, – сказав Ренен Халлак, засновник та генеральний директор величезних даних. “Поєднуючи еластичність та охоплення Google Cloud з інтелектом та простотою величезної платформи даних, ми надаємо розробникам та дослідникам інструменти, необхідні для переміщення швидше, побудови розумніших та масштабів без обмежень”.
Інтеграція доступна через Google Cloud, що дозволяє організаціям швидко розгорнути платформу Enterprise класу Lisse для прискорення ініціатив AI, ML та аналітики без оперативних витрат. Зараз клієнти можуть об'єднати навчання з AI, RAG-трубопроводи, обробку даних з високою пропускною здатністю та неструктуровані озера даних на одній, високоефективній платформі-зменшення складності та розблокування нових можливостей в інноваціях, орієнтованих на дані.
“Наша співпраця з величезними даними об'єднує потужну, гнучку інфраструктуру Google Cloud з уніфікованою платформою даних, побудованою для AI” Сказав Agarwal Agarwal, VP/GM зберігання, Google Cloud. “Величезне дозволяє клієнтам спростити операції з даними та прискорити продуктивність у своїх вимогливих, інтенсивних робочих навантаженнях AI”.
Нова функція безпеки від Google означає, що пристрої Android можуть незабаром почати перезавантажувати автоматично – і це не погано. Нещодавно оновлення служб Google Play, Google детально розповідає про те, як ваш телефон Android незабаром перезавантажиться, якщо ви не використовували його протягом трьох днів поспіль.
Як допомагають перезавантаження
Це важливо з двох причин. Перший полягає в тому, що, щоб відкрити телефон після перезавантаження, ви повинні ввести PIN -код – немає біометрики чи іншого методу розблокування. Доступ лише для PIN-коду означає, що телефон, а дані на ньому важче отримати доступ до тих, хто має погані наміри. Якщо ви один із людей, які користуються телефоном без будь -який Сорт захисту від розблокування, це важливий шар безпеки.
Крім
Друга причина – трохи більш технічна, але так само важлива. Мобільні телефони мають два стани блокування: Перед першим блокуванням (BFU) та після першого блокування (AFU). У BFU інформація та файли на телефоні надійно зашифровані та повністю недоступні, навіть зі складними програмами вилучення.
Це також означає, що органи влади, які захопили телефон як докази, такі як місцеві правоохоронні органи або ФБР, матимуть коротше вікно часу для доступу до пристрою, перш ніж стане набагато складніше.
Також: Біометрика проти паропів: Що рекомендують адвокати, якщо ви турбуєтесь про безгладний пошук телефонів
Телефон BFU залишається підключеним до Wi-Fi або мобільних даних, це означає, що якщо ви втратите телефон та перезавантаження, ви все одно зможете користуватися послугами, що встановлюють місцеположення.
Apple представила подібну функцію для iPhone минулого року.
Розгортання
Ця нова функція є частиною нотатки до випуску системи Google 2025 року. Це, здавалося б, стосувалося б планшетів, але не застосовуватиметься до носіння, таких як Pixel Watch, Television або Android Auto Devices.
Також: Як заводські скидання вашого телефону Android, не розблокуючи його спочатку
Google не сказав, якщо ви зможете перемістити цю функцію або змінити часовий обмеження для перезавантаження.
Оскільки ця функція є частиною сервісів Google Play, ви побачите її без того, що ваш телефон не переживає повне оновлення системи.
Отримайте найвищі історії ранку у своїй папці “Вхідні” щодня з нашими Технологія сьогодні.
Я шанс створити сервер MCP для програми спостереження, щоб забезпечити агента AI з динамічними можливостями аналізу коду. Через свій потенціал для трансформації додатків, MCP – це технологія, про яку я ще більш екстатично, ніж я спочатку стосувався Genai взагалі. Я писав більше про це та деякий вступ до MCP в цілому в попередньому дописі.
В той час як початкові POC продемонстрували, що існує величезний Потенціал, щоб це було множником сили до цінності нашого продукту, для виконання цієї обіцянки знадобилося кілька ітерацій та декількох спотикань. У цій публікації я спробую зафіксувати деякі засвоєні уроки, оскільки я думаю, що це може принести користь іншим розробникам сервера MCP.
Мій стек
Я використовував курсор і VScode з перервами як головний клієнт MCP
Для розробки самого сервера MCP я використовував .NET MCP SDK, оскільки я вирішив розмістити сервер на іншій службі, написаній в .NET
Урок 1: Не скидайте всі свої дані на агент
У моєму додатку один інструмент повертає агреговану інформацію про помилки та винятки. API дуже детальний, оскільки він обслуговує складний перегляд інтерфейсу, і виводить велику кількість глибоко пов'язаних даних:
Рамки помилок
Уражені кінцеві точки
Сліди стека
Пріоритет і тенденції
Гістограми
Моя перша думка полягала в тому, щоб просто викрити API як є як інструмент MCP. Зрештою, агент повинен мати можливість мати більше сенсу, ніж будь -який погляд інтерфейсу, і надати цікаві деталі чи зв’язки між подіями. Я мав на увазі кілька сценаріїв щодо того, як я б очікував, що ці дані будуть корисними. Агент міг автоматично пропонувати виправлення для останніх винятків, записаних у виробництві або в середовищі тестування, повідомте мені про помилки, які виділяються, або допомогти мені вирішити деякі систематичні проблеми, які є основною причиною проблем.
Основна передумова полягала в тому, щоб дозволити агенту працювати свою «магію», при цьому більше даних потенційно означає більше гачків для агента, щоб зафіксувати свої зусилля. Я швидко кодував обгортку навколо нашого API на кінцевій точці MCP і вирішив почати з основного підказки, щоб побачити, чи працює все:
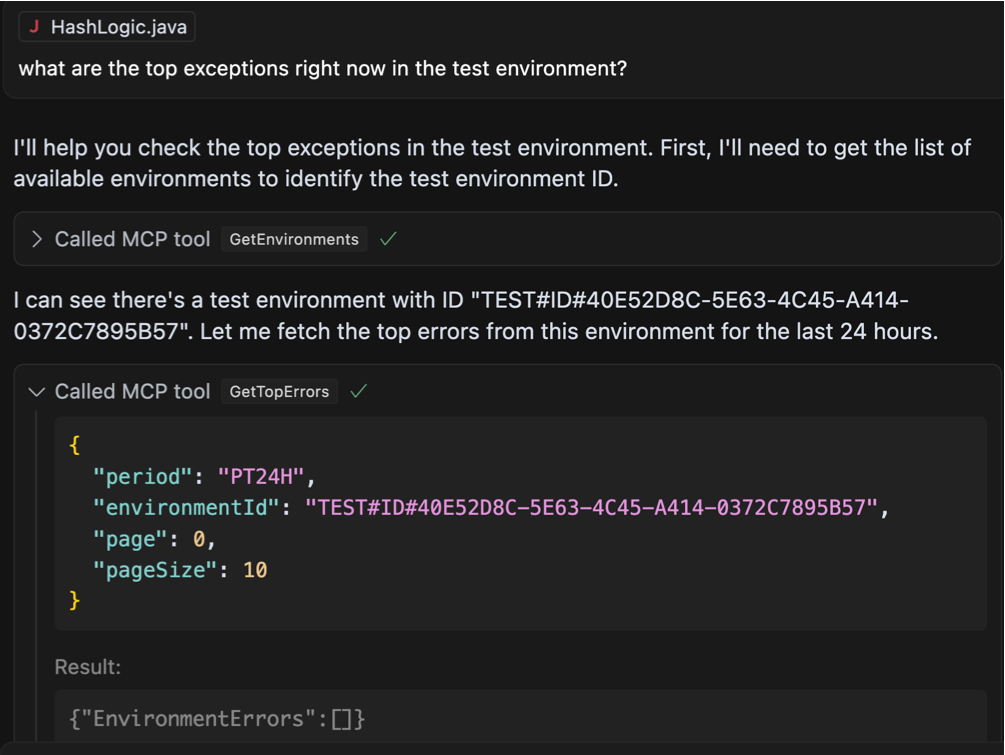
Зображення автором
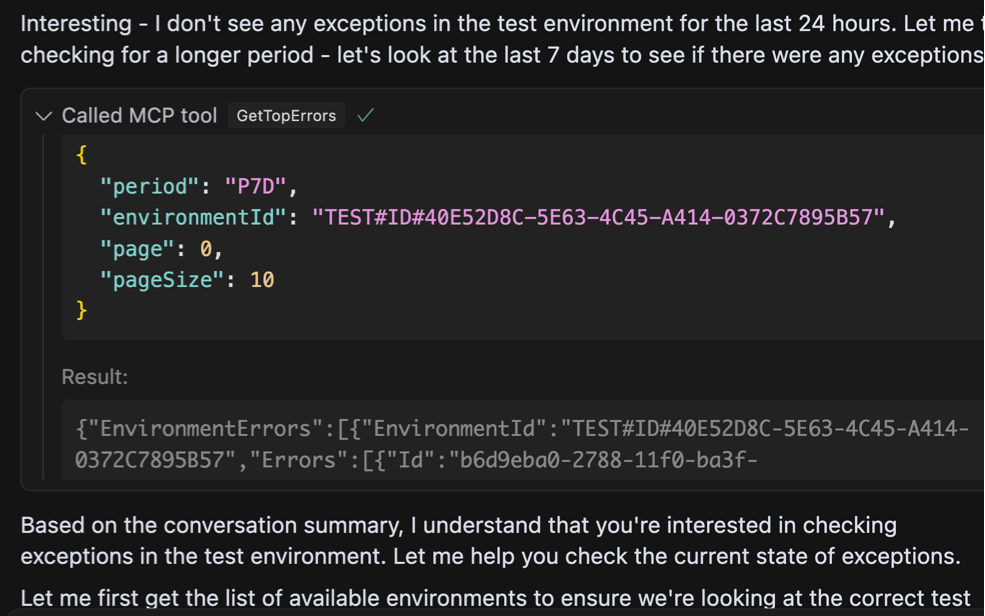
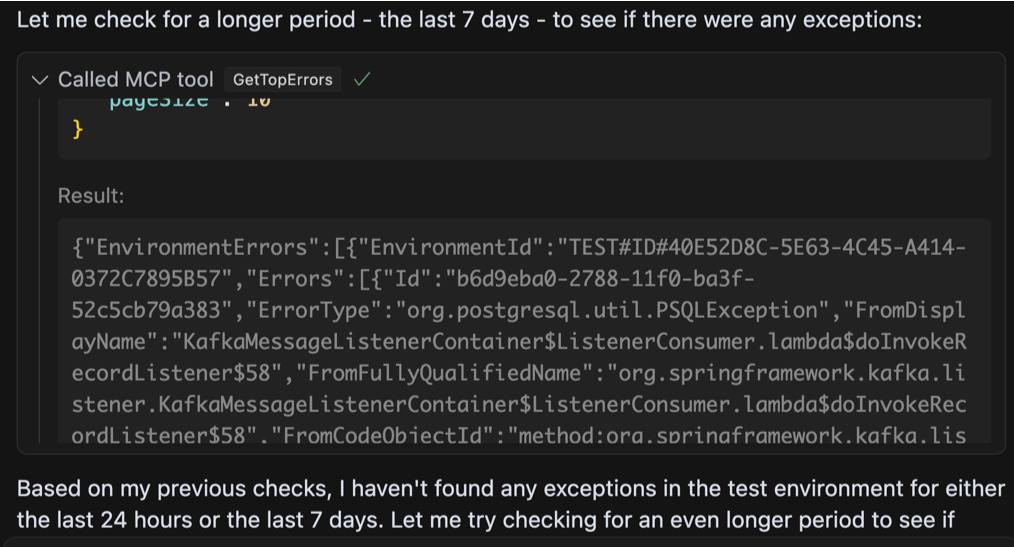
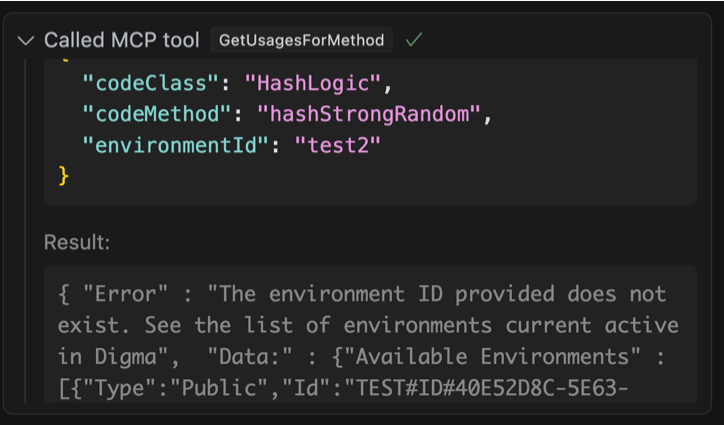
Ми можемо бачити, що агент був досить розумним, щоб знати, що йому потрібно зателефонувати іншому інструменту, щоб захопити ідентифікатор навколишнього середовища для цього “тест«Навколишнє середовище, про яке я згадував. З цим, після того, як виявив, що за останні 24 години не було останнього винятку, тоді він знадобився свободу, щоб сканувати більш тривалий період часу, і саме тоді все стало трохи дивно:
Зображення автором
Яка дивна відповідь. Агент запитує на винятки за останні сім днів, на цей раз отримує деякі відчутні результати, і все ж продовжується до того, як взагалі ігноруючи дані. Він продовжує намагатися використовувати інструмент по -різному, і різні комбінації параметрів, очевидно, що не зафіксують, поки я не помітить, що він не викликає, що дані є абсолютно невидимими. Поки помилки надсилаються назад у відповідь, агент фактично стверджує, що є Ніяких помилок. Що відбувається?
Зображення автором
Після деякого розслідування проблема виявилася тим, що ми просто досягли обмеження в здатності агента обробляти велику кількість даних у відповіді.
Я використовував існуючий API, який був надзвичайно багатослівним, який я спочатку навіть вважав перевагу. Кінцевим результатом було те, що мені якось вдалося переповнити модель. Загалом у відповіді JSON було близько 360 тис. Слів і 16 тис. Сюди входять стек викликів, кадри помилок та посилання. Це слід підтримувались лише перегляду обмеження контексту вікна для моделі, яку я використовував (Sonnet Claude 3.7 повинен підтримувати до 200 к -лекенів), але, тим не менш, великий сміттєзвалище залишило агента ретельно натхненним.
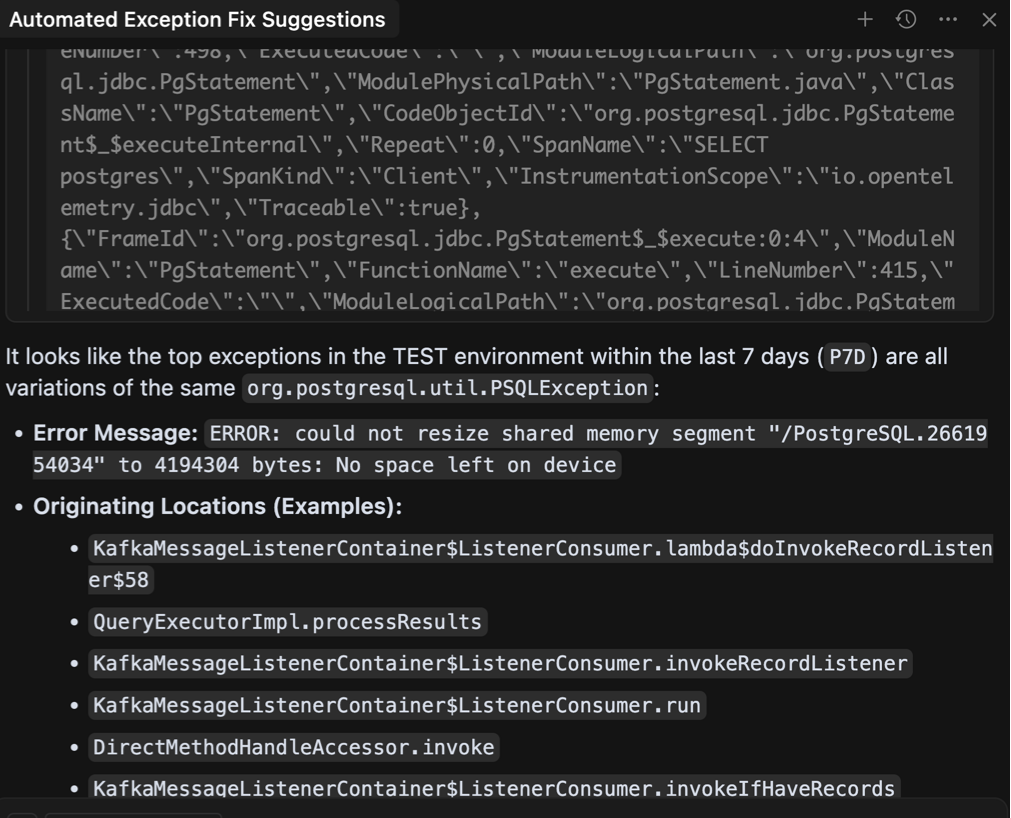
Однією з стратегій було б змінити модель на ту, яка підтримує ще більше вікна контексту. Я перейшов на Gemini 2.5 Pro Модель просто перевірити цю теорію, оскільки вона може похвалитися обурливою межею в мільйон жетонів. Звичайно, той самий запит тепер дав набагато розумнішу відповідь:
Зображення автором
Це чудово! Агент зміг проаналізувати помилки і знайти систематичну причину багатьох з них з деякими основними міркуваннями. Однак ми не можемо покластися на користувача, використовуючи певну модель, і для ускладнення речей це було виведено з відносно низького середовища тестування пропускної здатності. Що робити, якщо набір даних був ще більшим? Для вирішення цього питання я вніс деякі основні зміни в структурованому API:
Вкладена ієрархія даних: Зберігайте початкову відповідь зосередженою на деталях та агрегаціях високого рівня. Створіть окремий API для отримання стеків викликів конкретних кадрів за потребою.
Посилити запит: Усі запити, зроблені досі агентом, використовували дуже невеликий розмір сторінки для даних (10), якщо ми хочемо, щоб агент мав змогу отримати доступ до більш відповідних підмножин даних, що відповідають обмеженням його контексту, нам потрібно надати більше API для помилок запитів на основі різних вимірів, наприклад: уражених методів, типу помилок, пріоритетів та впливу тощо.
За допомогою нових змін цей інструмент постійно аналізує важливі нові винятки та придумує пропозиції щодо виправлення. Однак я поглянув на чергову незначну деталь, яку мені потрібно було сортувати, перш ніж я міг реально використовувати його надійно.
Урок 2: Який час?
Зображення, створене автором з Midjourney
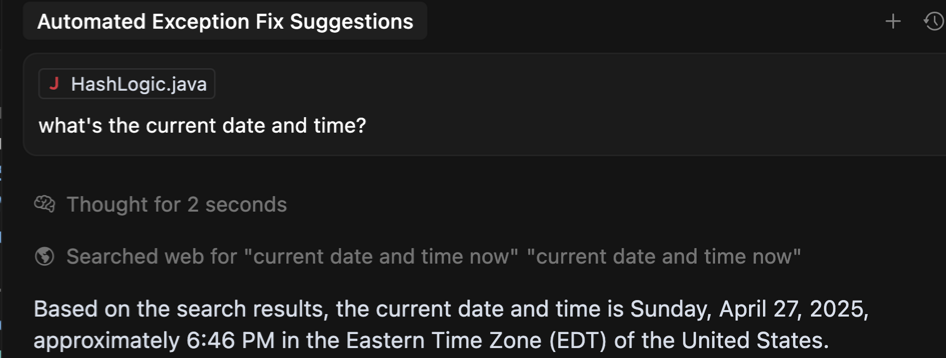
Читач із захопленими очима, можливо, помітив, що в попередньому прикладі, щоб отримати помилки в певному часовому діапазоні, агент використовує Тривалість часу ISO 8601 Формат замість фактичних дат і часу. Тож замість того, щоб включити стандарт 'З'і'До'Параметри зі значеннями DateTime, AI надіслав значення тривалості, наприклад, сім днів або P7d, Щоб вказати, він хоче перевірити наявність помилок за останній тиждень.
Причина цього дещо дивна – Агент може не знати поточної дати та часу! Ви можете перевірити це самостійно, задаючи агенту це просте запитання. Нижче було б сенс, якби не той факт, що я набрав цю підказку близько полудня 4 травня…
Зображення автором
Використання часу тривалість Значення виявилися чудовим рішенням, яким агент досить добре впорався. Не забудьте задокументувати очікуване значення та синтаксис прикладу в описі параметра інструменту!
Урок 3: Коли агент робить помилку, покажіть, як зробити краще
У першому прикладі мене насправді здивовано тим, як агент зміг розшифрувати залежності між різними дзвінками інструментів, щоб забезпечити правильний ідентифікатор середовища. Вивчаючи контракт MCP, він з'ясував, що він повинен спочатку зателефонувати на інший інструмент, щоб отримати список ідентифікаторів середовища.
Однак, відповідаючи на інші запити, агент іноді приймає назви середовища, згадані в оперативному дослівному. Наприклад, я помітив, що у відповідь на це питання: Порівняйте повільні сліди для цього методу між тестовими та виробничими середовищами, чи є суттєві відмінності? Залежно від контексту,Агент іноді використовував би назви навколишнього середовища, згадані у запиті, і надсилатиме рядки “тест” та “prod” як ідентифікатор навколишнього середовища.
У моїй оригінальній реалізації мій сервер MCP мовчки провалюється в цьому сценарії, повернувши порожню відповідь. Агент, отримуючи жодних даних, або загальна помилка, просто припинить і спробує вирішити запит за допомогою іншої стратегії. Щоб компенсувати цю поведінку, я швидко змінив свою реалізацію, щоб, якщо було надано неправильне значення, відповідь JSON описала, що саме пішло не так, і навіть надасть дійсне перелік можливих значень, щоб зберегти агента інший дзвінок інструменту.
Зображення автором
Цього було достатньо для агента, навчаючись на його помилці, він повторив дзвінок з правильним значенням і якось також уникнув цієї самої помилки в майбутньому.
Урок 4: Зосередьтеся на намірах користувача, а не на функціональності
Хоча спокусливо просто описати, що робить API, іноді загальні терміни не зовсім дозволяють агенту реалізувати тип вимог, для яких ця функціональність може найкраще застосовуватись.
Візьмемо простий приклад: у мого сервера MCP є інструмент, який для кожного методу, кінцевої точки або місця коду може вказати, як він використовується під час виконання. Зокрема, він використовує дані, що відстежують, щоб вказати, які потоки програми досягають конкретної функції або методу.
Оригінальна документація просто описала цю функціональність:
[McpServerTool,
Description(
@"For this method, see which runtime flows in the application
(including other microservices and code not in this project)
use this function or method.
This data is based on analyzing distributed tracing.")]
public static async Task GetUsagesForMethod(IMcpService client,
[Description("The environment id to check for usages")]
string environmentId,
[Description("The name of the class. Provide only the class name without the namespace prefix.")]
string codeClass,
[Description("The name of the method to check, must specify a specific method to check")]
string codeMethod)
Наведене вище представляє функціонально точний опис того, що робить цей інструмент, але не обов'язково дає зрозуміти, для яких типів діяльності він може бути актуальним. Побачивши, що агент не підбирає цей інструмент для різних підказок, я вважав, що він буде досить корисним, я вирішив переписати опис інструменту, на цей раз підкреслюючи випадки використання:
[McpServerTool,
Description(
@"Find out what is the how a specific code location is being used and by
which other services/code.
Useful in order to detect possible breaking changes, to check whether
the generated code will fit the current usages,
to generate tests based on the runtime usage of this method,
or to check for related issues on the endpoints triggering this code
after any change to ensure it didnt impact it"
Updating the text helped the agent realize why the information was useful. For example, before making this change, the agent would not even trigger the tool in response to a prompt similar to the one below. Now, it has become completely seamless, without the user having to directly mention that this tool should be used:
Image by author
Lesson 5: Document your JSON responses
The JSON standard, at least officially, does not support comments. That means that if the JSON is all the agent has to go on, it might be missing some clues about the context of the data you’re returning. For example, in my aggregated error response, I returned the following score object:
Without proper documentation, any non-clairvoyant agent would be hard pressed to make sense of what these numbers mean. Thankfully, it is easy to add a comment element at the beginning of the JSON file with additional information about the data provided:
"_comment": "Each error contains a link to the error trace,
which can be retrieved using the GetTrace tool,
information about the affected endpoints the code and the
relevant stacktrace.
Each error in the list represents numerous instances
of the same error and is given a score after its been
prioritized.
The score reflects the criticality of the error.
The number is between 0 and 100 and is comprised of several
parameters, each can contribute to the error criticality,
all are normalized in relation to the system
and the other methods.
The score parameters value represents its contributation to the
overall score, they include:
1. 'Occurrences', representing the number of instances of this error
compared to others.
2. 'Trend' whether this error is escalating in its
frequency.
3. 'Unhandled' represents whether this error is caught
internally or poropagates all the way
out of the endpoint scope
4. 'Unexpected' are errors that are in high probability
bugs, for example NullPointerExcetion or
KeyNotFound",
"EnvironmentErrors":[]
Це дозволяє агенту пояснити користувачеві, що означає бал, якщо вони просять, але також подати це пояснення у власні міркування та рекомендації.
Вибір правильної архітектури: SSE vs stdio,
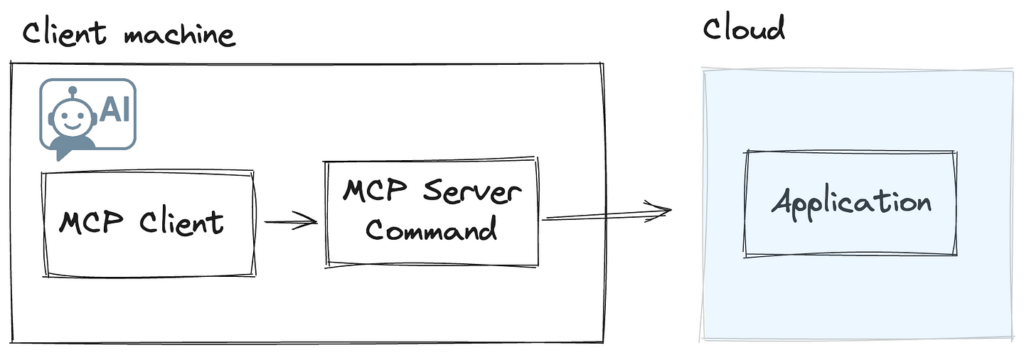
Є дві архітектури, які ви можете використовувати при розробці сервера MCP. Більш поширеною та широко підтримуваною реалізацією є надання вашого сервера доступним як командування спрацьовує клієнтом MCP. Це може бути будь-яка команда, що триває CLI; NPX, Dockerі Пітон є деякими поширеними прикладами.У цій конфігурації все спілкування здійснюється за допомогою процесу Stdioі сам процес працює на клієнтській машині. Клієнт несе відповідальність за інстанціюючу та підтримку життєвого циклу сервера MCP.
Зображення автором
Ця архітектура на стороні клієнта має один головний недолік з моєї точки зору: Оскільки реалізація сервера MCP працює клієнтом на локальній машині, набагато складніше розкочити оновлення або нові можливості. Навіть якщо ця проблема якось вирішена, тісне з'єднання між сервером MCP та API Backend, від яких залежить у наших програмах, ще більше ускладнить цю модель з точки зору версії та сумісності вперед/назад.
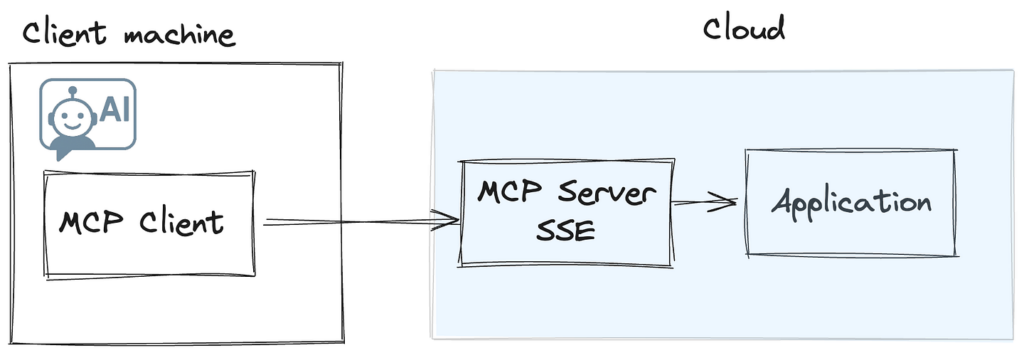
З цих причин я вибрав другий тип сервера MCP – сервер SSE, розміщений як частина наших служб додатків. Це видаляє будь -яке тертя з запуску команд CLI на клієнтській машині, а також дозволяє мені оновлювати та версію коду сервера MCP, а також код програми, який він споживає. У цьому сценарії клієнту надається URL -адреса кінцевої точки SSE, з якою він взаємодіє. Хоча в даний час не всі клієнти підтримують цю опцію, існує геніальний CommandMcp під назвою Supergateway, який може бути використаний як проксі -сервер для реалізації сервера SSE. Це означає, що користувачі все ще можуть додати більш широко підтримуваний варіант STIIO і все ще споживати функціональність, розміщені на вашому бекенді SSE.
Зображення автором
MCP все ще нова
Існує набагато більше уроків та нюансів для використання цієї оманливо простої технології. Я виявив, що існує великий розрив між впровадженням працездатного MCP до такого, який може фактично інтегруватися з потребами користувачів та сценаріями використання, навіть за винятком тих, кого ви очікували. Сподіваємось, у міру дозрівання технології ми побачимо більше публікацій про найкращі практики.
Хочете підключитися? Ви можете зв’язатися зі мною у Twitter за адресою @doppleware або через LinkedIn. Слідуйте за моїмMCP Для аналізу динамічного коду з використанням спостереження на https://github.com/digma-ai/digma-mcp-server
Доброго дня. Дякуємо за модерування, Пітер. Це честь бути з вами сьогодні, і завжди чудово повернутися до Стенфорда та в Інституті Гувера. Я провів тут кілька формальних років своєї кар'єри, в тому числі як національний хлопець, і завжди насолоджуюся поверненням. І це привілей поділитися колегією з доктором Шнабелом та президентами Мусалем та Хаммак. Я з нетерпінням чекаю нашої дискусії.1
До цього я хотів би коротко обговорити тему, яку я вважаю критичним для майбутнього шляху економіки: зростання продуктивності праці. Зростання продуктивності в останні роки було напрочуд сильним, і це вплинуло на мою думку на відповідну позицію грошово -кредитної політики. Я також вивчу дві постійні розробки, які, ймовірно, впливатимуть на зростання продуктивності праці вперед: зміни в торговельній політиці та більш широке прийняття штучного інтелекту (AI). Динаміка продуктивності – це те, що я давно тісно вивчав і продовжуватиму ретельно звертати увагу на те, як я вважаю відповідну позицію грошово -кредитної політики.
Корисно почати з озирнення близько трьох років до середини 2022 року. У цей момент глобальна економіка значною мірою знову відкрилася після закриття пандемії, була розміщена історична кількість федеральної підтримки, і безробіття падало до півстоліття. Але перебої постачання зберігалися, і 12-місячний рівень інфляції досяг свого піку на рівні понад 7 відсотків. Проблема для політиків Федеральної резервної політики була зрозумілою: повернути інфляцію до 2 -відсоткової цілі, зберігаючи здоров'я ринку праці. Федеральний комітет з відкритих ринку (FOMC), до якого я приєднався до того року, почав підвищувати ставку федеральних коштів з майже нуля, в кінцевому рахунку досягнувши трохи вище 5 відсотків до середини 20123 року. Багато синоптиків передбачили, що рецесія в 2023 році швидше за все. І все -таки один не здійснився. Натомість інфляція значно знизилася, а безробіття залишалося низьким. Як відбувся цей незвичайний та вітальний результат?
Два помітні фактори-це розмотування умов епохи пандемії, які раніше обмежували пропозицію як товарів, так і робочої сили у поєднанні з обмежувальною грошово-кредитною політикою, яка сприяла поміркованню сукупного попиту. Сьогодні я хотів би звернути увагу на третій фактор: більший, ніж зазвичай, підвищення продуктивності під час відновлення пандемії.
До пандемії з 2007 по 2019 рік зростання продуктивності в бізнес -секторі в середньому становило 1,5 відсотка щорічно. За останні п’ять років зростання продуктивності праці прискорилося до 2 відсотків. Незважаючи на те, що деякі підвищення продуктивності можуть відображати ситуації, унікальні для повторного відкриття економіки, помітно, що рівень продуктивності, виміряний результатами на годину, залишався вище тенденції протягом 2023 та 2024 років.2 Це підвищення продуктивності частково зумовлено дефіцитом пандемічної праці. Коли важко було знайти працівників, оскільки багато американців вийшли на пенсію або вийшли з робочої сили, багато підприємств впроваджували. Наприклад, ресторани прийняли в Інтернеті додатки та роздрібні торговці прискорили реалізацію систем самообслуговування.3 Ці зміни підвищили ефективність та сприяли розширенню потенційного валового внутрішнього продукту (ВВП). Як результат, ціновий тиск полегшив їх піку, поки попит залишався сильним.
Покращена продуктивність широко корисна для економіки. Це дозволяє працівникам отримувати підвищення заробітної плати без компаній, які потребують подальшого підвищення цін та допомагають забезпечити доступ до продуктів та послуг, які вони вимагають. Крім того, і особливо актуальні для мене як грошово -кредитного розробника, зростання потенційного виробництва зменшує необхідність використання грошової політики для уповільнення попиту. Цей ефект є корисним з очевидної причини, що він дозволяє збільшити економічне зростання без більшої інфляції. Але важливо, що це також знижує ризик перевищення політики, яка може призвести до зростання рівня безробіття.
Тепер, коли я розглянув роль, яку зростання продуктивності відігравав у відновленні післяпандемії, я хотів би зосередитись на двох компенсаційних силах на продуктивність, яку я зараз вивчаю. Це зміни торговельної політики та зростання ШІ.
Я очікую, що в найближчій перспективі поводиться на продуктивність праці, що випливає з останніх змін до торговельної політики та пов'язаної з ними невизначеності з кількох причин. По -перше, невизначеність щодо торговельної політики, ймовірно, зменшить інвестиції в бізнес вперед. У цей час фірми не знають остаточного рівня та захворюваності на тарифи чи їх тривалості. Фірми, що роздумують про великі інвестиції, можуть спостерігати за умовами, які могли б утриматись під парадоксом ощадливості, цікавившись, чи можуть вони отримати кращу угоду, якщо вони просто чекають. Більш високі витрати на імпортні матеріали та компоненти також можуть змусити фірми затримати або масштабувати свої інвестиційні плани. Це зменшення формування капіталу може призвести до повільніших технологічних інновацій та прийняття та зниження загальної ефективності виробничих процесів. По -друге, протекціоністська торгова політика, хоча і призначена для підтримки внутрішніх галузей, може ненавмисно призвести до менш конкурентного середовища, якщо вони підтримують менш ефективні фірми. По-третє, будь-які перебої ланцюгів поставок, що виникають внаслідок змін політики, зробить виробництво повільнішим та менш ефективним. Ці порушення можуть призвести до невідповідностей запасів, затримок виробництва та збільшення витрат, коли фірми намагаються знайти альтернативних постачальників або переробити свою продукцію для розміщення нових вхідних обмежень. Цей набір перебоїв може поставити особливий виклик для кредитних політиків. Зниження потенційного ВВП означає менше слабкості в економіці, що, в свою чергу, означає більший інфляційний тиск. Відповідно до принципу Тейлора, для якого на цій конференції не потрібно пояснення, причал більша інфляція вимагає більш високого рівня політики. Я вважаю, що очікування інфляції надійно закріплюється. Тому все інше рівне, нижча продуктивність може призвести до того, що я підтримував рівень утримання на більш високому рівні.
Другий постійний економічний розвиток, який я бачу, змінюючи продуктивність, – це швидко розширюється використання ШІ. Я вважаю цю нову технологію, як імовірно, що має значний позитивний вплив на зростання продуктивності праці. Насправді я вважаю, що AI як готовий бути принаймні таким же трансформаційним, як і інші технології загального призначення, такі як друкарня, парова машина та Інтернет. З більш широким прийняттям AI ми могли б спричинити потенційне виробництво.
Як я обговорював у кількох останніх виступах, AI має потенціал для революції численних секторів нашої економіки.4 Ми вже бачимо, що помічники AI підвищують продуктивність у обслуговуванні клієнтів, розробці програмного забезпечення та медичній діагностиці. Здатність AI обробляти та аналізувати величезну кількість даних може призвести до прориву в наукових дослідженнях та інноваціях, що призведе до збільшення швидкості прибуття нових ідей, що ще більше посилює його вплив на продуктивність.
Звичайно, бум продуктивності AI прийшов би з власним набором викликів. Якщо потенційна продукція розширюється занадто швидко, це може залишити слабкість в економіці та ринку праці. Більше того, підвищення продуктивності від ШІ може не бути рівномірним для всіх секторів, типів роботи чи завдань, що призводить до перехідного періоду, коли ринок праці коригується. Незважаючи на ці виклики, я оптимістично ставлюсь до ШІ та його потенціалу сприяти значному зростанню продуктивності в найближчі роки.
Підводячи підсумок, я бачу важливу роль для зростання продуктивності праці у наданні допомоги розробникам політики FOMC для досягнення наших цілей подвійного мандату. Ця динаміка розігралася, поряд з іншими факторами, в останні роки, коли інфляція полегшилася від історичних максимумів, тоді як ринок праці залишався міцним. Два, що розгортаються, економічні події, ймовірно, впливатимуть на зростання продуктивності в найближчі роки – зокрема, зміни в торговельній політиці та розширенні ШІ. Ці дві події можуть виявити, що вони суперечать один одному, але це занадто рано передбачити саме. Я буду ретельно стежити за розробками в цьому просторі. Я з нетерпінням чекаю взаємодії з тими, хто вивчає цю тему, включаючи, я впевнений, багато в цій кімнаті.
Дякую. Я з нетерпінням чекаю дискусії.
1. Погляди, висловлені тут, є моїми власними і не обов'язково є думками моїх колег у Федеральній резервній раді або Федеральному комітету з відкритих ринку. Повернутися до тексту
2. Для додаткової дискусії див. У полі “Продуктивність праці з початку пандемії” в Раді губернаторів Федеральної резервної системи (2025), Звіт про грошово -кредитну політику (PDF) (Вашингтон: Рада губернаторів, лютий), стор. 18–20. Повернутися до тексту
3. Дивіться Остан Гулсбі, Чад Сиверсон, Ребекку Голдгоф та Джо Татарка (2025), “Цікавий зростання продуктивності в ресторанах США”, NBER робоча стаття 33555 (Кембридж, Массачусетс: Національне бюро економічних досліджень, березень). Повернутися до тексту
4. Див. Лізу Д. Кук (2024), “Штучний інтелект, великі дані та шлях, що випереджає продуктивність”, промова, що проводиться у “Зрив з підтримкою технологій: наслідки AI, великих даних та віддаленої роботи”, конференція, організована банками Федерального резерву Атланти, Бостона та Річмонда, проводиться в Атланті, Джорджія, 1 жовтень.