Кейт Бернот
Пиво залишається найбільш продаваним алкогольним продуктом у магазинах, але алкогольні напої все більше набирають обертів. Багато покупців, які шукають першокласні, зручні напої з яскравим смаком, тепер прагнуть до коктейлів у банках і готових до вживання (RTD) напоїв.
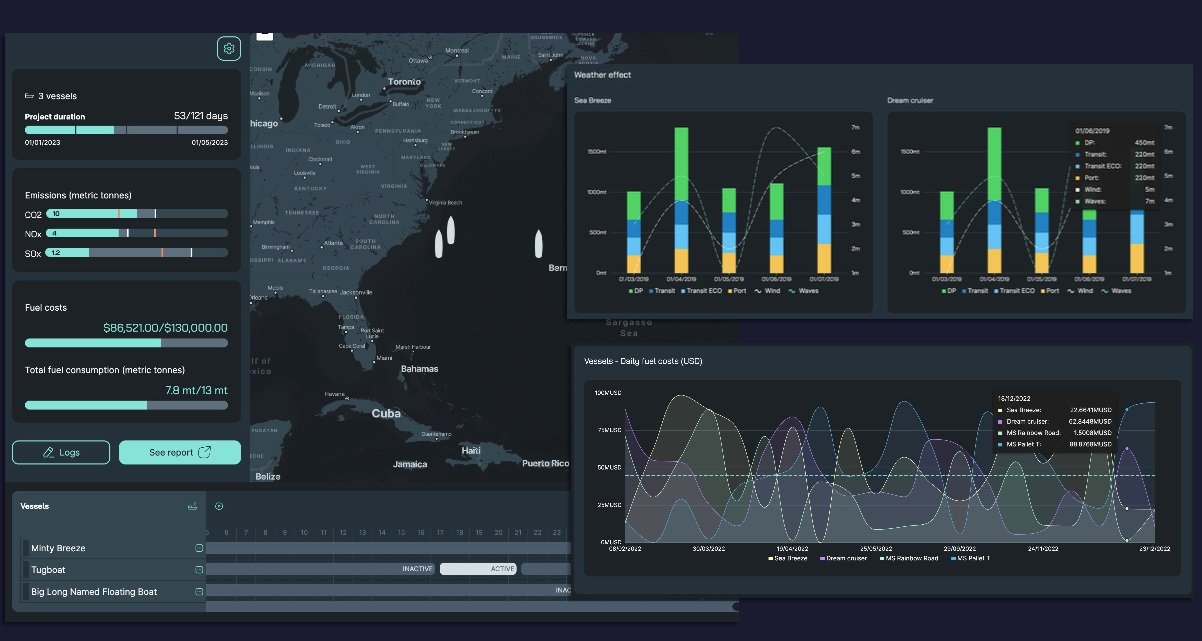
Але алкогольні напої не можна продавати в усіх магазинах чи штатах, і в цих випадках коктейлі на основі солоду та вина, які мають багато тих самих властивостей, що й аналогічні алкогольні напої, задовольняють потреби покупців і дозволяють роздрібним торговцям задовольнити попит на RTD, що робить їх однією з найшвидше зростаючих категорій алкоголю в магазинах c, згідно з даними NIQ про продажі поза приміщенням до 19 квітня, проаналізованими Дейвом Вільямсом з Бамп Вільямс Консалтинг.
Коктейлі на основі солоду та вина заповнюють прогалину алкоголю
Популярність таких брендів, як Cayman Jack, BeatBox і Clubtails, говорить про це явище. Жоден із цих брендів не базується на міцних алкогольних напоях, але вони називають себе «приготованим коктейлем преміум-класу» (Cayman Jack), «панчем для вечірок» (BeatBox) і «коктейлем у банці» (Clubtails). Згідно з аналізом даних NIQ, проведеним Вільямсом, навіть такі бренди, які народилися в сегменті алкогольних напоїв, як-от Fireball, Jack Daniel's і Pink Whitney, випустили успішні аналоги на основі солоду, які є одними з лідерів за обсягом у магазинах міні-маркетів у сфері ароматизованих солодових напоїв.
Звичайно, існують законодавчі обмеження щодо маркування та продажу продуктів, але загалом споживачі не надто стурбовані ферментативною основою. Вони хочуть смаку, зручності та привабливого бренду. Якщо він виглядає, смакує та функціонує як маргарита… чи потрібно включати текілу?
Ароматизовані солодові напої випереджають конкуренцію
Згідно з даними NIQ, ароматизовані солодові напої (FMBs) перевищують індекс у магазинах і складають приблизно 9% обсягу пива в каналі порівняно з приблизно 5,5% у продуктових магазинах і приблизно 7,5% у всіх торгових точках. У своєму аналізі Вільямс зазначив, що нові бренди, натхненні коктейлями, продовжують входити в простір FMB, включаючи лінію ClawTails від White Claw і Jumex Hard Nectar.
«Коли справа доходить до споживчого попиту та потоку доларів між алкогольними напоями, усі ознаки присутні, — сказав Кріс Стюарт, віце-президент Casey з мерчандайзингу, на Форумі напоїв у 2025 році. Ці атрибути включають знайомі смаки, зручну упаковку та відчуття від коктейлю.
Cayman Jack — це бренд, який це добре втілює. Різноманітні пакети представили нові смаки, такі як полунична маргарита, і навіть нові стилі напоїв, включаючи палому, кубинський мохіто та московський мул.
Високий попит на негайне споживання
Бренди алкогольних напоїв, які досягають успіху в магазинах, роблять це, орієнтуючись на споживача. У випадку з алкогольними напоями та коктейлями на основі вина вони знайшли благодатний простір між бажанням випити коктейлю та відсутністю інтересу до окремої поїздки до магазину алкогольних напоїв.
Дані NACS 2024 Convenience Voices свідчать про те, що приблизно 80% покупок у c-store здійснюються протягом години. Покупці тут, щоб задовольнити миттєве бажання, що відрізняється від підходу покупця в магазині алкогольних напоїв, який, наприклад, збирає запаси для вечірки на тиждень наперед. Якщо покупець хоче отримати коктейль одразу, основа, яка здатна до бродіння, менш важлива, ніж інші атрибути продукту, такі як смак, міцність і естетика бренду.
Постійний успіх коктейльних напоїв є нагадуванням індустрії періодично відкидати власні припущення та підходити до полиці, як покупець: які напої вони шукають? Для яких випадків? Який локальний основний продукт недоступний … але повинен бути? Прямо зараз коктейлі на основі солоду та вина перевіряють велику кількість коробок покупців — і через це високі ціни.
Цікаво дізнатися, як алкогольні напої проходять у магазинах? Читати “Підніміть банку до духів» у номері журналу NACS за серпень 2025 року.