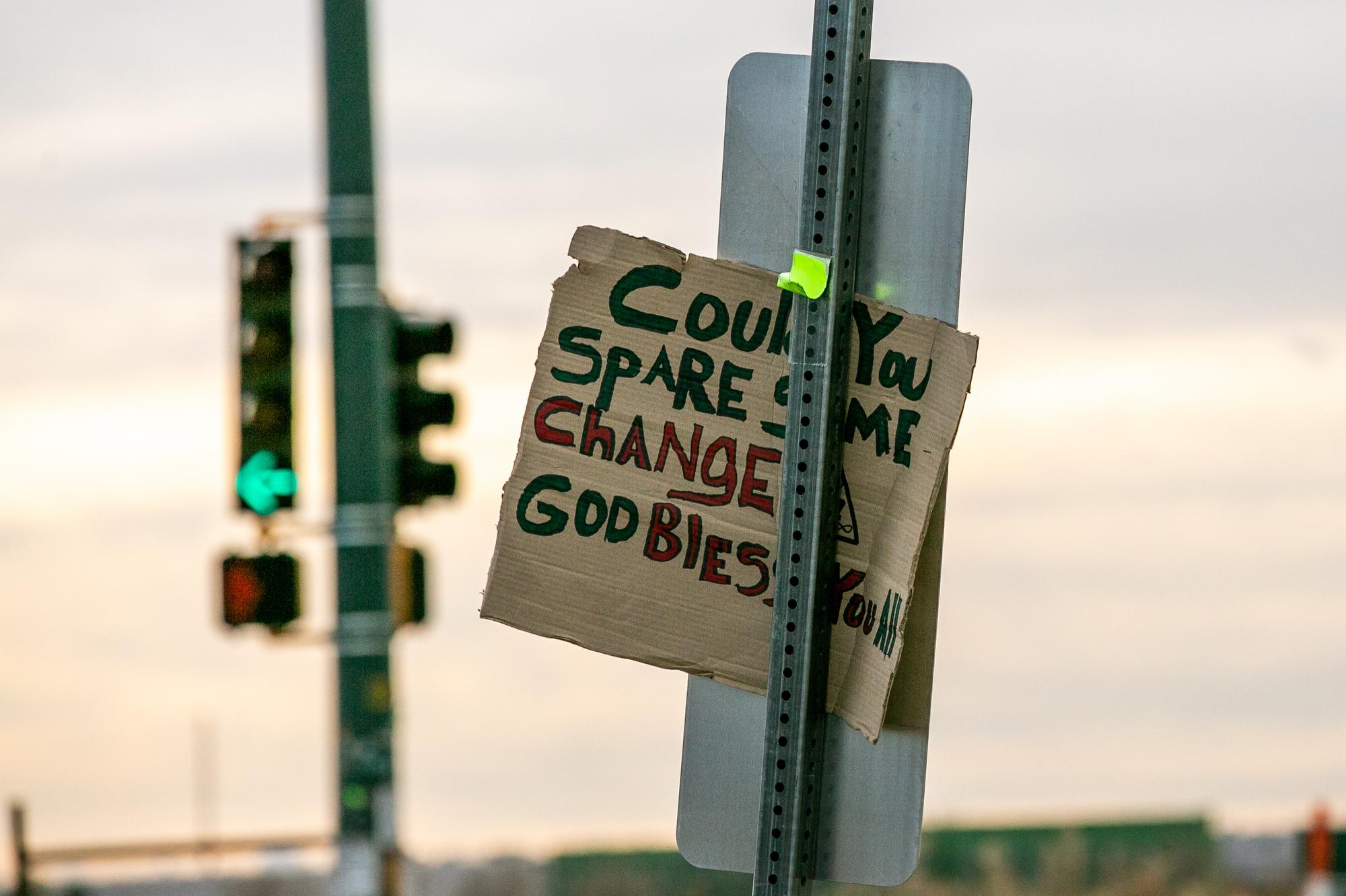Veeam Software підписала остаточну угоду про придбання Securiti AI, постачальника систем управління безпекою даних (DSPM), за 1,725 мільярда доларів США.
Veeam і Securiti AI об’єднують стійкість даних із DSPM, конфіденційністю, управлінням і довірою AI, що охоплює виробництво та вторинні дані. Разом вони допоможуть клієнтам зрозуміти всю їхню базу даних, водночас забезпечуючи безпеку, а також відновлення та відкат, щоб розкрити цінність їхніх даних для ШІ.
Завдяки придбанню Securiti AI Veeam усуває проблему керування фрагментованими даними в програмах, хмарах, SaaS, кінцевих точках і резервних копіях. ІТ-директори, CISO та CDO матимуть уніфікований командний центр для повного контролю та розуміння всіх їхніх даних, а також для їх захисту з майже нульовою втратою даних або простою бізнесу, точного відновлення та відкоту даних та штучного інтелекту та безпечного впровадження інновацій ШІ.
Ця єдина площина керування виробничими та вторинними даними дозволяє підприємствам однаково керувати всіма своїми даними, поєднуючи можливості стійкості даних Veeam із DSPM Securiti AI, конфіденційністю даних і можливостями довіри AI.
Організації не змогли використати цінність неструктурованих даних, включаючи електронні листи, документи та взаємодію з клієнтами, які становлять 70-90% усіх корпоративних даних.
Тим часом кібератаки посилюються, правила посилюються, а ініціативи зі штучним інтелектом зупиняються, оскільки не можна довіряти даним, які їх подають. Згідно з галузевими дослідженнями, 80-90% проектів штучного інтелекту зазнають невдачі, багато через проблеми з даними, включаючи точність, походження, дозволи та ідентифікацію, а також проблеми з конфіденційністю.
Традиційні підходи, які включають окремі інструменти для захисту даних і керування ними, не відображають нових загроз ШІ та змушують команди постійно шукати компроміси між безпекою, управлінням ризиками та гнучкістю бізнесу.
Поєднання Veeam і Securiti AI значно пом’якшує ці компроміси завдяки єдиному командному центру для всіх даних.
“Ми вступили в нову еру даних. Це вже не просто захист даних від кіберзагроз і непередбачуваних катастроф; це також ідентифікація всіх ваших даних, забезпечення їхнього управління та довіри для прозорої роботи штучного інтелекту”, – сказав Ананд Есваран, генеральний директор Veeam. «Це єдиний найважливіший фактор невдалих ініціатив ШІ».
Рехан Джаліл, генеральний директор Securiti AI, сказав, що корпоративний штучний інтелект просто неможливий без безпеки даних.
«Securiti AI вирішує цю проблему та забезпечує безпечне використання даних і штучного інтелекту», — сказав Джаліл. «Глобальне охоплення та інновації Veeam у поєднанні з нашими технологіями та інтелектом забезпечать клієнтам неперевершену бізнес-стійкість і безпеку, щоб повністю розкрити переваги ШІ».
Очікується, що угода буде закрита в четвертому кварталі, і вона підлягає звичайним умовам закриття та дозволам регуляторних органів. Veeam продовжить пропонувати Data Command Center від Securiti AI поряд із наявною сім’єю продуктів і незабаром оголосить про нові інтегровані можливості.
Інфрачервона спектроскопія з перетворенням Фур’є (FT-IR), особливо у формі ослабленого повного відбиття (ATR), стала незамінною в хімічному аналізі судової медицини, біомедичних та харчових наук через її швидкість, мінімальну підготовку зразків і неруйнівний відбір проб. Однак спектри, які він виробляє, часто переповнені шумом, зсувами базової лінії та ефектами розсіювання, які приховують важливу хімічну інформацію. Як наголошують у своєму огляді Лоонг Чуен Лі, Чонг-Єун Ліонг і Абдул Азіз Джемейн з Університету Кебангсан Малайзії (1), нехтування належною попередньою обробкою даних може підірвати навіть найскладніші хемометричні моделі. Ця стаття міні-підручника підсумовує їхні висновки та розкриває практичні стратегії попередньої обробки, які покращують спектральну якість і аналітичні результати.
Основний зміст навчального посібника
Принципи: Чому попередня обробка даних важлива
У дослідженні 2017 року Лі, Ліонга та Джемейна (1) висвітлюється попередня обробка даних (DP) як критично важливий, але часто недооцінений перший крок у хемометричному робочому процесі. Спектри FT-IR ATR — це масиви даних великої розмірності, що містять як інформативні, так і неінформативні сигнали. Без належного DP алгоритми моделювання, такі як аналіз головних компонентів (PCA) або часткові найменші квадрати (PLS), можуть неправильно інтерпретувати нерелевантні варіації, такі як дрейфи базової лінії або розсіювання, як хімічну інформацію.
Належна попередня обробка мінімізує систематичний шум і мінливість, спричинену зразком, що дозволяє виділяти справжні молекулярні характеристики. Як підтверджено нещодавніми дослідженнями FT-IR щодо автентифікації меду (2) та біомедичного аналізу (3), попередня обробка гарантує, що спектральні дані відображають справжні відмінності в складі, а не артефакти від представлення зразка або дрейфу інструменту.
Як це працює на практиці
У спектроскопії FT-IR ATR інфрачервоне світло взаємодіє з поверхнею зразка через повне внутрішнє відбиття, створюючи спектр, характерний для його молекулярного складу. Однак, як зазначають Лі та його колеги (1), кілька факторів, таких як гетерогенність зразка, розмір частинок, шорсткість поверхні та стабільність приладу, можуть спотворювати сигнали абсорбції.
Варіація інтенсивності (спричинене різним представленням вибірки або довжиною шляху)
Спектральне перекриття (між аналітом і фоновими компонентами, особливо в складних сумішах).
Щоб пом’якшити ці проблеми, спектроскопісти використовують комбінацію етапів попередньої обробки:
Нормалізація налаштовує всі спектри на загальну шкалу інтенсивності, компенсуючи відмінності в кількості зразків (довжина шляху). Загальні підходи включають ділення на найінтенсивніший пік або загальну площу поглинання.
Корекція розсіювання (SC) методи, такі як стандартна нормальна варіація (SNV) і корекція мультиплікативного розсіювання (MSC), коректне мультиплікативне масштабування та фонові ефекти через варіації розміру частинок або розсіювання світла.
Центрування та масштабування стандартизувати середнє значення та дисперсію кожної змінної (хвильового числа). Середнє центрування (MC) зміщує середнє поглинання до нуля, сприяючи більш чіткій інтерпретації PCA; автомасштабування коригує як середнє, так і дисперсію, гарантуючи, що змінні однаково впливають на модель.
Корекція базової лінії (BC) усуває фонові дрейфи, спричинені ефектами відбиття та заломлення, властивими оптиці ATR. Часто використовуються алгоритми поліноміальної підгонки або «гумової стрічки».
Похідні інструменти (Drv)особливо першого та другого порядку, додатково усувають базові ефекти та підвищують спектральну роздільну здатність шляхом поділу піків, що перекриваються.
При систематичному застосуванні ці перетворення перетворюють необроблені спектри ATR у стабільні набори даних, які можна інтерпретувати, придатні для багатовимірного аналізу.
Приклади застосування та методу
Лі та його співробітники (1) ілюструють ці ефекти попередньої обробки за допомогою судово-медичного аналізу чорнила, де спектри FT-IR ATR чорнила на паперових підкладках оцінюються для виявлення підробки. Неруйнівний характер техніки зберігає цілісність доказів, але спектральні перешкоди від паперу ускладнюють інтерпретацію. Нормалізація та корекція базової лінії значно покращують дискримінаційну силу між зразками чорнила, виявляючи тонкі варіації композиції, інакше приховані фоновим шумом.
Подібним чином Tsagkaris і його співробітники (2) продемонстрували, як попередня обробка впливає на класифікацію меду за ботанічним походженням, використовуючи спектри FT-IR. Їхнє дослідження порівняло кілька комбінацій попередньої обробки та виявило, що конкретні конвеєри, такі як SNV з наступним перетворенням другої похідної, оптимізували точність моделі.
У біомедичних застосуваннях Magalhães і його співробітники (3) підкреслили, що попередня обробка є необхідною для вирішення перекриваються біохімічних сигналів у складних тканинах або біорідинах. Вони зазначили, що непослідовна попередня обробка в дослідженнях часто призводить до невідтворюваності та неправильної інтерпретації діагностичних моделей.
Ці приклади пояснюють універсальність проблем DP у різних додатках і галузях, від судової експертизи до харчових і біомедичних наук, а також необхідність емпіричного пристосування стратегій попередньої обробки до конкретних характеристик даних.
Поради та поширені підводні камені
Лі та його колеги (1) виявили кілька прогалин у знаннях і поширених помилок у практиці попередньої обробки FT-IR ATR:
Надмірна залежність від умов за замовчуванням: Багато користувачів використовують стандартні методи попередньої обробки (наприклад, автомасштабування, SNV), не перевіряючи їх придатність для певного набору даних.
Повністю нехтуючи попередньою обробкою: Деякі якісні дослідження пропускають DP через хибне припущення, що візуальної спектральної інтерпретації достатньо, що призводить до ненадійних висновків.
Відсутність інструментів оцінки: Існує кілька стандартизованих показників для оцінки ефективності попередньої обробки. Часто використовується візуальний огляд або кластеризація PCA, але обидва вони суб’єктивні.
Ігнорування розмірності даних: Спектральні дані великої розмірності вимагають попередньої обробки, яка врівноважує збереження сигналу зі зменшенням шуму, зазначаючи, що надмірне згладжування або застосування похідних обробок (диференціювання) може приховати відповідні функції.
Щоб уникнути цих пасток, користувачі повинні:
Порівняйте кілька конвеєрів попередньої обробки, використовуючи показники продуктивності моделі (наприклад, RMSE, точність).
Зберігайте необроблені дані для відстеження.
Застосуйте знання предметної області, такі як відомі смуги поглинання та знання інтерпретаційної спектроскопії, щоб переконатися, що попередня обробка не спотворила хімічно значущі області.
Документуйте кожен етап попередньої обробки для відтворюваності та узгодженості робочого процесу.
Висновки та практичні висновки
Попередня обробка даних є сполучною ланкою між отриманням необроблених спектрів і значущим хемометричним моделюванням. Огляд Лі, Ліонга та Джемейна (1) служить важливим нагадуванням про те, що попередня обробка не є ні необов’язковою, ні тривіальною. У спектроскопії FT-IR ATR, де тонкі нахили базової лінії або ефекти розсіювання можуть ввести в оману моделі класифікації, ретельно підібрана попередня обробка перетворює необроблені дані в характеристики, які можна хімічно інтерпретувати.
Найкраща практика передбачає тестування комбінацій нормалізації, корекції розсіювання та базових або похідних методів, оцінюючи кожен з них на точність і відтворюваність. Нові програми, від автентифікації меду (2) до біомедичної діагностики (3), демонструють, що правильна стратегія попередньої обробки може значно підвищити спектральну дискримінацію та надійність моделі.
Майбутня робота має бути зосереджена на розробці стандартизованих показників оцінювання та автоматизованих інструментів для керування оптимальним вибором DP. Як роблять висновок автори, цій галузі все ще бракує єдиної «стратегії практики ДП». Усунення цієї прогалини забезпечить повну реалізацію потенціалу спектроскопії FT-IR ATR як надійного, високопродуктивного аналітичного інструменту в різних дисциплінах.
Список літератури
(1) Лі, Л.С.; Ліонг, CY; Джемейн, А.А. Сучасний огляд практичної стратегії попередньої обробки даних (DP) у спектрі FT-IR ATR. Chemom. Intell. Лабораторія. сист.2017 рік, 16364–75. DOI: 10.1016/j.chemolab.2017.02.008.
(2) Цагкаріс, А.С.; Бечинська, К.; Нтакулас, Д.Д.; Пасіас, IN; Веллер, П.; Proestos, C.; Hajslova, J. Дослідження впливу попередньої обробки спектральних даних для оцінки ботанічного походження меду за допомогою інфрачервоної спектроскопії з перетворенням Фур’є (FT-IR). J. Food Compos. анальний2023 рік, 119105276. DOI: 10.1016/j.jfca.2023.105276.
(3) Magalhães, S.; Гудфеллоу, BJ; Nunes, A. FT-IR спектроскопія в біомедичних дослідженнях: як максимально використати її потенціал. апл. Spectrosc. Рев.2021 рік, 56 (8–10), 869–907. DOI: 10.1080/05704928.2021.1946822.
Цей простір запропонує новий спосіб досліджувати економічні, соціальні та геополітичні явища за допомогою щоденних даних, інтерактивних візуалізацій та інструментів на основі ШІ. Розділ пропонує безпрецедентний спосіб стежити за економічними подіями в режимі реального часу, а також за економічними, соціальними та геополітичними проблемами через події, про які щодня повідомляють ЗМІ, представлені за допомогою інтерактивних візуалізацій та інструментів на основі ШІ.
Новий розділ структуровано навколо трьох основних областей вмісту: економіка в режимі реального часу, економіка високої чіткості та геополітичний аналіз за допомогою ШІ.
Економіка в реальному часі: надає високочастотні індикатори, які дозволяють щоденно відстежувати ключові змінні, такі як споживання, інвестиції та галузева діяльність, використовуючи анонімні дані взаємодії з клієнтами BBVA або користувачами методів оплати.
Економіка високої чіткості: надає інформацію, розподілену за регіонами, провінціями та містами, що дозволяє детально відслідковувати місцеві економічні показники, використовуючи ті самі дані.
Геополітичний аналіз з AI: використовує обробку природної мови та методи ШІ для оцінки невизначеності, геополітичного ризику та міжнародної напруженості на основі тисяч щоденних новин, серед іншого вмісту та тем.
Прихильність до інновацій та поширення економічного розуміння
З цією ініціативою, Дослідження BBVA прагне надати суспільству більш доступну, динамічну та актуальну інформацію, зміцнюючи при цьому своє лідерство у використанні великих даних та штучного інтелекту в економіці.
«У BBVA Research ми прагнемо інновацій, застосованих до економічного аналізу. Цей новий розділ «Великі дані» є ще одним кроком вперед у нашій меті — надати дані більшій кількості людей у більш наочний та корисний спосіб, щоб сприяти кращому розумінню економічної та соціальної реальності». Хорхе Сісіліа, керівник відділу досліджень BBVA та головний економіст групи BBVA.
Новий інструмент відкриває двері до нової парадигми аналізу, яка дозволить дослідникам, установам і ЗМІ відстежувати економічні та соціальні зміни в реальному часі.
Доступний на http://bigdata.bbvaresearch.com, цей розділ доповнює традиційні звіти та публікації BBVA Research, пропонуючи інтуїтивно зрозумілий досвід перегляду з завантажуваними графіками та міжнародними порівняннями в різних сферах: споживання, інвестиції, зовнішня торгівля та порівняння між різними географічними регіонами, надаючи глобальну перспективу.
Публічні дані, від опитувань перепису населення до адміністративних записів, є важливими для вирішення основних суспільних проблем, таких як продовольча безпека, зміна клімату та економічний розвиток. Для Африки, де проживає наймолодше та найшвидше зростаюче населення у світі, ці дані є двигуном майбутнього, керованого ШІ.
Подібно до того, як континент перейшов від стаціонарних телефонів до мобільних технологій, африканські країни готові запровадити нові, готові до ШІ підходи до інфраструктури публічних даних. Щоб допомогти реалізувати цей потенціал, Google виділяє 2,25 мільйона доларів на модернізацію загальнодоступних систем даних Африки, щоб зробити їх доступними, надійними та готовими до епохи ШІ.
Це фінансування буде використано Data Commons, наше відкрите сховище знань, яке перетворює та організовує різноманітні загальнодоступні дані світу в єдиний надійний ресурс. Зокрема, це означає співпрацю з організаціями для відображення різнорідних наборів даних у графі знань Data Commons, створення єдиного ресурсу, який можна запитувати та аналізувати за допомогою нових інструментів штучного інтелекту, які розроблятимуть проекти.
Створення регіонального Data Commons для Африки
Google.org надає 750 000 доларів США Економічній комісії ООН для Африки (UNECA) для запуску регіонального Data Commons для Африки. Цей проект створюватиме платформи з підтримкою штучного інтелекту для інтеграції наборів даних з усього континенту, зосереджуючись на таких критичних сферах, як продовольча безпека, торгівля та економічний розвиток.
Окрім платформи, ми маємо намір сприяти встановленню регіональних стандартів етичного обміну даними та зміцнювати технічні навички національних статистичних служб (NSO). Початковим результатом цих зусиль стане створення єдиної основи даних, готової до штучного інтелекту, яка зрештою дасть можливість політикам приймати кращі рішення на основі даних і прискорить позитивні результати для суспільства на всьому континенті.
Передача даних до централізованих об’єктів більше не працює в галузях, де є великі обсяги безперервних потокових даних. Тут може допомогти адаптивний граничний інтелект.
У галузях, які дедалі частіше приймаються рішення в реальному часі, наприклад у виробництві, транспорті, телекомунікаціях, громадській безпеці тощо, дані більше не створюються випадковими пакетами. Він надходить постійно та у великих масштабах від датчиків, машин, мобільних ресурсів і цифрових програм. Хоча централізація цих даних у хмарі чи центрі обробки даних для аналізу колись здавалася ефективною, обсяг, швидкість і критичність сучасних потоків даних виявили серйозні обмеження традиційного підходу транзитного зв’язку.
Протягом багатьох років організації, які регулярно мають справу з такими потоками даних і хочуть використовувати дані для аналізу в реальному часі, переносять аналіз цих даних на край, де вони створюються. У міру того, як обсяги даних і темпи генерування даних зростають, багато організацій все частіше надають своїм периферійним системам розширений інтелект, щоб адаптовано реагувати на дані, отримані в результаті аналізу в реальному чи майже в реальному часі.
Дивіться також: Поза межами затримки: наступний етап адаптивного граничного інтелекту
Обмеження передачі даних
Передача даних до централізованих установ мала практичне застосування протягом десятиліть, коли обсяги даних і швидкість їх генерування були скромними. Дані зберігатимуться та аналізуватимуться для негайних дій або для розуміння історичних тенденцій.
Ця модель більше не працює в галузях, де є великі обсяги безперервних потокових даних. Деякі галузі, які постраждали, включають:
Організації фінансових послуг намагаються працювати з нескінченними потоками транзакційних даних.
Компанії-виробники намагаються зрозуміти IoT та інші дані датчиків з обладнання на виробничих лініях.
Інтернет-магазини намагаються скористатися моментом і представити клієнтам відповідні товари на своєму сайті.
Автономні транспортні засоби намагаються інтерпретувати відеопотоки, щоб уникнути перешкод на дорозі та дотримуватися правил дорожнього руху.
У цих та інших випадках однією з найбільш нагальних проблем із транспортуванням даних є перевантаження мережі. Джерела високочастотних даних, такі як датчики IoT, канали HD-відео, автономні системи або промислове обладнання, можуть створювати гігабайти або навіть терабайти даних на годину. Спроба спрямувати це в центральне місце напружує доступну пропускну здатність, збільшуючи витрати та знижуючи загальну продуктивність мережі. Оновлення пропускної здатності допомагає, але погано масштабується, що призводить до вищих витрат.
Тоді є затримкаякий є тихим вбивцею швидкості реагування в режимі реального часу. Коли необроблені дані повинні пройти великі відстані для обробки, затримка в обігу може зробити аналітичну інформацію застарілою до того часу, коли аналітичні системи оброблятимуть її. У сценаріях, важливих для безпеки або чутливих до часу, таких як виявлення несправностей у комунальних послугах, контроль якості на виробничих лініях або прогнозне обслуговування транспортних парків, мілісекунди мають значення. Централізована архітектура обробки просто не може гарантувати детерміновану продуктивність.
Ще одне питання, яке часто забувають неефективність витрат. Хмарне зберігання, плата за передачу даних і обчислювальні ресурси стають дорогими, коли великі набори даних постійно переміщуються. Багато організацій вважають, що вони платять за зберігання та аналіз даних, які є зайвими, малоцінними або нерелевантними. Насправді регулярні дослідження показують, що більшість необроблених даних датчиків ніколи не використовуються, але вони все одно спричиняють повні витрати на транспортування та зберігання під час зворотного зв’язку.
Ризики безпеки та конфіденційності також зростають із збільшенням обсягу даних. Переміщення невідфільтрованих даних через глобальні мережі розширює поверхню атаки та вимагає суворого шифрування, моніторингу та контролю відповідності. Конфіденційні дані, як-от інформація про місцезнаходження, операційна телеметрія або моделі використання клієнтами, можуть мати нормативні наслідки під час передачі через регіони чи межі хмари. Для деяких галузей промисловості лише це робить централізований зворотний зв’язок непрактичним.
Нарешті, централізовані архітектури обмежують стійкість. Якщо з’єднання втрачається або продуктивність знижується, системи, які залежать від хмари для аналітики, можуть не приймати своєчасних рішень. Це неприйнятно в периферійних середовищах, таких як віддалені операції з видобутку корисних копалин, морські енергетичні платформи, розумні мережі або транспортні системи, які не можуть призупинити роботу, доки мережа не відновиться.
Ближчий погляд на проблеми транспортування даних
Коротше кажучи, у міру поширення систем реального часу аналітика та прийняття рішень повинні бути ближче до джерела події, підтримувати стан, виконуватися з мінімальною затримкою та повною узгодженістю.
Недавній дослідник розглянув проблеми з транспортуванням даних у перспективі та обговорив, як адаптивні периферійні інтелектуальні системи їх усувають.
У блозі зазначено, що хоча централізована обробка даних пропонує певну зручність управління, вона несе значні приховані витрати. До них відносяться витрати на високу пропускну здатність і зберігання, пов’язані з транспортуванням і розміщенням великих наборів даних, збільшення споживання енергії та пов’язаний з цим вуглецевий слід, проблеми з затримкою та надійністю мережі (особливо для додатків у режимі реального часу), а також більший ризик поодиноких збоїв, коли вся обробка залежить від централізованої інфраструктури.
Щоб подолати ці проблеми, організації зміщують інтелектуальні можливості: обробляють і фільтрують дані ближче до їх джерела, щоб наверх надсилалася лише значима скорочена інформація. Така нативна модель знижує витрати на передачу та зберігання, суттєво зменшує затримку, покращує експлуатаційну стійкість і забезпечує екологічніші та екологічніші архітектури.
Заключне слово
Оскільки організації використовують більше автоматизації, штучного інтелекту та автономних операцій на межі, модель доставки всього в центр обробки даних стає все більш нежиттєздатною. Майбутнє — за гібридними та периферійними архітектурами, де дані обробляються локально, зменшуються або збагачуються в джерелі, а лише високоцінні результати або агрегати надсилаються наверх.
Наука про систему Землі є надзвичайно інтенсивною областю даних. Передача даних на всьому шляху від ранніх етапів розробки моделі системи Землі до рук різних співробітників і партнерів для використання в різних областях і зрештою для публікації є серйозною справою. Навіть коли ці дані стають доступними, виникає додаткова проблема щодо виявлення даних, пошуку конкретних даних, які стосуються вашої роботи. На щастя, є тип технології, який може як допомогти в конвеєрах публікації даних, так і покращити видимість – каталоги даних.
Каталоги даних — це бази даних із можливістю пошуку, у яких доступні набори даних, їхні метадані та де вони зберігаються. У науках про Землю використовуються дві популярні технології каталогів: Intake catalogs і SpatioTemporal Asset Catalogs (STAC). Вхідні каталоги зараз використовуються в різних конвеєрах Лабораторії геофізичної динаміки рідин (GFDL), але потужність і жвава екосистема, яку забезпечують STAC, дають можливість масштабувати та покращувати видимість. У першій частині цього виступу ми порівняємо ці технології, продемонструємо потужність STAC і пояснимо, чому ми рухаємося до STAC як основи для виявлення даних у GFDL. У другій частині цього виступу детально розглянемо унікальний конвеєр публікації даних і покажемо, як ми можемо використовувати потужність каталогів даних для покращення наших процесів.
біографія
Арія Радік, інженер-програміст у SAIC, працює в групі з обробки даних у Геофізичній лабораторії гідродинаміки (GFDL) Національного управління океанічних і атмосферних досліджень (NOAA). Арія зосереджується на науці про дані та оптимізації аналізу даних, і вона захоплена програмним забезпеченням із відкритим кодом і відкритим доступом до даних. Вона вважає, що покращення доступності інструментів і даних не тільки покращує відтворюваність наукових результатів, але й дає змогу більшій кількості людей у всьому світі та в різних наукових дисциплінах колективно використовувати їх для вдосконалення нашого спільного розуміння клімату Землі. Щоб досягти цієї мети, вона розробляє та покращує конвеєр публікації даних, щоб полегшити відкритий доступ до даних земної системи та створює систему в GFDL для каталогізації цих даних і полегшення їх пошуку. У 2024 році Арія отримала ступінь доктора філософії з теоретичної фізики елементарних частинок в Університеті Орегону.
JPMorgan укладає угоди про платний доступ до даних з великими агрегаторами, змінюючи відкриті банківські системи США, оскільки регулятори переглядають національні правила обміну даними.
Дізнайтеся про головні новини та події у сфері фінтех!
JPMorgan переходить до формалізації економіки обміну даними
JPMorgan Chase уклав угоди з кількома великими агрегаторами даних, які запровадять платний доступ до інформації про банківські рахунки клієнтів, знаменуючи вирішальну зміну в тому, як фінансовий сектор США обробляє потоки даних третіх сторін. Ці угоди, укладені після тижнів переговорів, дають найбільшому банку країни нову лінію доходів від підключення до даних і сигналізують про те, що відкриті банкінги в Сполучених Штатах переходять у фазу більш комерціалізації.
За даними банку, домовленості були завершені з Plaid, Yodlee, Morningstar і Akoya. Ці фірми знаходяться між фінансовими установами та фінтех-компаніїзабезпечуючи канали, через які додатки для бюджетування, платіжні сервіси та цифрові фінансові інструменти взаємодіють із обліковими записами споживачів.
Протягом багатьох років цей доступ був безкоштовним для агрегаторів. Банки стверджували, що така динаміка створила дисбаланс: установи підтримували інфраструктуру та рівні безпеки, тоді як треті сторони створювали продукти на основі цих даних, не розділяючи операційного тягаря. Нові угоди змінюють цю структуру, вводячи ціни, які відображають погляд банку на дані як на послугу з вимірною цінністюд.
Ринок, який тихо переоцінював себе
Зсув не відбувся ізольовано. Це слідує за періодом публічних дебатів щодо вартості підключення до даних, що неодноразово з’являлося в аналізі по всьому світу. фінтех сектора. Протягом останніх місяців перевірка посилилася, оскільки банки, фінтех-компанії та регулятори зважували наслідки зростання вартості доступу до даних — тема, яка детально досліджувалася в попередніх галузевих дискусіях про зростаючі фінансові та операційні вимоги до посередників.
Переходячи до платної моделіJPMorgan підтверджує позицію, що відкриті банкінги не є безкоштовною інфраструктурою. Позиція банку відображає занепокоєння інших великих установ: передача даних потребує інвестицій у кібербезпеку, підтримку API та контроль шахрайства, і все це несе матеріальні витрати. Нова модель сигналізує про більш чіткий розподіл цих обов’язків.
Джерела, знайомі з переговорами, повідомили, що JPMorgan знизив свою початкову цінову пропозицію, а агрегатори отримали більшу ясність щодо того, як оброблятимуться запити на дані. Цей баланс дозволив обом сторонам досягти домовленостей після тривалих переговорів.
Зіткнення між ринковими силами та регулюванням
Терміни цих угод є значними. Правило відкритого банківського обслуговування Бюро захисту прав споживачів, запроваджене під час попередньої адміністрації, створило очікування вільного перенесення даних. Це правило визначило обмін даними, спрямований на споживача, як право, яке має реалізовуватися без плати, що спонукало фінтех-компанії передбачати середовище, де доступ буде безкоштовним і стандартизованим.
Банки заперечували, що така модель недооцінює ризики безпеки та операційне навантаження, пов’язане з великомасштабними потоками даних.. Вони поставили під сумнів повноваження CFPB і стверджували, що безкоштовний мандат створює нерівномірну систему, в якій установи несуть повну вартість захисту даних. Нормативна дискусія швидко стала точкою напруги.
Цього року CFPB почав переробляти свою структуру після тиску з боку керівників фінансових технологій, засновників криптовалют та учасників індустрії, які прагнули більш чітких правил і більш ефективних визначень. Майбутнє регулювання залишається невизначеним, і останні угоди між JPMorgan і агрегаторами зараз перебувають у тій сірій зоні — період, коли національний звід правил переглядається, але сам ринок уже адаптується.
Політичне середовище додає складності
За нинішньої адміністрації сигнали неоднозначні. Ранні повідомлення були узгоджені з банками, які хотіли відкласти або скасувати правило. Пізніше офіційні особи зайняли більш нейтральну позицію, визнаючи, що зміни в секторі цифрових фінансів вимагають оновлених інструкцій. Виникла невизначеність змусила банки та фінтех-компанії вагатися щодо довгострокових зобов’язань.
На цьому тлі підхід JPMorgan підкреслює, як приватні угоди можуть заповнити порожнечу, тоді як федеральні стандарти залишаються неврегульованими. Ці угоди створюють шлях для доступу до даних, який регулюється не нормативними актами, а комерційними умовами, узгодженими безпосередньо між гравцями галузі.
Фінтех-компанії повинні адаптуватися до нової структури витрат
Для фінтех-компаній результат змінює середовище, в якому вони працюють. Багато побудованих моделей на очікування, що підключення до даних залишатиметься недорогим або безкоштовним. Запровадження платного доступу змушує переглянути структуру витрат, особливо для додатків, які покладаються на часте оновлення великих обсягів даних.
Сектор фінансових технологій уже стикається зі зростанням операційних витрат, питання, яке детально розглядалося в попередніх роздумах, аналізуючи комплексний ефект комісії, оновлення відповідності та потреб у інфраструктурі. Нова модель JPMorgan додає ще один елемент до цього рівняння.
Керівникам фінансових технологій тепер потрібно буде визначити, які послуги можуть покрити нові витрати, які вимагають редизайну та які можуть зіткнутися зі змінами цін для споживачів. Для деяких компаній на ранній стадії перехід може прискорити пошук прямих зв’язків з банками або підштовхнути їх до пошуку партнерських відносин, які обмежують обсяг збору даних.
Чому банки кажуть, що система потребує редизайну
Банки стверджують, що компенсований доступ може призвести до більш стабільного та безпечного середовища. Вони стверджують, що передбачуваний дохід, пов’язаний із з’єднаннями для передачі даних, підтримає інвестиції в системи API, інструменти шахрайства та можливості моніторингу, які захищають як установи, так і споживачів. Кредитори також вважають, що чітке ціноутворення може зменшити навантаження на інфраструктуру, перешкоджаючи непотрібним або надлишковим викликам даних.
Угоди між JPMorgan і агрегаторами свідчать про те, що ринок починає зближуватися з таким підходом. Замість того, щоб чекати, поки федеральне законодавство врегулює це питання, установи та посередники розробляють власну версію відкритого банківського обслуговування — таку, яка позиціонує доступ до даних як економічну послугу, а не як зобов’язання.
Що буде далі
Ці угоди піднімають ширше питання про те, як розвиватиметься відкрита банківська справа в Сполучених Штатах. Якщо більше банків приймуть подібні структури ціноутворення, фінтех-компанії можуть зіткнутися з ландшафтом, визначеним не регулюванням, а двосторонніми комерційними домовленостями. Це може призвести до фрагментації, якщо ціноутворення суттєво різниться в різних установах.
Крім того, ці угоди можуть створити шаблон, який стане ринковим стандартом, забезпечуючи передбачуваність, яка, за словами фінтех-компаній і банків, їм потрібна.
Для споживачів безпосередній досвід залишається незмінним: додатки для бюджетування, платіжні інструменти та фінансові послуги продовжують працювати, як і раніше. Однак з часом вартість доступу до даних може вплинути на те, які продукти є життєздатними та яким функціям платформи надають пріоритет.
Оскільки національний звід правил переписується, галузь, здається, рухається вперед сама по собі. Крок JPMorgan є чітким повідомленням: ера вільного, необмеженого доступу до даних закінчується, і економіка відкритого банківського обслуговування в Сполучених Штатах переосмислюється з нуля.
Примітка редактора: Це перша з періодичної серії, яка розглядає аспекти економіки Колорадо, що похитується.
Економіка Колорадо блимає попереджувальними знаками. Зростання кількості робочих місць різко сповільнилося. Звільнення потроху зростають. На ринку житла спостерігається спад. І штат, і його найбільший населений пункт намагаються закрити величезні бюджетні діри. І не так багато людей хочуть сюди переїхати. На додачу до всього, найдовша зупинка роботи уряду в історії лягла на економіку.
Однак велике питання полягає в тому, чи всі похмурі дані вказують на щось більш серйозне: рецесію. І відповідь складна.
Жодних жорстких правил щодо рецесії немає, але є позапартійна дослідницька організація, яка діє як офіційний арбітр щодо рецесій у США — Національне бюро економічних досліджень. Вони кажуть, що рецесія – це «значне зниження економічної активності, яке поширюється по всій економіці та триває більше кількох місяців».
Є також кілька часто цитованих показників рецесії. Економісти часто використовують два квартали поспіль негативного зростання валового внутрішнього продукту як параметр рецесії. Але це лише один спосіб побачити це. І це не має особливого значення для більшості людей у повсякденному житті.
Що думають державні експерти?
Відповідно до прогнозу керівника бюджету Марка Феррандіно, Управління державного планування та бюджетування штату Колорадо оцінює шанси на початок рецесії наступного року на рівні 50 відсотків. Аналіз, представлений законодавцям штату у вересні, вказує на те, що тарифи президента Дональда Трампа є найбільшим ризиком підвищення шансів на рецесію.
Мита вдарили по широких секторах економіки Колорадо. Будівництво, сільське господарство та передове виробництво, як-от аерокосмічна галузь, знаходяться безпосередньо в центрі торгової війни Трампа. Водночас невизначеність, спричинена постійними змінами підходу до тарифів, є проблемою практично кожного бізнесу.
Фірмова економічна політика Трампа оскаржується в суді групою штатів і малих підприємств. Минулого тижня Верховний суд США заслухав усні аргументи у цій справі, і рішення може бути винесене протягом кількох тижнів. Тим часом підприємства вже починають перекладати вищі податки на імпорт на своїх клієнтів, зазначає прогноз бюджетного офісу Колорадо. Офіс очікує, що покупці почнуть відступати на початку наступного року, що негативно вплине на прибутки бізнесу та плани найму.
Новини Харта Ван Денбурга/СЛРБудівництво в районі Денвера Нортфілд, на північ від міжштатної автомагістралі 70..
Інші потенційні перешкоди для економіки штату включають федеральну імміграційну політику та уповільнення туризму, якщо іноземні гості вирішать не їхати до США, зазначає прогноз.
«Ми спостерігаємо підвищений ризик національної рецесії, оскільки тарифні податки Трампа створюють реальні витрати та невизначеність для компаній і всієї економіки», — сказав Шелбі Віман, речник губернатора Джареда Поліса. «Ми продовжуємо уважно стежити за всіма показниками рецесії та матимемо оновлений прогноз у грудні».
Офіс Поліса відмовився дозволити Фернандіно відповісти на запитання щодо прогнозу рецесії.
Вакансії
Для більшості людей їхня зарплата є найважливішим показником у визначенні міцності економіки. Колорадо все ще додає робочі місця, але ледве.
Зростання робочих місць по всій країні почало сповільнюватися на початку цього року в той самий час, коли непередбачувана торгова політика Трампа збурила бізнес-ландшафт. США втратили робочі місця в червні вперше з грудня 2020 року. Поки рано говорити, чи це був місячний спалах, чи вказівка на стійку тенденцію.
Прямо зараз економісти та політики дивляться наосліп через припинення роботи федерального уряду. Співробітники Бюро статистики праці США, відповідальні за щомісячний звіт про робочі місця, були звільнені. Останні доступні дані датуються серпнем. Незрозуміло, коли будуть доступні дані про нові вакансії. Як і всі інші у федеральному уряді, BLS має багато роботи, яку потрібно виконати.
Але тріщини з’явилися на ринку праці Колорадо задовго до того, як Трамп склав присягу на свій другий термін у січні. За даними Федерального резервного банку Канзас-Сіті, на початку 2024 року рівень безробіття в Колорадо перевищив рівень безробіття в США вперше після нафтового спаду в 1980-х роках. Рівень безробіття в штаті більше року залишався вищим за середній по країні. Останніми місяцями курс Колорадо знизився і наразі трохи нижчий за курс США.
Колорадо продовжує додавати робочі місця повільніше, ніж США в цілому, тенденція, яка почалася на початку минулого року. Згідно з останніми даними Бюро статистики праці США, за 12 місяців, що закінчилися в серпні, ринок праці в Колорадо зріс на 0,6 відсотка порівняно з 0,9 відсотка в США. Рейтинг Колорадо серед 50 штатів падає. У 2019 році штат Колорадо був 6-м у країні за зростанням кількості робочих місць. У 2024 році він був 22-м. За попередніми даними, на початку цього року штат Колорадо опустився на 47 місце.
Новини Харта Ван Денбурга/СЛРСаморобний знак, створений кимось, хто жадає грошей, затиснутий між кількома стовпами на Тауер-роуд на ранчо Грін-Веллі на передньому хребті Колорадо.
Важко точно визначити, чому саме ринок праці Колорадо сповільнюється порівняно з іншими штатами. Федеральний резервний банк Канзас-Сіті вказує на слабкість найму будівельників і технологій як на винуватців занепаду найму штату.
За словами Тіма Вонхоффа, директора відділу трудової інформації департаменту праці Колорадо, високоосвічена робоча сила Колорадо може стати перешкодою в нинішніх умовах, особливо в світлі звільнень у технологічному секторі за останній рік або близько того. Наявність більшої кількості технічних працівників зробила економіку штату більш схильною до цих звільнень.
«Деякі речі, які допомагають Колорадо в періоди підйому, можуть бути менш корисними для Колорадо в часи, коли відбувається менше», — сказав він.
Частково це може бути тому, що інші країни просто наздоганяють, вважає економіст МС Браян Левандовскі. Колорадо додавало робочі місця швидше, ніж США, протягом більшої частини останнього десятиліття.
«Після виходу з Великої рецесії економіка Колорадо була на справжньому розриві, і справді тривалому розриві», — сказав Левандовскі. «У нас було таке стійке високе зростання так довго, тоді як інші штати відставали у своєму відновленні… і 1763135713 вони демонструють вищі темпи зростання, ніж ми».
Звільнення
Один зі способів перевірити здоров’я ринку праці – це сповіщення про адаптацію та перепідготовку працівників, або WARN. Кожна компанія, яка має принаймні 100 співробітників, зобов’язана подати заяву WARN до штату, якщо вона має намір звільнити 50 або більше працівників.
Це не ідеальний показник, оскільки він не охоплює малий бізнес і менші скорочення робочих місць. Але він надає широкий контекст. Показники WARN у Колорадо невпинно зростають з 2023 року. Але вони не підвищувалися. Таких сповіщень було частіше в цей час у 2016 році під час різкого падіння цін на нафту, що призвело до втрати робочих місць в енергетичному секторі.
Новини Харта Ван Денбурга/СЛРЗачинені двері на порожньому вантажному майданчику величезного комерційного приміщення, яке здається в оренду, на ранчо Грін Веллі на передньому хребті Колорадо.
«Хоча ми спостерігаємо повільне зростання кількості робочих місць, ми також не бачимо швидкого погіршення ситуації на ринку праці», – сказав Левандовскі. «Я думаю, що це відповідає тому, що ми чуємо в країні, де роботодавці можуть не додавати стільки працівників, але вони також не відпускають своїх працівників».
Індекс довіри
Споживча впевненість є одним із найбільш уважних показників для економістів, які хочуть заздалегідь зрозуміти, куди рухається економіка. Він приймає температуру вібрацій. Якщо люди з оптимізмом дивляться на своє фінансове майбутнє, вони, швидше за все, будуть витрачати гроші, таким чином підтримуючи економіку. Якщо вони нервують, вони відмовляться від витрат, що гальмує. Це свого роду пророцтво, що самореалізується.
Серед найбільш цитованих показників того, як люди в США ставляться до грошей, є щомісячний індекс споживчої довіри Conference Board. Колорадо входить до Індексу гірських регіонів, до якого також входять Арізона, Айдахо, Монтана, Невада, Нью-Мексико, Юта та Вайомінг. Жителі гірських штатів почуваються досить добре щодо того, де вони зараз, і досить погано щодо того, що вони очікують, що станеться протягом наступних шести місяців.
У жовтні респонденти висловлювали значно більший настрій щодо майбутнього, ніж на початку року.
Жителі тихоокеанського регіону, який охоплює Аляску, Каліфорнію, Гаваї, Орегон і Вашингтон, найбільш песимістичні щодо економіки. Найбільш оптимістичні люди, згідно з дослідженням Conference Board, живуть в Алабамі, Кентуккі, Міссісіпі та Теннессі.
Ринок житла
У багатьох районах США ринок житла млявий, оскільки високі процентні ставки та високі ціни ускладнюють придбання житла. За даними компанії CoStar, що займається даними про нерухомість, наразі Денвер є одним із найповільніших великих міст США з точки зору продажу житла.
За словами ріелтора з Денвера Купера Тайєра, справа не лише в Денвері — непродані будинки накопичуються по всьому штату.
«Найбільший заголовок цього року — це просто більше запасів, ніж ми мали приблизно за 13 років», — сказав Теєр. «Це всюди, в країні, але особливо поширене тут, у Колорадо».
На кінець жовтня по всьому штату було виставлено на продаж 30 803 будинки — у 2022 році їх було 19 125.
“На ринок не обов'язково з'являється більше оголошень. Наші нові показники оголошень залишаються неймовірно стабільними. Отже, очевидно, причиною цього є те, що будинки залишаються на ринку довше… Це не обов'язково більше людей, які вирішують продати, це менше покупців, які вирішують купити”, – сказав Теєр.
Новини Харта Ван Денбурга/СЛРНові будинки на східній стороні ранчо Green Valley на передньому хребті Колорадо.
За словами Теєра, доступність є частиною того, що стримує угоди. За його словами, навіть поки будинки залишаються на ринку, ціни на житло не впали до того, що готові платити покупці.
“Доступність є однією з найбільших проблем. І причина того, що у нас не так багато доступного житла, полягає в тому, що ми просто не маємо житлового фонду початкового рівня… Нам потрібно більше розвивати житло початкового рівня для продажу, і ми робимо кроки в цьому напрямку”, – сказав Теєр.
Отже, чи схоже на застійний ринок житла рецесію? Теєр не вважає, що дані поки що підтверджують це. За його словами, найбільшим тривожним сигналом стане те, що ціни на житло почнуть щорічно падати.
Він також стежить за тим, як довго будинки стоять на ринку. Продаж будинку в Колорадо займає більше часу, ніж кілька років тому. Але це ще далеко не те, що було під час рецесії, спричиненої житловою кризою, сказав Теєр. За його словами, у 2011 році середній будинок був на ринку 120 днів.
«Якби ми побачили значний сплеск до 80-100 днів у середньому по штату, це означало б для мене, що ми стикаємося з реальними проблемами», — сказав Теєр.
Заробітна плата
Колорадці відстають від решти нації, коли мова заходить про оплату. За даними Управління державного планування та бюджету штату Колорадо, останні дані свідчать про зростання особистих доходів США на 4,7 відсотка порівняно з 4,3 відсотка в Колорадо. Офіс прогнозує, що жителі Колорадо завершать 2025 рік із зростанням заробітної плати на 4,2 відсотка проти 4,3 відсотка в США. Бюджетні чиновники очікують, що наступного року зростання заробітної плати в Колорадо сповільниться до 3,8 відсотка.
Новини Харта Ван Денбурга/СЛРСкрепери за роботою, готуючи грунт для ще масштабніших запланованих нових розробок у Аврора Хайлендс на передньому хребті Колорадо.
ВВП
ВВП, загальна сума всіх товарів і послуг, вироблених за певний період часу, є важливим показником, навіть якщо він нематеріальний для більшості людей. Якщо це число падає, економіка, ймовірно, також падає.
“Я вважаю, що ВВП як індикатор справді вловлює багато інших сигналів. Тож якщо ми маємо від’ємне зростання зайнятості, падіння доходів, різке падіння роздрібних продажів чи зупинку інвестицій, це все компоненти, які входять у ВВП”, – сказав Левандовскі з CU.
Одним із недоліків використання ВВП як засобу для визначення рецесії є те, що для отримання даних потрібен деякий час. Востаннє ВВП розраховували за другий квартал, тобто з квітня по червень. Для США ВВП зріс на 3,8 відсотка. У Колорадо зростання склало 3,5 відсотка.
Багато чого сталося з червня, але показники ВВП будуть оновлені лише в грудні.
Підтримує Гонолулу Accuity LLPодна з найбільших місцевих бухгалтерських та консультаційних фірм на Гаваях, приєдналася Альянс професіоналів Критущо відзначає 30-ту співпрацю Криту та її перше розширення за межі континентальних Сполучених Штатів.
Заснована трохи більше двох років тому, компанія Crete об’єднала понад 30 бухгалтерських і консультаційних фірм для спільної місії модернізації професії за допомогою технологій, співпраці та масштабу. Альянс, який підтримується Thrive Capital і Bessemer Venture Partners, надає своїм компаніям-партнерам ресурси корпоративного рівня в області кадрів, фінансів, права та ІТ, а також інструменти з підтримкою штучного інтелекту, рішення для автоматизації та глобальні команди доставки.
«Кріт був побудований на вірі в те, що фірми з глибокими зв’язками на місцевому рівні можуть розблокувати надзвичайне зростання, маючи доступ до сучасних інструментів, даних і масштабу», – сказав Стів Стегнергенеральний директор Crete. “Accuity здобула надійну репутацію на Гаваях, розуміючи структуру ділової спільноти. Їхнє партнерство з Crete розширить їхню здатність обслуговувати клієнтів, зберігаючи при цьому місцеві цінності, які роблять їх унікальними”.
Корі Куботагенеральний директор Accuity, додав: “Це партнерство являє собою сміливу інвестицію в майбутнє Гаваїв. Платформа Crete дає нам доступ до передових технологій, національних ресурсів і мережі перспективних колег, дозволяючи нам залишатися вірними тому, ким ми є”.
Аллан Д. Колтінгенеральний директор Koltin Consulting Group, який консультував обидві фірми щодо партнерства, описав цей крок як одну з найважливіших подій на бухгалтерському ринку Гаваїв. “Accuity глибоко поважають за його репутацію, культуру та відносини з клієнтами. Те, що вони вибрали Кріт як свого партнера, говорить усе про бачення та інновації Crete”, – сказав він.
Accuity збереже своє місцеве лідерство та бренд, одночасно використовуючи національну платформу Криту для покращення своїх послуг і зростання в західному регіоні.
З 9 по 11 листопада 2025 року Департамент у справах Латинської Америки та Карибського басейну Міністерства закордонних справ організував візит дипломатичних представників країн Латинської Америки та Карибського басейну (ЛАК) у Китай до Гуйчжоу. У візиті взяли участь посли та дипломати з 17 країн, зокрема Домініки, Куби, Коста-Ріки, Ямайки, Венесуели, Панами, Домініканської Республіки та Чилі.
Заступник секретаря Комітету провінції Гуйчжоу КПК і губернатор провінції Гуйчжоу Лі Бінцзюнь зустрівся з дипломатичними представниками та заявив, що провінція Гуйчжоу зараз повністю виконує керівні принципи четвертого пленарного засідання ЦК 20-го скликання Комуністичної партії Китаю (КПК) і прагне продемонструвати новий образ Гуйчжоу в процесі модернізації Китаю. Провінція Гуйчжоу готова зміцнювати обміни та співпрацю з країнами LAC у різних сферах, а також підтримувати реалізацію п’яти програм для побудови спільноти Китай-LAC зі спільним майбутнім.
Під час візиту дипломатичні представники оглянули такі об’єкти, як сферичний радіотелескоп із п’ятсотметровою апертурою (FAST), виставковий центр великих даних у Гуйчжоу, міст Пінтан, громаду Цзіньюань та село Сіцзян Цяньху Мяо. Вони високо оцінили досягнення Гуйчжоу в інфраструктурі, цифровій економіці, зеленому розвитку, соціальному управлінні та боротьбі з бідністю, а також висловили готовність сприяти поглибленню обміну та співпраці між їхніми країнами та провінцією Гуйчжоу для взаємної вигоди та взаємовигідних результатів.