про перехід на Data Science у 2026 році?
Якщо відповідь «так», ця стаття для вас.
Я Сабрін. Останні 10 років я працював у сфері ШІ по всій Європі — від великих компаній і стартапів до дослідницьких лабораторій. І якби сьогодні мені довелося почати заново, я б, чесно кажучи, все одно вибрав цю сферу. чому
З тих самих причин, які привели багатьох із нас сюди: інтелектуальний виклик, вплив, який ви можете мати, любов до математики та програмування та можливість вирішувати реальні проблеми.
Але дивлячись у бік 2026 року… чи варто воно того?
Якщо ви прокрутите сторінку LinkedIn, ви побачите дві команди, які борються: одна каже, що «Наука про дані мертва», а інша каже, що вона зростає завдяки тенденції ШІ.
Коли я дивлюся навколо себе, я особисто думаю, що нам завжди будуть потрібні обчислювальні навички. Нам завжди будуть потрібні люди, які зможуть зрозуміти дані та допомогти прийняти рішення. Числа завжди були всюди, і чому вони зникнуть у 2026 році?
Однак ринок змінився. І щоб орієнтуватися в цьому зараз, вам потрібні хороші вказівки та чітка інформація.
У цій статті я поділюся власним досвідом роботи в дослідницькій та промисловій сферах, а також наставництва понад 200 спеціалістів із обробки даних за останні кілька років.
Отже, що зараз відбувається на ринку?
Я буду чесним і не продам тобі жодної мрії про це.
Мета полягає не в упередженості, а в тому, щоб дати вам достатньо інформації, щоб прийняти власне рішення.
Чи є професійна сім’я Data Science більш широкою, ніж будь-коли?

Однією з найбільших помилок молодших спеціалістів з обробки даних є те, що вони вважають, що Data Science — це одна робота.
У 2026 році Data Science — це велика сім’я ролей. Перш ніж написати один рядок коду, вам потрібно зрозуміти, де ви підходите.
Людей захоплює ШІ: як ChatGPT розмовляє, як Neuralink стимулює мозок і як алгоритми впливають на здоров’я та безпеку. Але давайте будемо чесними: не всі початківці спеціалісти з обробки даних будуть створювати такі проекти.
Для цих ролей потрібна сильна прикладна математика та розширені навички програмування. Чи означає це, що ви ніколи не досягнете їх? Ні. Але вони часто призначені для людей із докторським рівнем, науковців із обчислювальної техніки та інженерів, які навчаються саме для цих нішевих робіт.
Давайте візьмемо реальний приклад: сьогодні (27 листопада) я побачив пропозицію про роботу спеціаліста з машинного навчання та обробки даних у компанії GAFAM.

Якщо подивитися на опис, вони просять:
- Патенти
- Першоавторські публікації
- Дослідницькі внески
Чи всі, хто цікавиться Data Science, мають патент чи публікацію? Звичайно ні.
Ось чому ви повинні уникати руху наосліп.
Якщо ви щойно закінчили навчальний курс або на початку навчання, подача заявки на вакансію, яка явно потребує публікації наукових досліджень, принесе лише розчарування. Ці дуже спеціалізовані вакансії зазвичай призначені для людей із високим академічним досвідом (доктор філософії, постдокторація або обчислювальна інженерія).
Моя порада: будьте стратегічними. Зосередьтеся на ролях, які відповідають вашим навичкам.
Не витрачайте час на подачу заявок скрізь.
Використовуйте свою енергію для створення портфоліо, яке відповідає вашим цілям.
Ви повинні розуміти різні підполя в Data Science і вибрати те, що відповідає вашому досвіду. Наприклад:
- Аналітик даних про продукт / науковець: життєвий цикл продукту та потреби користувачів
- Інженер машинного навчання: розгортання моделей
- Інженер GenAI: працює на LLM
- Classic Data Scientist: умовивід і передбачення
Якщо ви подивитеся на роль спеціаліста з обробки даних у Meta, то технічний рівень часто більш адаптований до більшості спеціалістів із обробки даних на ринку порівняно з роллю основного інженера-дослідника штучного інтелекту або старшого спеціаліста з обробки даних.
Ці ролі більш реалістичні для тих, хто не має докторського ступеня.


Навіть якщо ви не хочете працювати в GAFAM, майте на увазі:
Вони задають напрямок. Те, що їм потрібно сьогодні, завтра стане нормою скрізь.
А як щодо програмування та математики у 2026 році?
Ось суперечлива, але чесна правда про 2026 рік: Аналітичні та математичні навички важливіші, ніж просто кодування.
чому Зараз майже кожна компанія використовує інструменти ШІ для написання коду. Але штучний інтелект не може замінити вашу здатність:
- розуміти тенденції
- поясніть, звідки походить значення
- розробити правильний експеримент
- інтерпретувати модель у реальному контексті
Кодування все ще важливо, але ви не можете бути «загальним імпортером» — тим, хто лише імпортує sklearn і запускає .fit() і .predict().
Дуже скоро агент штучного інтелекту може зробити це за нас.
Але ваші математичні та аналітичні здібності все ще важливі, і завжди будуть.
Простий приклад:
Ви можете запитати ШІ: «Поясніть PCA так, ніби мені 2 роки».
Але ваша справжня цінність як Data Scientist виникає, коли ви запитуєте щось на зразок:
“Мені потрібно оптимізувати виробництво води моєю компанією в певному регіоні. Цей регіон стикається з проблемами, через які мережа стає недоступною за певними шаблонами. У мене є сотні функцій щодо цього стану мережі. Як я можу використовувати PCA і бути впевненим, що найважливіші змінні представлені на ПК, який я використовую?”
-> Цей людський контекст є вашою цінністю.
-> AI пише код.
-> Ви вносите логіку.
А як щодо панелі інструментів Data Science?
Почнемо з Python. Як мова програмування з великою спільнотою даних, Python все ще є важливою та, ймовірно, першою мовою, яку потрібно вивчати майбутнім спеціалістам із обробки даних.
Те саме для Scikit-learn, класичної бібліотеки для завдань машинного навчання.
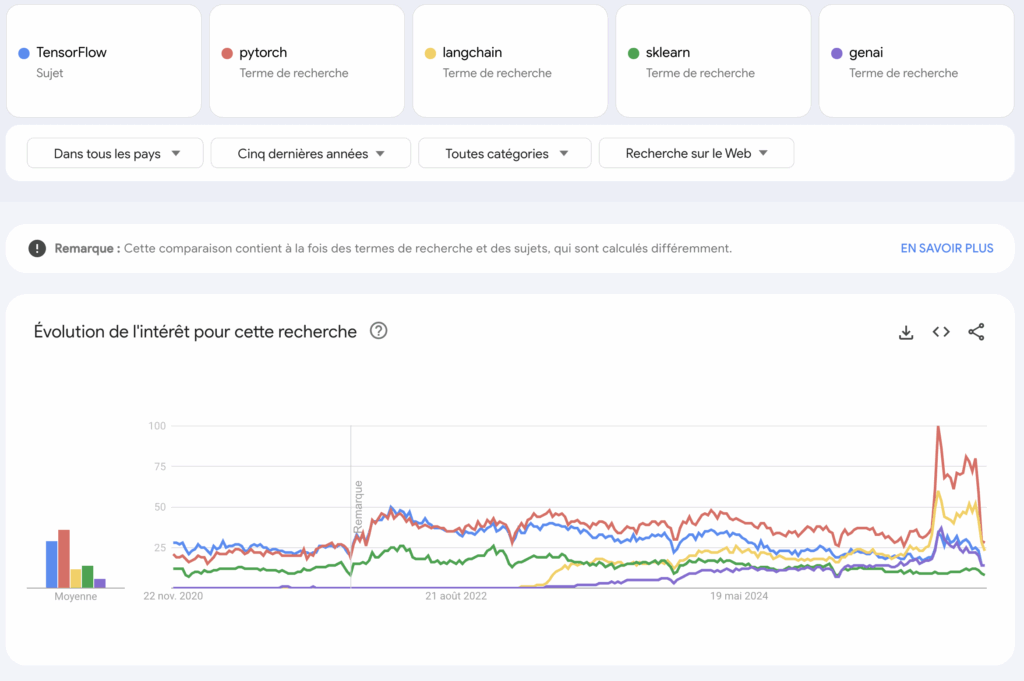
Ми також можемо побачити в Google Trends (кінець 2025 року), що:
- PyTorch зараз більш популярний, ніж TensorFlow
- Інтеграція GenAI розвивається набагато швидше, ніж класичні бібліотеки
- Інтерес аналітика даних залишається стабільним
- Ролі інженера з обробки даних і спеціаліста зі штучного інтелекту зацікавили більше людей, ніж звичайні ролі спеціаліста з обробки даних
Не ігноруйте ці моделі; вони дуже допомагають приймати рішення.
Ви повинні залишатися гнучкими.
Якщо ринку потрібні PyTorch і GenAI, не залишайтеся лише на Keras і старому NLP.
А як щодо нового стека на 2026 рік?
У цьому дорожня карта на 2026 рік відрізняється від 2020 року.
Щоб отримати роботу сьогодні, вам потрібно бути готовий до виробництва.
Контроль версій (Git): Ви будете використовувати його щодня. І, чесно кажучи, це одна з перших навичок, яку потрібно освоїти на початку. Це допоможе вам організувати ваші проекти та все, що ви дізнаєтесь.
Незалежно від того, чи розпочинаєте ви магістерську програму чи навчальний табір, не забудьте створити свій перший репозиторій GitHub і вивчіть кілька основних команд, перш ніж йти далі.
AutoML: Зрозумійте, як це працює та коли його використовувати. Деякі компанії використовують інструменти AutoML, особливо для спеціалістів із обробки даних, які більше орієнтовані на продукт.
Інструмент, який я маю на увазі, і до якого ви можете отримати безкоштовний доступ, є Dataik. У них чудова академія з безкоштовними сертифікатами. Це один із інструментів AutoML, який вибухнув на ринку за останні два роки.
Якщо ви не знаєте, що таке AutoML: це інструмент, який дозволяє створювати моделі ML без кодування. Так, воно існує.
Пам’ятаєте, що я раніше говорив про кодування? Це одна з причин, чому інші навички стають більш важливими, особливо якщо ви орієнтований на продукт Data Scientist.
MLOps: Блокнотів уже не вистачає. Це стосується кожного. Ноутбуки гарні для дослідження, але якщо в якийсь момент вам знадобиться розгорнути свою модель у виробництві, ви повинні вивчити інші інструменти.
І навіть якщо вам не подобається інженерія даних, вам все одно потрібно розуміти ці інструменти, щоб ви могли спілкуватися з інженерами даних і працювати разом.
Коли я говорю про це, я думаю про такі інструменти, як Докер (перегляньте мою статтю), MLflow (посилання тут), і FastAPI.
LLMs і RAG: Вам не потрібно бути експертом, але ви повинні знати основи: як працює LangChain API, як навчити невелику мовну модель, що означає RAG і як це реалізувати. Це справді допоможе вам виділитися на ринку та, можливо, просунутися далі, якщо вам знадобиться створити проект із залученням агента ШІ.
Портфоліо: якість над кількістю
Як ви можете довести, що можете виконати роботу на цьому швидкому та конкурентному ринку? Я пам’ятаю, що я написав статтю про те, як створити портфоліо 2 роки тому, і те, що я збираюся тут сказати, може виглядати дещо суперечливим, але дозвольте мені пояснити. До того, як ChatGPT та інструменти штучного інтелекту заполонили ринок, було дуже важливо мати портфоліо з купою проектів, щоб продемонструвати свої різні навички, як-от очищення та обробка даних, але сьогодні всі ці основні кроки часто виконуються за допомогою інструментів штучного інтелекту, які готові до цього, тому ми зосередимося більше на створенні чогось, що вирізнить вас і змусить рекрутера захотіти з вами познайомитися.
Я б сказав: “Уникайте виснаження. Будуйте розумно”.
Не думайте, що вам потрібно 10 проектів. Якщо ти студент чи молодший, достатньо одного-двох хороших проектів.
Скористайтеся часом, який ви маєте під час стажування або останнього проекту початкового кемпу, щоб створити його. Будь ласка, не використовуйте прості набори даних Kaggle. Подивіться в Інтернеті: ви можете знайти величезну кількість реальних даних про випадки використання або дослідницькі набори даних, які частіше використовуються в промисловості та лабораторіях для створення нових архітектур.
Якщо ваша мета не заглиблюватися в технічну сторону, ви все одно можете продемонструвати інші навички у своєму портфоліо: слайди, статті, пояснення того, як ви думали про цінність бізнесу, які результати ви отримали та як ці результати можна використовувати в реальності. Ваше портфоліо залежить від роботи, яку ви хочете.
- Якщо ваша мета більше орієнтована на математику, рекрутер, ймовірно, захоче побачити ваш огляд літератури та те, як ви реалізували останню архітектуру своїх даних.
- Якщо ви більше орієнтовані на продукт, мене більше зацікавлять ваші слайди та те, як ви інтерпретуєте результати ML, ніж якість вашого коду.
- Якщо ви більше орієнтовані на MLOps, рекрутер подивиться, як ви розгортали, контролювали та відстежували свою модель у виробництві.
На завершення я хочу нагадати вам, що ринок швидко змінюється, але це ще не кінець Data Science. Це просто означає, що вам потрібно більше знати, де ви підходить, які навички ви хочете розвивати, і як ви себе представляєте.
Продовжуйте вчитися та створіть портфоліо, яке справді відображає вашу особу. Ви знайдете своє місце ❤️
Якщо вам сподобалася ця стаття, не соромтеся стежити за мною в LinkedIn, щоб дізнатися більше про штучний інтелект, науку про дані та кар’єру.
👉 LinkedIn: Сабрін Бендімерад
👉 Середній: https://medium.com/@sabrine.bendimerad1