Хочете розумніші відомості у своїй папці “Вхідні”? Підпишіться на наші щотижневі бюлетені, щоб отримати лише те, що має значення для підприємств AI, даних та лідерів безпеки. Підпишіться зараз
Яскраві дані, ізраїльська веб-скребна компанія, яка перемогла як META та Elon Musk у федеральному суді, оприлюднила всебічний інфраструктурний набір AI в середу, розроблений для надання штучного інтелектуального системи безперешкодного доступу до веб-даних у реальному часі-можливості, яку компанія стверджує, що великі технологічні платформи намагаються монополізувати.
Оголошення про протоколи Deep Lookup, Browser.AI та розширені протоколи збору даних є драматичним розширенням для десятиліття компанії, яка перетворилася на спеціалізовану службу скребки в те, що генеральний директор або Ленчнер називає “унікальним інфраструктурним рівнем для компаній AI”. Цей крок виникає як компанії штучного інтелекту все більше борються за доступу до поточної веб -інформації, необхідної для живлення чатів, автономних агентів та інших програм AI.
“Інтелект сьогоднішніх LLMS вже не є його обмежуючим фактором; доступ”, – сказав Ленчнер в ексклюзивному інтерв'ю з VentureBeat. “Ми витратили останнє десятиліття на боротьбу за відкритий доступ до публічних веб-даних, і ці нові пропозиції приводять нас до наступної глави нашої подорожі, одного, що характеризується справді доступними даними та подальшим зростанням контекстуально усвідомлених агентів”.
Запуск слідує за гучними юридичними перемогами Bright Data у 2024 році, коли федеральні судді відхилили позови як з META та X, стверджуючи, що компанія незаконно вискочила свої платформи. Ці рішення створили вирішальний юридичний прецедент, що визначає, що являє собою “публічні дані” в Інтернеті – інформацію, яку можна переглянути, не входячи в систему, і тому може бути юридично зібрана та використана.
Суди суду показали, що і META, і X були яскравими клієнтами даних навіть під час подання позову на компанію, підкреслюючи суперечливу позицію, яку багато технологічних гігантів взяли на себе в Інтернеті. Постанови мають більш широкі наслідки для галузі ШІ, яка значною мірою покладається на веб -дані для підготовки та експлуатації мовних моделей.
“У суді було виявлено, що вони обидва були клієнтом яскравих даних, оскільки всім потрібні дані, всі, особливо ті, хто будує моделі”, – пояснив Ленчнер. “Ми єдина компанія, яка має фінансові ресурси, і я навіть сказав би сміливість зробити це”.
Суддя Вільям Альсуп, який головував у справі X, писав, що надання компаніям соціальних медіа “безкоштовно спонукати, щоб вирішити, на будь -якій основі, які можуть збирати та використовувати дані”, створюючи “інформаційні монополії, які б підтвердили суспільний інтерес”. Постанова встановила, що дані, які можна переглянути без облікових даних, є публічною інформацією, яка може бути юридично вискоблювання.
Раніше яскраві дані подали протилежне проти X, стверджуючи, що платформа порушила антимонопольні закони, намагаючись створити монополію даних, щоб принести користь компанії AI Musk, XAI. Однак цей випадок з тих пір врегульований. “Хоча терміни конфіденційні, яскраві дані ніколи не відступали від своєї основної думки, що публічні дані повинні бути доступними для громадськості. Відповідно до цієї віри, ми раді повідомити, що яскраві дані продовжуватимуть надавати ті самі провідні послуги, що і в галузі, і що наші клієнти очікували”,-сказав Ленчнер.
Глибокий пошук та браузер.ai націлювання на компанії AI, які борються з доступом до даних
Нові продукти компанії стосуються того, що Ленчнер визначає як три основні вимоги до систем AI: алгоритми, обчислення потужності та доступ до даних. Хоча яскраві дані не розробляють алгоритми AI або не надають обчислювальні ресурси, вони мають на меті стати остаточним рішенням для третьої вимоги.
Глибокий пошук функціонує як двигун дослідження природної мови, призначений для відповіді на складні багатошарові бізнес-питання в режимі реального часу. На відміну від пошукових систем загального призначення або чатів AI, які надають підсумки, Deep Lookup спеціалізується на вичерпних результатах для запитів, починаючи з “Знайти все”. Наприклад, користувачі можуть попросити “всіх судноплавних компаній, які пройшли через Панаму та Суецькі канали в 2023 році, доходи яких у кварталі знизилися на понад 2 відсотки”.
Система виходить із масового веб -архіву Bright Data, який наразі містить понад 200 мільярдів HTML -сторінок і додає 15 мільярдів щомісяця. До наступного року очікується, що архів перевищить 500 мільярдів сторінок. “Це не просто випадкові веб -сторінки, це насправді те, про що піклується світ, тому що наші 20 000 клієнтів представляють мільярди користувачів Інтернету”, – зазначив Ленчнер.
Browser.ai представляє те, що компанія називає “першим розблокованим браузером, що розблокується в галузі”. Розроблений спеціально для автономних агентів AI, хмарна сервіс імітує поведінку людини для доступу до веб-сайтів без запуску систем виявлення бота. Він підтримує команди природних мов і може виконувати складні веб -взаємодії, такі як бронювання рейсів або створення резервування ресторанів.
Інфраструктура браузера вже переробляє понад 150 мільйонів веб -дій щодня, повідомляє компанія. “Майже всі вони є клієнтами”, – сказав Ленчнер про компанії AI агентами, які зібрали значне фінансування. “Тому що те, що ми з'ясували, і вони зрозуміли, це те, що ми вирішуємо цю проблему введення веб -сайту, не заблокуючи та виконуючи веб -дії на веб -сайті”.
Сервери MCP (протокол контексту моделі) забезпечує рівень контролю з низькою затримкою, що дозволяє агентам AI для пошуку, повзання та вилучення живих даних у режимі реального часу. Протокол дозволяє розробникам будувати системи AI, які можуть діяти на поточній інформації, а не покладатися виключно на дані про навчання.
Патентне портфоліо та проксі -мережа створюють конкурентоспроможний ров проти блокування
Конкурентна перевага Bright Data випливає з того, що Ленчнер описує як “одержимість” подолання механізмів блокування веб -сайтів. Компанія має понад 5500 патентних претензій щодо своєї технології та керує найбільшою у світі проксі -мережею з більш ніж 150 мільйонами IP -адрес у 195 країнах.
“У нас такий гарний погляд в Інтернет”, – пояснив Ленчнер. “Вже тривалий час ми картографуємо Інтернет, і вже давно ми також архівуємо великі шматки Інтернету”.
Підхід компанії передбачає складні методи імітувати поведінку людини, використовуючи реальні пристрої, IP -адреси та відбитки пальців браузера, а не прості автоматизовані сценарії. Це робить виявлення та блокування надзвичайно важкими для веб -сайтів.
“Єдиний спосіб заблокувати нас, практично, – це поставити дані за логіном, тоді ми навіть не спробуємо”, – сказав Ленчнер. “Іноді є нова логіка блокування, яку ми не вирішимо негайно. Це займе нашу дослідницьку групу 12 годин, три дні, як і найбільше, і ми розблокуємо її”.
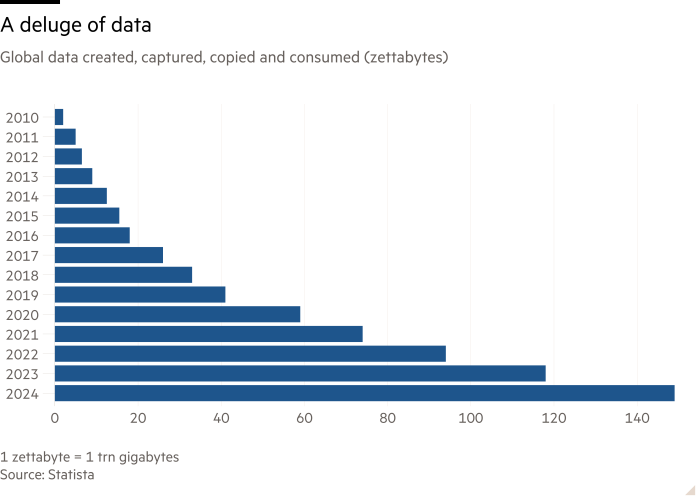
Дохід перевершує 100 мільйонів доларів, коли попит AI вибухає після Chatgpt
У той час як яскраві дані залишаються приватними фірмою приватного капіталу, Lenchner підтвердив, що щорічний дохід компанії підтвердив, що щорічний дохід компанії перевищив 100 мільйонів доларів кілька років тому. Бізнес зазнав вибухонебезпечного зростання з моменту запуску Chatgpt наприкінці 2022 року, коли компанії AI намагалися отримати доступ до даних про навчання та інформацію в режимі реального часу.
“Починаючи з березня 2023 року, що в значній мірі, коли GPT-3 змінив світ, AI, або те, що ми називаємо даними для AI, використовуйте випадок, просто абсолютно вибухнув для нас як компанії”,-сказав Ленчнер. “Все інше також зростає, тому що всім потрібно більше даних, періоду. Але цей випадок використання – це як нічого, що ми бачили раніше”.
Компанія обслуговує понад 20 000 підприємств, включаючи компанії Fortune 500 та основні лабораторії AI. Традиційні клієнти включають платформи електронної комерції, відстежуючи ціноутворення конкурентів, фірми з фінансових послуг, які шукають ринкову розвідку, та підприємства, що проводять бізнес-дослідження.
Відповідність GDPR та етичні практики відрізняються від конкурентів
Світлі дані інвестували значні кошти в інфраструктуру відповідності для вирішення проблем конфіденційності щодо збору даних. Компанія дотримується європейських правил GDPR та Каліфорнії CCPA, автоматично повідомляючи людей, коли їх особиста інформація збирається з державних джерел та надає варіанти видалення.
“Положення та законодавство зрозумілі, оскільки європейські GDPR та принаймні Каліфорнії та Правила CCPA прийшли”, – пояснив Ленчнер. “Якщо ми зібрали вашу електронну адресу, наприклад, ми автоматично надішлемо вам електронний лист із повідомленням:” Ей, це ми є. Ми зібрали вашу особисту інформацію з публічного домену. Ось величезна кнопка, ви можете натиснути, якщо ви хочете її переглянути, і ви, очевидно, можете попросити її видалити “.
Компанія підтримує велику команду з питань дотримання та широку документацію про свою практику, яка виявилася цінною під час судового розгляду. “Ми підприємства особливо любимо нас, тому що у нас є наша етична позиція, яка двічі ретельно вивчалася в судах США”, – сказав Ленчнер.
Війни веб -доступу посилюються, оскільки технічні гіганти шукають монополії даних
Доступ до веб -даних відображає більш широку напругу в галузі ШІ щодо контролю інформації та конкурентної переваги. У міру того, як системи AI стають більш складними, доступ до поточних, всебічних веб -даних стає все більш цінним – і суперечливим.
Ленчнер прогнозує, що Інтернет з часом стане “більш закритим”, подібно до того, як Google підтримує ексклюзивний доступ до своїх можливостей для повзання веб -повзання, а інші повинні використовувати альтернативні послуги. “Кілька технологічних гігантів отримають безкоштовний доступ до кожного веб -сайту зі своїми агентами”, – сказав він. “Решту потрібно буде використовувати нашу інфраструктуру чи чужу інфраструктуру”.
Компанія також спостерігає за новими тенденціями, включаючи підприємства, що вискоблюють чат -боти AI для маркетингових цілей та появу нових протоколів, таких як MCP, які дозволяють агентам AI більш ефективно взаємодіяти з веб -послугами.
“Усі ці хлопці, які вживають величезну кількість даних, і всі ми їх використовуємо, все йде на створення мозку роботів”, – сказав Ленчнер. “Нічого страшного, що у вас є чат, який розмовляє з людиною, адже це врешті -решт, що зробить робот”.
Робот мізки та економіка агентів рухають наступний фаза зростання
Трансформація Bright Data від послуги веб -скребка до постачальника інфраструктури AI відображає швидко розвиваються потреби індустрії штучного інтелекту. Коли компанії поспішають розгорнути агенти AI та автономні системи, доступ до веб-даних у режимі реального часу стає настільки ж важливим, як обчислювальна потужність та алгоритмічна складність.
Юридичні прецеденти, створені завдяки перемогам суду Bright Data, можуть виявитися такими ж важливими, як і його технічні інновації, потенційно формуючи те, як вся галузь AI отримує доступ та використовує веб -інформацію. Оскільки основні технологічні платформи все частіше обмежують доступ до даних, одночасно розробляючи власні системи AI, незалежні постачальники інфраструктури, такі як яскраві дані, можуть стати важливими для підтримки конкурентного балансу в екосистемі AI.
“Ми інфраструктурна компанія”, – наголосив Ленчнер. “Ми дуже талановиті інженери, які навряд чи їдуть куди завгодно, просто сидимо з нашими комп'ютерами і пишуть код. Ми робимо це добре. Ми не маємо наміру робити нічого іншого”.
Beta Deep -пошук запускає у вівторок для бізнес -клієнтів, з широким доступом до громадськості доступний через список очікування. Сервери Browser.AI та MCP вже доступні для клієнтів Enterprise через існуючу платформу Bright Data.
Щоденні уявлення про випадки використання бізнесу з VB щодня
Якщо ви хочете вразити свого начальника, VB Daily вас висвітлював. Ми даємо вам внутрішній совок про те, що роблять компанії з генеративним ШІ, від регуляторних змін до практичних розгортань, щоб ви могли поділитися розумінням для максимальної рентабельності інвестицій.
Прочитайте нашу політику конфіденційності
Дякуємо за підписку. Перегляньте більше інформаційних бюлетенів VB тут.
Виникла помилка.