Мідь має життєво важливе значення для підтримки швидкого зростання центрів обробки даних по всьому світу, що дозволяє нам використовувати нові технології штучного інтелекту (AI) і генеративного AI (GenAI). У цьому поясненні пояснюється, чому мідь важлива для цієї нової технології, а також зростаючий вплив штучного інтелекту та центрів обробки даних на глобальний попит на мідь.
Для отримання додаткової інформації відвідайте наш блог: «BHP Insights: як мідь сформує наше майбутнє».
Інструменти ШІ та GenAI змінюють те, як ми працюємо, створюємо та взаємодіємо. Незалежно від того, чи йдеться про Microsoft Copilot, ChatGPT від OpenAI, Gemini та Dall-E від Google або про включення функціональних можливостей штучного інтелекту в уже широко використовувані програми, такі як Microsoft Word і Adobe Photoshop, інтерес процвітає в останні роки.1
Голосові помічники на основі штучного інтелекту стають все більш популярними серед споживачів, але також спостерігається сплеск інтересу великих підприємств до використання ШІ для вирішення бізнес-завдань.
Легко зрозуміти чому. Ці захоплюючі інструменти штучного інтелекту пропонують потенційне підвищення ефективності в нашій роботі, в управлінні повсякденним життям і можуть допомогти нам досліджувати та розвивати нові концепції та ідеї.
Але попри всі їхні сильні сторони, вони настільки хороші, наскільки потужні процесори, що стоять за ними. У цьому партнерстві технологія штучного інтелекту може бути мозком, але центри обробки даних забезпечують м’язи.
Інструменти на основі штучного інтелекту вимагають надшвидкої обробки даних, зберігання та пошуку даних, щоб впоратися з ресурсомістким навчанням і розгортанням складних моделей машинного навчання та алгоритмів, які забезпечують їх роботу. Центри обробки даних забезпечують цей швидкий обчислювальний потенціал.2
За останнє десятиліття будівництво центрів обробки даних зростало, щоб підтримати зростання оцифрування та хмарних обчислень. Однак за останні два роки будівництво в Сполучених Штатах подвоїлося, згідно з даними Міжнародної енергетичної асоціації (МЕА).3 (див. діаграму нижче), оскільки великі гравці, такі як Amazon, Alphabet і Microsoft, вкладають значні кошти, щоб спробувати випередити попит, керований ШІ.
Інші країни, такі як Китай, Японія та Європейський Союз, також відчули збільшення будівництва центрів обробки даних. Наприклад, у квітні 2024 року Microsoft оголосила про інвестиції в розмірі 2,9 мільярда доларів США протягом наступних двох років у центри обробки даних у Японії, щоб розвинути свій ШІ та хмарну інфраструктуру, після того, як у листопаді 2023 року виділила 3,2 мільярда доларів США протягом трьох років на будівництво центру обробки даних у Великобританії. .
Де в цьому рівнянні входить мідь? Що ж, центри обробки даних потребують величезної кількості міді для їх будівництва, особливо для їхніх мереж живлення, друкованих плат і систем охолодження. Дослідження об’єкта центру обробки даних Microsoft вартістю 500 мільйонів доларів США в Чикаго виявило, що він використовує 2177 тонн міді, що еквівалентно 27 тоннам міді на кожен мегават (МВт) прикладеної потужності.4
Центри обробки даних також потребують великої кількості енергії для функціонування. Як для виробництва такої енергії, так і для її доставки до центру обробки даних потрібна мідь. За даними МЕА,3 Великі гіпермасштабні центри обробки даних, які стають все більш поширеними, потребують електроенергії 100 МВт або більше, тобто річне споживання електроенергії еквівалентно споживанню приблизно від 350 000 до 400 000 електромобілів.
Основні технологічні компанії намагаються зафіксувати електроенергію з низьким рівнем викидів парникових газів (ПГ), щоб забезпечити свої енергоємні центри обробки даних. Наприклад, у вересні компанія Constellation Energy оголосила про свій намір відновити роботу реактора першого блоку на АЕС Три-Майл-Айленд поблизу Гаррісбурга, штат Пенсільванія. Цей крок підкріплений новою угодою про постачання електроенергії з Microsoft, що передбачає постачання електроенергії з низькими викидами парникових газів для зростаючі активи центру обробки даних.
Таким чином, мідь використовується не лише в будівництві центрів обробки даних, вона важлива в об’єктах, які генерують для них електроенергію, та в інфраструктурі, яка доставляє цю електроенергію до них. Оскільки інвестиції в будівництво центрів обробки даних стрімко зростають, це стає рушієм попиту на світовому ринку міді.
Ця нова тенденція була висвітлена в нашому нещодавньому блозі «BHP Insights: як мідь сформує наше майбутнє», де в рамках ширшої дискусії про мідь ми розглянули, як «цифровий» підвищить глобальний попит на мідь у найближчі роки. «Цифровий» попит означає зростання попиту на мідь, оскільки світ створює та споживає величезні обсяги даних, завдяки центрам обробки даних, які потребують міді.
За нашими оцінками, обсяг міді, що використовується в центрах обробки даних, зросте в шість разів до 2050 року – з приблизно півмільйона тонн міді сьогодні до приблизно 3 мільйонів тонн на рік до 2050 року. Це зростання приблизно еквівалентно сумарному річному виробництву чотири найбільші мідні шахти світу на сьогодні.
Ми також очікуємо, що глобальне споживання електроенергії з центрів обробки даних зросте з приблизно 2 відсотків загального світового попиту на електроенергію сьогодні до 9 відсотків до 2050 року. У деяких країнах ця частка вже вища – наприклад, в Ірландії центри обробки даних вже становлять п’яту частину. від загального споживання електроенергії в країні.3
Ми не єдині в таких прогнозах електроенергії. МЕА очікує чогось подібного. Але, як повідомляє МЕА,3 незважаючи на це зростання, центри обробки даних все ще не будуть домінуючим рушієм на світовому ринку електроенергії: «Хоча зростання цифрових технологій, включаючи розвиток штучного інтелекту, є одним із факторів, постійне економічне зростання, електромобілі, кондиціонери та зростаюча важливість електроенергії інтенсивне виробництво є більшим рушійним фактором», – йдеться в документі.
Незважаючи на це, вплив штучного інтелекту на зростання центрів обробки даних і енергоспоживання залишається значним – і тому люди зараз говорять про «цифру» також у зв’язку з попитом на мідь.
Щоб отримати додаткову інформацію та наші прогнози щодо глобального попиту на мідь, прочитайте наш блог «BHP Insights: як мідь сформує наше майбутнє».
Що таке дата-центр?
Центр обробки даних — це фізичний об’єкт, у якому розміщено багато комп’ютерних серверів, з’єднаних високошвидкісними мережами, які забезпечують паралельну обробку та надшвидкий час обробки. Це дає змогу швидко збирати, обробляти, зберігати та отримувати дані, необхідні для ефективної обробки складних алгоритмів машинного навчання ШІ.
Центри обробки даних мають бути готові, доступні та здатні до надшвидкої обробки, зберігання й пошуку даних 24/7.
Для цього цим центрам потрібні найновіші комп’ютерні чіпи, розміщені в серверних блоках, таких як новий Nvidia GB200 NVL72, який був запущений у 2024 році та включає в себе графічний процесор Blackwell B200, описаний як найпотужніший чіп у світі.5 Стверджується, що цей новий чіп має в чотири рази більші можливості обробки ШІ, ніж його попередник Nvidia6 а сама Nvidia, за оцінками, мала 98-відсоткову частку світового ринку графічних процесорів для центрів обробки даних у 2023 році.7 Новий пристрій GB200 має понад 5000 мідних кабелів загальною довжиною понад 3,2 кілометра.8
Центр обробки даних об’єднує багато сотень цих пристроїв, щоб забезпечити можливості обробки та зберігання даних нового рівня.
Чому мідь важлива для центрів обробки даних?
Мідь використовується в багатьох сферах центру обробки даних, зокрема:
- У мікросхемах, проводці, шинах і роз’ємах живлення в самих серверах
- У системах охолодження в серверах і для ЦОД
- Для кабелів передачі та з’єднань живлення в центрі обробки даних
- Для зовнішнього кабелю для доставки живлення до центру обробки даних
- В інфраструктурі, яка використовується для генерації електроенергії, необхідної для їх роботи, особливо якщо ця енергія виробляється з таких джерел, як сонячна або вітрова електростанція.

Підпис: Виробництво катодної міді на BHP Escondida, Чилі. Цей високоякісний матеріал цінується за свою електропровідність.
Сплески будівництва ЦОД
Будівництво центрів обробки даних зростало до останнього попиту на штучний інтелект. З 2018 по 2023 рік кількість гіпермасштабованих центрів обробки даних у всьому світі подвоїлася (з 448 до 992).9 Цей попит на центри обробки даних був зумовлений обчислювальними програмами, споживчими програмами для зберігання даних (наприклад, Netflix) і постійним впровадженням корпоративних хмар.
Наприклад, коли ваш телефон виконує резервне копіювання в хмару, це, по суті, зберігає інформацію в центрі обробки даних або ряді центрів обробки даних десь по всьому світу, коли вона вам знадобиться наступного разу.
Але за даними Macquarie Data Centres, ШІ потребує в 10 разів більше ресурсів, ніж хмара.2 Швидке впровадження штучного інтелекту за останні пару років призвело до різкого зростання інвестицій у центри обробки даних, як показує ця таблиця від IEA.
Інвестиції в центри обробки даних у США, січень 2014 – серпень 2024
(Вісь Y: грудень 2019 р. = 1)

Джерела: аналіз МЕА на основі даних Бюро перепису населення США
IEA (2024), Інвестиції в центри обробки даних у Сполучених Штатах, січень 2014 – серпень 2024, IEA, Париж https://www.iea.org/data-and-statistics/charts/investment-in-data-centres-in -the-united-states-january-2014-august-2024, Ліцензія: CC BY 4.0
Виноски:
1 22 найпопулярніші статистичні дані та тенденції AI у 2024 році – радник Forbes – жовтень 2024 року
2 Що таке дата-центр штучного інтелекту і як він працює – липень 2024
3 Що може означати бум центрів обробки даних та штучного інтелекту для енергетичного сектору – аналіз – IEA – жовтень 2024 р.
4 Чому мідь критична для центрів обробки даних – Visual Capitalist – жовтень 2023 р
5 Nvidia представляє графічний процесор Blackwell B200, «найпотужніший у світі чіп» для штучного інтелекту – The Verge – травень 2024 р.
6 Графічний процесор нового покоління Nvidia зі штучним інтелектом у 4 рази швидший за Hopper – Tom's Hardware – березень 2024 р.
7 Nvidia поставила 3,76 мільйона графічних процесорів для центрів обробки даних у 2023 році – домінує в бізнесі з 98-відсотковою часткою доходу – Tom's Hardware – червень 2024 року
8 Придивіться до звіра DGX GB200 NVL72 від Nvidia – The Register – і березень 2024 року
9 Гіпермасштабні центри обробки даних у всьому світі 2023 – Satista – червень 2024
Для отримання додаткової інформації відвідайте наш блог: «BHP Insights: як мідь сформує наше майбутнє»
Щоб дізнатися більше про те, як знайти та видобути родовища міді стало дедалі складніше, відвідайте наш блог: «Візуалізовано: основні відкриття міді з 1990 року».


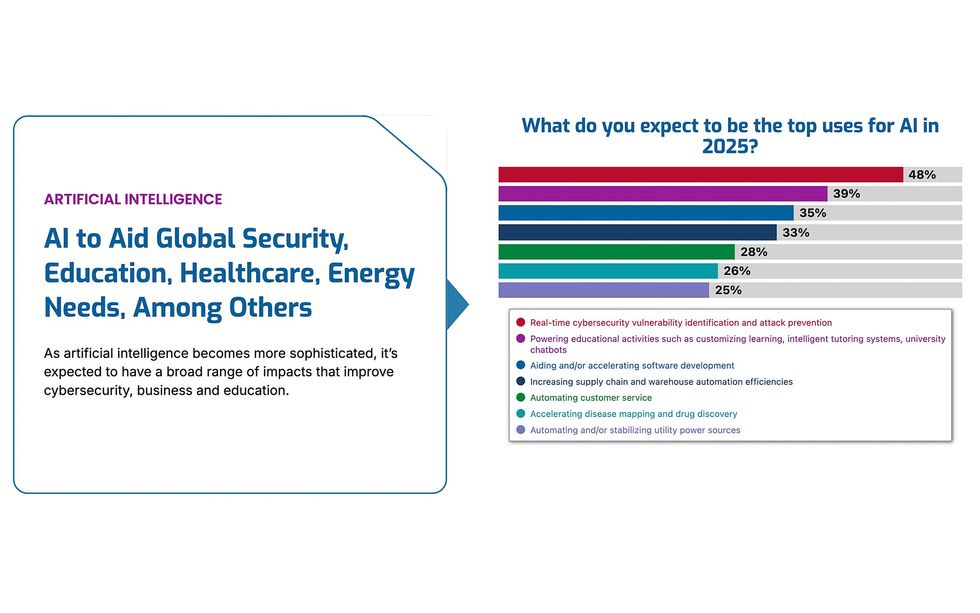 350 ІТ-директорів, технічних директорів, ІТ-директорів та інших світових технологічних лідерів, які взяли участь у опитуванні, будуть використовувати штучний інтелект.Передавач IEEE
350 ІТ-директорів, технічних директорів, ІТ-директорів та інших світових технологічних лідерів, які взяли участь у опитуванні, будуть використовувати штучний інтелект.Передавач IEEE














