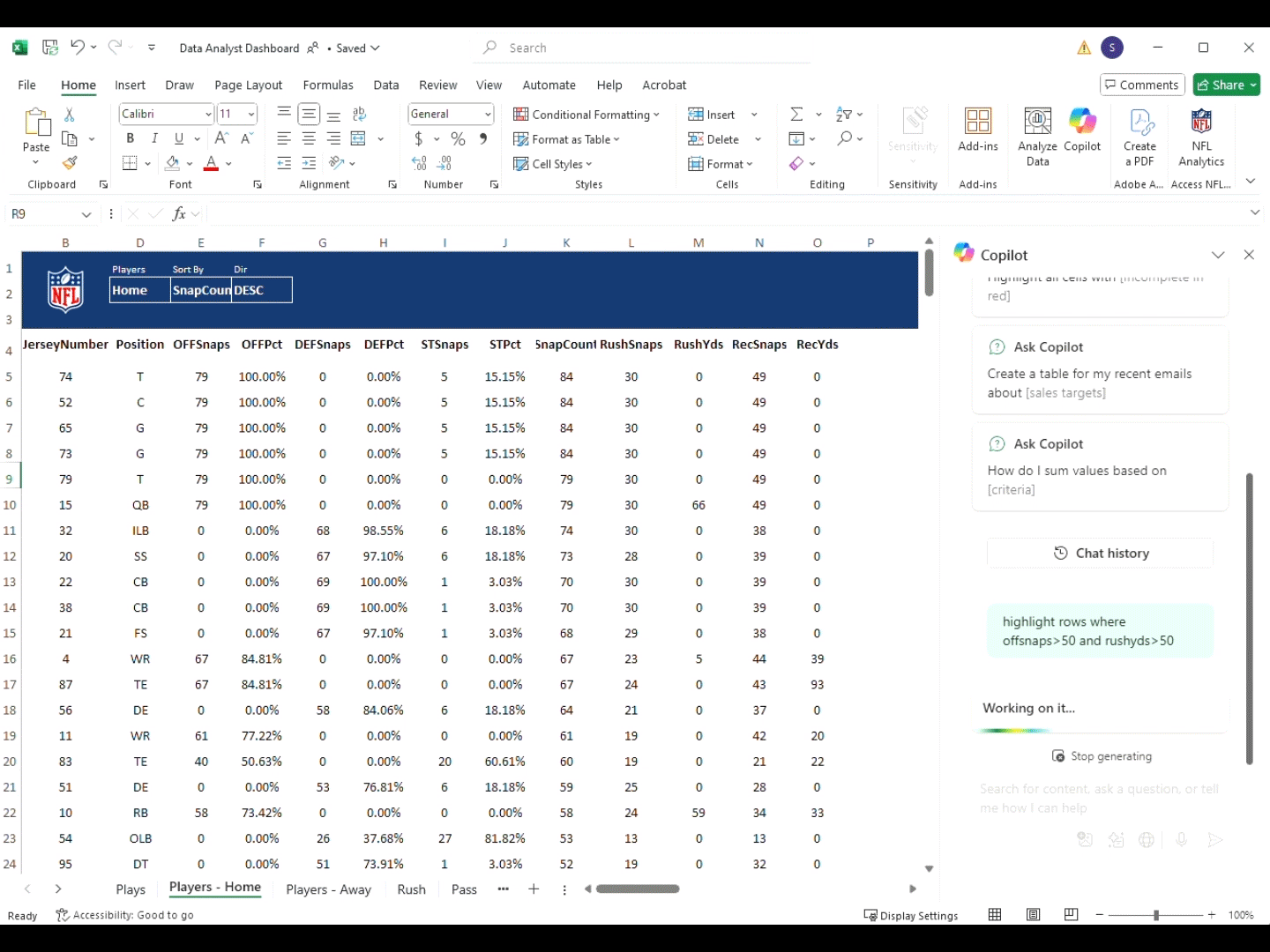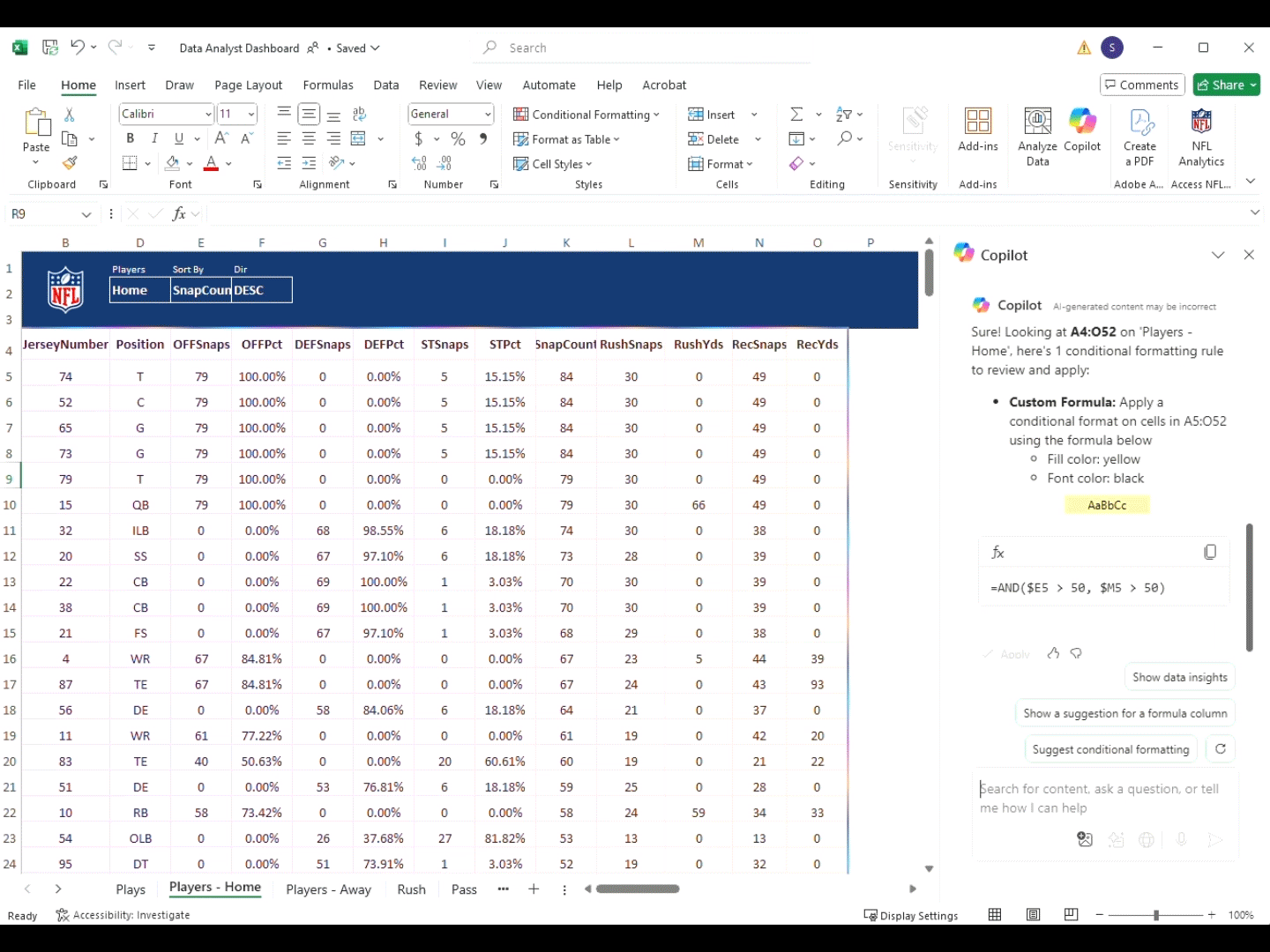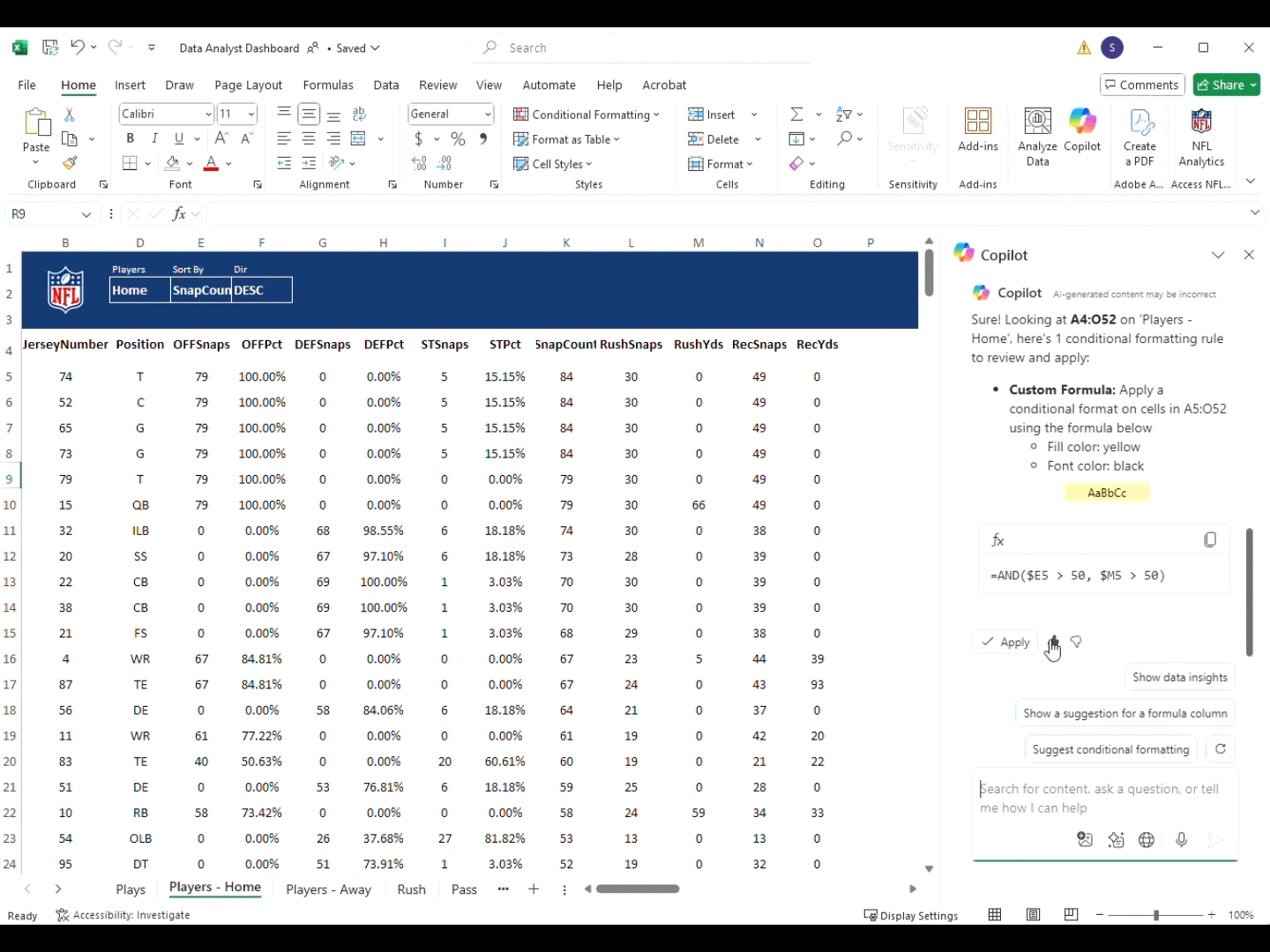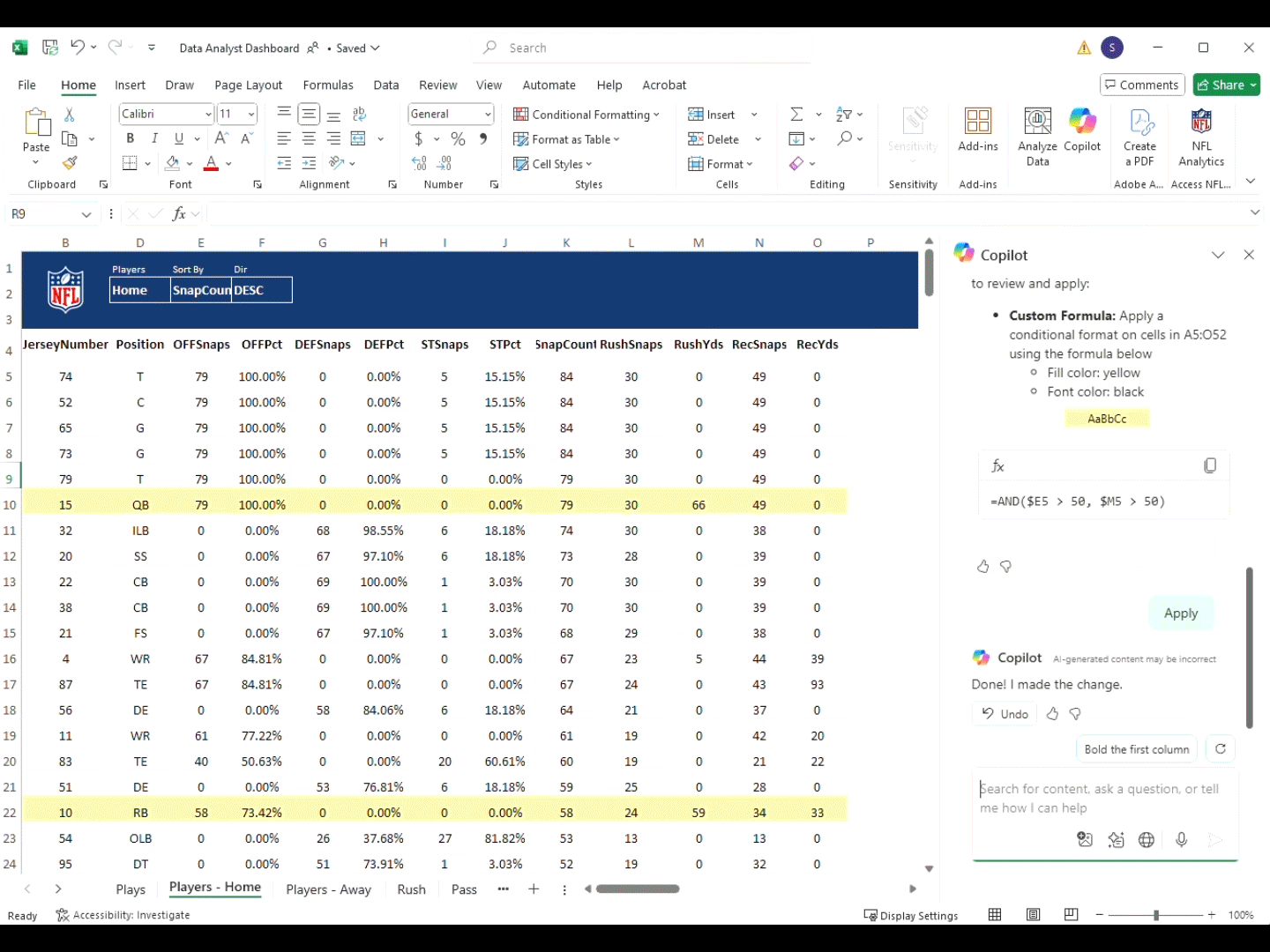
Експериментальна установка
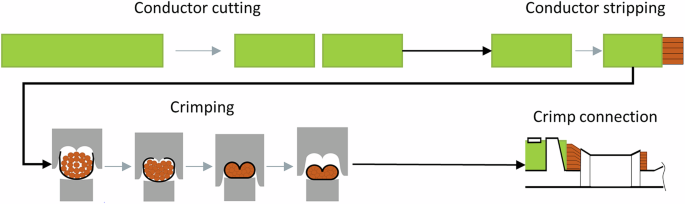
Усі обтисні операції проводилися за допомогою напівавтоматичної обтисної машини7який автоматично годує клеми, тоді як провідники вручну вставляються оператором. На наступному малюнку (рис. 2) представлено схематичне представлення напівавтоматичного процесу обтисання.

Блок-діаграма напівавтоматичного обтиснення.
Обтисна машина, використана в цьому дослідженні, працює за допомогою ексцентричної преси і здатна обтиснути ділянки дротяного перехрестя до 6 мм2 з максимальною силою 20 кН. Детальні технічні характеристики машини наведені в таблиці 1. Машина обладнана датчиком сили8який був встановлений безпосередньо на з'єднувальному стрижні пресу. Датчик постійно фіксує застосовану силу під час обтиску, при цьому кожне обтисне з'єднання призводить до захоплення однієї кривої сили. Це призводить до одновимірного, дискретного часового ряду, в якому сигнал датчика змінюється через кут обертання преси, тим самим ефективно представляючи криву переміщення сили.
Набір даних кривих сил5 складається з двох чітких провідно-кінцевих пар: по-перше, 16-ядерна, 0,50 мм2 Flry-B мідний провідник у поєднанні з роз'ємом MLK 1,2 Sm Ag F-Crimp, по-друге, 12-ядерним, 0,35 мм2 Flry-B мідний провідник у поєднанні з терміналом MLK 1.2 ELA F-Crimp. Для збору даних використовуються два модульні інструменти швидкої зміни (MQC), кожен з яких налаштований для однієї з конкретних комбінацій провідника. Стандартизована система MQC дозволяє повне обмін інструментами при перемиканні продукту на обтисну машину. Цей підхід забезпечує повторювані умови виробництва та запобігає ненавмисним коригуванню функціональних компонентів, тим самим підтримуючи послідовність у серійному виробництві та в різних експериментальних тестах. Ці стандартизовані інструменти відрізняються лише двома специфічними для продуктів компонентів, обтиму та ковадлу, які спеціально підібрані виробником інструментів на основі геометрії та типу провідника та терміналу. Як показано на рис. 3 (с), лише обтимка та ковадло містять функціональні поверхні та торкаються матеріалу під час роботи.

Експериментальна установка для збору даних (), Вигляд крупного плану інструменту MQC в експлуатації (б) та схематичне зображення компонентів, що стосуються продукту, та функціональних поверхонь (c.).
Обтисна машина, використана в цьому дослідженні, не підтримує операції з різання або зачистки провідників, отже, ці підготовчі кроки проводили вручну за допомогою контактного проводу Phoenix 109 інструмент для зачистки. Цей інструмент здатний зачиняти провідників з поперечним перерізом від 0,02 до 10 мм2 і дозволяє зачиняти довжину до 18 мм. Хоча довжина зачистки була точно визначена для експериментів, довжина різання провідника не була стандартизована, оскільки це не впливає на криву обтиску. Отже, незначні зміни, спричинені ручною операцією в довжині різання, були переносилися та не задокументовані. Інтегрований дріт -різець інструменту для зачистки був використаний з метою різання. І навпаки, фіксовану довжину зачистки визначали для розмежування прийнятних (OK) та несправних (NOK) зразків, враховуючи значний ефект, який має тривалість зачистки на криву сили обтисків. Для зразків ОК довжина зачистки встановлювалася на 4 мм. Для зразків NOK класу обтисної ізоляції було використано тривалість зачистки 3 мм. Початкова перевірка довжини зачистки проводилася за допомогою візуального огляду експертами, які навчаються процесам, які оцінювали підданий провідник та ступінь ізоляції в рамках обтиску. Окрім зразків ОК, було навмисно створено дві часто спостерігаються дефектні категорії: відсутні нитки та обертання ізоляції. Клас відсутніх ланцюгів був підрозділений на три підкласи, зразки з видаленими одним, двома або трьома нитками. Для того, щоб створити їх, провідники були зняті до довжини ОК 4 мм, після чого зазначена кількість нитків була вилучена вручну. Що стосується класу обтисної ізоляції, диригент був позбавлений до визначеної NOK довжиною 3 мм, внаслідок чого часткова ізоляція обтисна. Вичерпний огляд процедур підготовки для всіх трьох класів якості наведено на рис. 4.
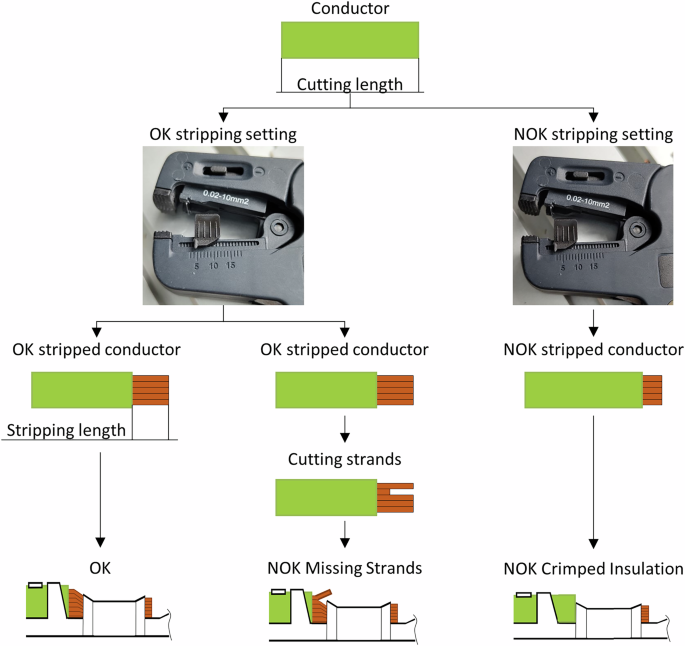
Етапі підготовки вручну трьох класів якості в напівавтоматичному робочому процесі.
Агрегація даних та анотація
Набір даних складається з ряду менших експериментів, проведених у рамках проекту під назвою «Розробка аналізу кривої сили на основі машинного навчання для цілісного моніторингу процесів та оцінки якості зв'язків CREMP (DeepCrimpact)». Незважаючи на послідовне виконання записів протягом наступних сеансів, всі експерименти проводилися в послідовних лабораторних умовах, використовуючи матеріал з однієї партії та стандартизованої методології, тим самим забезпечуючи порівнянність записів. Збір даних здійснювався різними підготовленими професіоналами, мінімізуючи ймовірність мінливості, пов'язаної з оператором, що впливає на вимірювання кривої сили. Використання стандартизованої процедури ще більше зменшило потенційний вплив зовнішніх факторів, таких як час доби. Крім того, найсучасніша система моніторингу сили обтисків10 (BB07I) був включений в експериментальну установку, яка здатна виявити відхилення процесів у режимі реального часу. Значні відхилення, такі як спричинені неправильним поводженням, були б позначені як NOK, тим самим забезпечуючи додаткову гарантію проти зовнішніх впливів. Враховуючи агрегацію менших серій до одного всебічного набору даних, важливо зазначити, що набір даних не був навмисно розроблений для збалансованого в різних класах якості. Натомість мета полягала в тому, щоб генерувати уніфікований, репрезентативний набір даних в умовах стабільних процесів. Цей підхід дозволяє користувачам впроваджувати конкретні стратегії балансування, які підходять до конкретних контекстів додатків. Розподіл класу викладено в таблиці 2.
Набір даних складається із загальної кількості 2439 кривих обтискних сил, з яких 1222 мають провідний переріз 0,50 мм2 і 1217 мають 0,35 мм2. 1628 кривих сил можуть бути віднесені до класу якості ОК, 297 до обтисної ізоляції, 172 до класу з однією відсутньою ниткою, 291 – до класу з двома відсутніми нитками та 51 до класу трьох відсутніх нитків. На малюнку 5 показані зразкові криві сили різних зразків провідника та клас якості з їх специфічними характеристиками. Очевидно, що 0,50 мм2 Провідник вимагає більш високої сили обтиску порівняно з 0,35 мм2 провідник. Крім того, зразки, класифіковані як обтисна ізоляція, демонструють помітно крутий нахил кривої сили, що починається приблизно з точки даних 150 даних, незалежно від поперечного перерізу провідника. На відміну від цього, клас відсутніх нитки дефектів демонструє лише незначний вплив на загальну форму кривої сили, з менш вираженими відхиленнями.
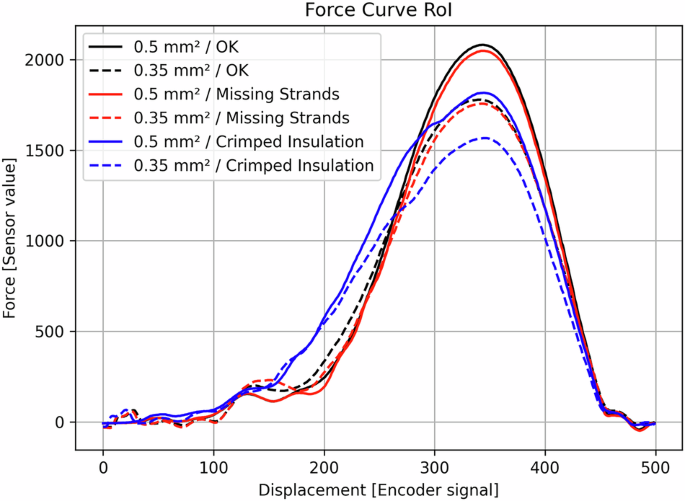
Зразкові екземпляри трьох класів якості та їх вплив на криву сили обтисків.
Обробка даних
Кожна записана крива сили автоматично зберігалася як файл CSV і призначила унікальний ідентифікатор (обтиски) інтегрованою системою моніторингу сили обтисків10. На додаток до придбання сигналу сили сили, позначеного як “крива сили сировини” і складається з 3566 точок даних, система також здійснила виявлення аномалії в режимі реального часу, порівнюючи вимірювану криву з попередньо записаною посиланням на ОК. Після процесу порівняння класифікація кожного зразка автоматично визначалася як OK, або NOK. Етикетка класифікації була вбудована безпосередньо у відповідний файл CSV поряд із обрізними та примусовими даними. Як раніше розмежовано, зразки провідника готували відповідно до заздалегідь визначених класів якості. Для того, щоб забезпечити відстеження та запобігання перехресному забрудненню класів, була реалізована спеціальна структура папки, з окремим каталогом, призначеним кожному класу якості. Під час збору даних кожна партія якості зразків була записана незалежно. Наприклад, 50 зразків ОК для 0,50 мм2 Провідник спочатку був записаний та зберігався у визначеному каталозі OK. Цей процес повторювали для подальших партіїв, таких як 100 обтисних ізоляційних зразків, шляхом вручну переходу на відповідну папку до запису. Впровадження структурованої системи каталогів гарантувало чітке та систематичне розділення різних класів якості. За винятком ручного вибору відповідного каталогу папки, не потрібно було проводити подальші етапи анотації під час процесу збору даних. Система автоматично зберігала всі відповідні дані про якість, тим самим заперечуючи вимогу до ручного втручання в цьому плані. Робочий процес даних схематично проілюстровано на рис. 6.
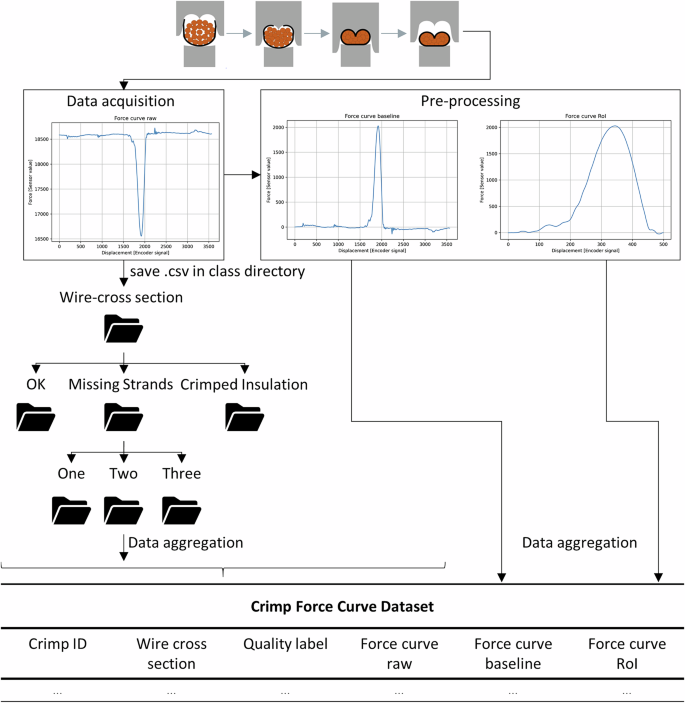
Робочий процес агрегації даних.
Згодом загалом 2439 файлів CSV було отримано з визначених каталогів, специфічних для метаданих. Файли завантажували та агрегували в один панд -кадр Pandas, де кожна «крива сили сили» зберігалася як безліч масиву для подальшої обробки. Як попередній етап попередньої обробки, кожна крива була перевернута для врахування орієнтації на перевернуту датчика інтегрованої сили. Крім того, корекція базової лінії застосовувалася шляхом віднімання початкового читання датчика з усієї кривої. Це гарантувало, що всі криві сили почалися на загальному еталонному рівні (y = 0), тим самим дозволяючи змістовне порівняння між зразками. Перетворення, що застосовується до кожної кривої сили сили \ ({F} _ {raw} =[{F}_{raw0},{F}_{raw1},\ldots ,{F}_{raw3565}]\) визначається наступним рівнянням:
$$ {f} _ {baseline} =-{f} _ {raw}+{f} _ {raw0} $$
(1)
Однак лише специфічний сегмент, який називається область, що цікавить (ROI), зазвичай зберігається для аналізу кривої обтисків. Ця рентабельність інвестицій була визначена за консультацією з експертами з трьох різних промислових партнерів та проміжками з точки даних 1575 до 2074 року. Вилучення рентабельності інвестицій з базової кривої \ ({F} _ {baseline} =[{F}_{baseline0},{F}_{baseline1},\ldots ,{F}_{baseline3565}]\) можна офіційно визначити як:
$$ {f} _ {roi} =[{F}_{baseline1575},{F}_{baseline1576},\ldots ,{F}_{baseline2074}]$$
(2)
Таким чином, отримана рентабельність інвестицій містить 500 точок даних і служить основною функцією введення для аналізу кривої обтисків. Незважаючи на те, що датчик сили записує додаткові дані до та після цього інтервалу, ці сегменти не є актуальними для оцінки якості обтисків, оскільки обтис не контактує з терміналом до та після цього інтервалу. Визначення відповідного регіону та особливостей якості підлягає різниці між виробниками моніторингу кривої кривих сил. Тому крива сирої сили також надається в наборі даних. Наприклад, система, використана в цьому дослідженні, використовує три чіткі області під кривою, щоб розмежувати з'єднання OK або NOK. Фіг.7 ілюструє процес перетворення від кривої сирого датчика до вилученої області, що цікавить.
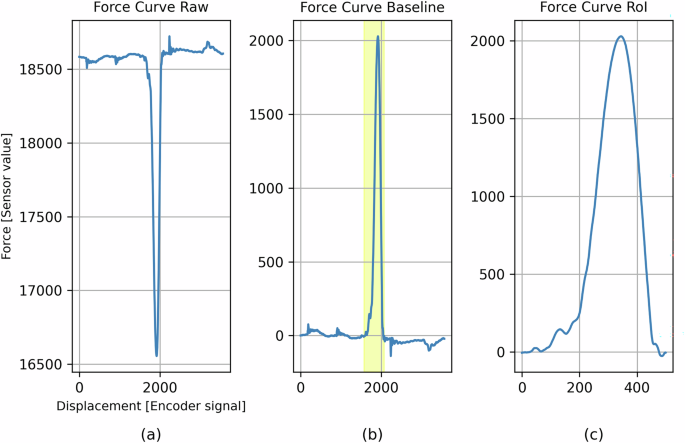
Етапи обробки від сирої кривої () до базової лінії (б) та регіон інтересу (c) із зразкового екземпляра.




 Джером Пауелл приїжджає на вечерю під час симпозіуму економічної політики Джексона Хоула Канзас -Сіті в Морані, штат Вайомінг, 21 серпня.
Джером Пауелл приїжджає на вечерю під час симпозіуму економічної політики Джексона Хоула Канзас -Сіті в Морані, штат Вайомінг, 21 серпня.