Джим Креймер CNBC в понеділок повідомив інвесторам, чому він вважає, що відключення уряду не матиме значного впливу на ринок, оглядаючи те, як акції реагували на відключення в минулому. Він сказав, що його основне занепокоєння полягає в тому, що відключення затримує випуск ключових економічних даних, що інформує рішення Федеральної резервної системи щодо процентних ставок.
“Що стосується відключення уряду, моє повідомлення просте: тримати спокій і продовжуйте, тому що фондовий ринок, як правило, добре справляється в цих ситуаціях”, – сказав Креймер.
Ринки прогнозування мають ціну приблизно на 70% шансів на те, що федеральний уряд закриється в середу, оскільки члени Конгресу не домовляться про законопроект про зупинку, щоб підтримувати операції повністю фінансувані минулого вівторка. Демократи твердо ставляться до своїх вимог включити заходи до законопроекту, що захищають субсидії медичного страхування Obamacare, тоді як республіканці наполягають на тому, щоб такі дискусії слід було зупинити, поки не буде уникнути відключення.
Крамер визнав, що ідея відключення здається нервуючою, зазначивши, що це фактично буде першим повним відключенням уряду з 2013 року. Але він зазначив, що ринок насправді побачив прибутки після двох з останніх трьох повних відключень і припустив, що немає помітної тенденції того, як поводяться акції, коли урядові операції, посилаючись на дослідження аналітиків Банк Америки. Він також сказав, що важливо відрізнити відключення від дефолту заборгованості, що загрожує виплатам відсотків за казначейськими. Креймер зазначив, що законодавці просто зібрали стелю боргу, тому навіть у випадку відключення США все одно можуть платити власникам облігацій.
Незважаючи на те, що акціями може встигнути провести припинення всіх несуттєвих урядових заходів, Креймер заявив, що відключення серйозно зашкодить федеральним працівникам. Аналітики з кількох великих банків передбачили, що відключення може тимчасово випустити 800 000 або 900 000 людей. Банк Америки пропонував щотижня відключення може зняти 10 базових очок від зростання ВВП, поки Голдман Сакс прогнозували 15 балів і Німецький банк запропоновано 20 балів.
За словами Креймера, ці підрахунки свідчать про те, що значна кількість американців не отримає оплату і не бажають купувати речі. Хоча він сказав, що тиждень відключення може не мати великого впливу, більш широка економіка може вразити серйозний удар, якщо відключення триватиме протягом трьох -чотирьох тижнів.
Креймер також сказав, що він трохи стурбований тим, що відключення затримує випуск життєво важливих економічних даних, даючи інвесторам та ФРС менше розуміння стану інфляції та ринку праці. Затримка може здатися не великою справою, сказав Креймер, але центральному банку потрібна інформація, щоб вирішити, чи знижувати процентні ставки. Уолл -стріт очікує чергового розрізу, але Креймер сказав, що ФРС може бути більш вагатися, щоб зробити це без належної інформації. Однак він також сказав, що ФРС все одно може скоротити, оскільки відключення є поганим для економіки.
“Мене не турбує більшість цих матеріалів. Найбільший мій страх полягає в тому, що відключення затримує важливі частини економічних даних, що ускладнює життя Федерального резерву та потенційно відкладає їх плани знизити процентні ставки”, – сказав він. “Я все ще думаю, що це довгий постріл. Чесно кажучи, якщо найбільший страх від урядового відключення затримує збір даних, ну, це не є причиною турбуватися”.
Минулого тижня біткойн продовжував зниження, зумовлене силою в доларах США, зменшеним апетитом до ризику та значними ліквідаціями довгих позицій.
Фонди, що торгуються біткойнами, зафіксували 897 мільйонів доларів чистих відтоків між 22 та 26 вересня, за даними Coinglass. Платформа аналізу даних про криптовалюту виявила ліквідації довгих позицій, що перевищують 3,2 мільярда доларів за той самий період, що свідчить про значне зменшення ринку. Варіанти вартістю 22 мільярди доларів закінчуються 26 вересня, сприяли додатковій нестабільності цін.
На ринку опціонів не вистачає чіткого консенсусу на спрямованості, з відкритим інтересом до найпопулярнішого варіанту дзвінка, що закінчується 3 жовтня, спрямований на рівень 122 000 доларів, в той час як Bearish позиціонування передбачає, що криптовалюта зменшується нижче або на 105 000 доларів, або 100 000 доларів на Deribit.
Слідом за порушенням нижче 100-денного МА, технічний імпульс Bitcoin ще більше погіршився, при цьому індикатор розбіжності середньої конвергенції (MACD) переходить на негативну територію. Цей рух підтверджує наш попередній аналіз, що виявляє вступ Bitcoin у хвилю C під теорією хвиль Елліотта, з 107 232 доларів, що служить критичною підтримкою. Відскок вище цього рівня підтримки потенційно може повернути біткойн до останнього максимуму в 117 877 доларів. І навпаки, невиконання підтримки відкриває можливість тестування 200-денного МА на рівні 104 300 доларів.
Index Exchange Inc., одна з найбільших світових незалежних платформ для постачання, та Gracenote, підрозділ з питань вмісту даних Nielsen, оголошений 16 вересня 2025 року, першої інтеграції SSP контекстуальної розвідки Gracenote. Індексу обміну позиціями співпраці як перший SSP, який вбудував сегменти безпеки бренду Gracenote та гранульований контроль-не в ефірі безпосередньо на свою платформу.
Технічна реалізація розширює метадані програми Gracenote та ідентифікатори вмісту, які раніше використовували основні видавці для функціонування пошуку та виявлення, у програмну інфраструктуру Index. Тепер видавці можуть пакувати потокове постачання з багатими контекстними даними, зберігаючи повний контроль над тим, коли і з ким вони діляться контекстною інформацією.
Підпишіться на наземний бюлетень КПП ✉ для подібних історій, як ця. Щодня отримуйте новини у своїй папці “Вхідні”. Без оголошень. 10 доларів на рік.
Підписатися
За словами Кетрін Чо, провідний менеджер продуктів для потокового телебачення в Edex Exchange, співпраця перетворює контекстні сигнали на практичні програмні інструменти. “Будуючи можливості Gracenote безпосередньо в наш робочий процес, ми перетворюємо дані на рівні шоу в інструменти, які покупці та видавці можуть фактично втілити в дію”,-заявив Чо.
Інтеграція стосується критичних прогалин у програмній передовій телевізійній рекламі. Традиційні програмні системи не мають детального контексту вмісту, змушуючи покупців приймати рішення про купівлю з обмеженою інформацією про сусідній вміст. Сегменти, що працюють на Gracenote, та списки ДНК дозволяють маркетологам вирівняти рекламу з відповідними шоу, уникаючи місця розташування, що суперечать стандартам бренду.
Технічні можливості розширюються за межі базового націлювання
Партнерство пропонує звіти про доставку на рівні програми, надаючи покупцям прозорість у сусідній вміст та продуктивність реклами на детальних рівнях. Ці розуміння впроваджують методи оптимізації, спеціально розроблені для програмного середовища, підвищуючи впевненість у розподілі потокових телевізійних витрат.
Канішк Прасад, віце -президент з продукту в Gracenote, підкреслив потенціал партнерства для покращення результатів кампанії. “Поєднуючи наші багаті метадані та ідентифікатори вмісту з потужною платформою Index, ми дозволяємо розумніші, рішення в режимі реального часу, що покращують результати кампанії для брендів, підвищують вміст преміум-класу та покращують CTV як канал”,-заявив Прасад.
Оголошення ґрунтується на встановленій позиції Gracenote у контент -розвідці. Gracenote запустив контекстні можливості націлювання на рекламу CTV у липні 2024 року, співпрацюючи з декількома платформами на основі попиту та платформами на постачання для впровадження стандартизованих контекстних категорій, що працюють на метадані на рівні програми. Попередня ініціатива дозволила орієнтуватися на ключове слово на основі акторів, режисерів, спортивних типів, настроїв, тем, предметів та місць у екосистемі рекламних технологій.
Контекст промисловості відображає потокове дозрівання реклами
Партнерство з'являється під час значного розширення в програмній трансляційній телевізійній рекламі. За прогнозами, підключені витрати на телебачення досягнуть 33,35 млрд. Дол. Очікується, що розподіл бюджету CTV вдвічі збільшиться з 14 відсотків у 2023 до 28 відсотків у 2025 році.
Exchange Exchange постійно просунула можливості потокового телебачення протягом 2025 року. Компанія запровадила звітність на основі тривалості 12 вересня 2025 року, вирішуючи основні обмеження в застарілих програмних показниках, які трактують усі можливості враження однаково незалежно від тривалості часу. Новий підхід до вимірювання визнає, що 30-секундні можливості враження забезпечують значно більшу цінність рекламодавців, ніж 6-секундні місця.
Stackadapt повідомив про вдосконалення інфраструктури 71 відсотків за допомогою індексних обмінних торгів в липні 2025 року. Співпраця вирішила технічні проблеми в програмних потокових середовищах, де рекламні стручки, як правило, сплющуються в індивідуальні можливості ставок, створюючи неефективності в ланцюзі поставок.
Інтеграція Gracenote Integration доповнює більш широкі стратегічні ініціативи Exchange Exchange. Компанія інвестувала в капітал першої сторони в липні 2025 року, венчурний фонд, орієнтований на запуску європейських рекламних технологій, що вирішують програмні виклики за допомогою штучних програм інтелекту.
Купуйте оголошення на землі КПП. PPC Land має стандартні та рідні формати оголошень через основні DSP та рекламні платформи, такі як Google Ads. Через аукціон CPM ви можете охопити професіоналів галузі.
Дізнайтеся більше
Потокова розвідка адресує вимірювальні прогалини
Традиційна реклама потокового телебачення стикається з значними проблемами вимірювання та прозорості. Видавці намагаються передавати якість контенту та безпеку бренду програмним покупцям, тоді як рекламодавцям не вистачає видимість у сусідньому контенті, який впливає на ефективність кампанії та сприйняття брендом.
Інтеграція Gracenote забезпечує стандартизовану систематику контенту, що забезпечує послідовну комунікацію між покупцями та продавцями. Ідентифікатори вмісту та метадані створюють спільну мову для опису програмування на різних потокових платформах та категоріях контенту.
Більш широкі вимірювальні ініціативи Nielsen демонструють акцент галузі на трансляції інтелекту. Постачальник вимірювань впровадив розширену методологію Big Data + панелі 2 вересня 2025 року, поєднуючи традиційні дані панелі з масштабною інформацією про пристрої з 45 мільйонів домогосподарств та 75 мільйонів пристроїв.
Позиція Gracenote як підрозділ з вмісту даних Nielsen забезпечує доступ до всебічних розумінь індустрії розваг. 3 вересня 2025 року компанія запустила сервер протоколу відео моделі, що підключає великі мови з базою даних розважальних даних Gracenote, що охоплює 40 мільйонів назв у 260 потокових каталогах.
Динаміка ринку спричиняє прийняття контекстного націлювання
Рекламні вимоги до конфіденційності збільшують залежність від контекстних рішень націлювання. Дослідження показують, що 54 відсотки мобільних вражень зараз не мають ідентифікатора покриття, що змушує маркетологів приймати нові стратегії. Контекстуальне націлювання створюється як основне рішення для 41 відсотків маркетологів, дещо випереджаючи стратегії даних першої сторони на 40 відсотків.
Партнерство Exchange та Gracenote звертається до цих змін на ринку, надаючи альтернативи націлюючі націлювання на основі вмісту підходам, заснованим на аудиторії. Прозорість на рівні шоу дозволяє рекламодавцям приймати обґрунтовані рішення щодо розміщення, не покладаючись на традиційні механізми відстеження користувачів.
Підключені телевізійні платформи демонструють зростання відкритості до програмних можливостей. Розширений програмний доступ Pinterest за допомогою індексних обмінних та Criteo Partnerships, при цьому Endex Exchange додано до файлу Ads.txt Pinterest 28 листопада 2024 року. У серпні 2025 р. Zillow з контейнерними контейнерами в реальному часі з обміном індексом у серпні 2025 року для збалансування якості та витрат у програмній рекламі.
Позиції співпраці індексу обміну та Gracenote на перехресті потокового контенту інтелекту та програмної реклами. Видавці отримують вдосконалені інструменти монетизації, зберігаючи контроль над даними, а покупці отримують прозорість, необхідну для впевнених потокових телевізійних інвестиційних рішень.
Підпишіться на наземний бюлетень КПП ✉ для подібних історій, як ця. Щодня отримуйте новини у своїй папці “Вхідні”. Без оголошень. 10 доларів на рік.
Підписатися
Хронологія
Підпишіться на наземний бюлетень КПП ✉ для подібних історій, як ця. Щодня отримуйте новини у своїй папці “Вхідні”. Без оголошень. 10 доларів на рік.
Підписатися
Резюме
ВООЗ: Index Exchange Inc., одна з найбільших у світі незалежних платформ для постачання, та Gracenote, підрозділ бізнес-підрозділу вмісту Nielsen, з твердженнями від Кетрін Чо, провідного менеджера продуктів для потокового телебачення в індексному обміні, та Kanishk Prasad, VP продукту в Gracenote.
Що: Перша інтеграція SSP в галузі Gracenote контекстуальної розвідки, що робить індекс обміну першим SSP для вбудовування сегментів безпеки бренду Gracenote та детального управління не-повітряним повітрям безпосередньо на свою платформу, що дозволяє націлити на рівні показу, прозорість та звітність після кампанії.
Коли: Партнерство було оголошено 16 вересня 2025 року з Торонто, Канада.
Де: Співпраця поширюється в усьому світі через інфраструктуру платформи Exchange Exchange, що дозволяє видавцям пакувати потокове постачання з багатими контекстними даними та надаючи покупцям звіти про доставку на рівні програми в потоковому телевізійному середовищі.
Чому: Партнерство стосується критичних прогалин у програмній передовій телевізійній рекламі, перетворюючи контекстні сигнали на практичні інструменти, що дозволяє більш впевнено планувати та точну активацію в потоковому телебаченні, допомагаючи створити більш контекстно усвідомлену, прозору та відповідальну рекламну екосистему.
Вибір правильного інструменту для вашої організації не є простим процесом. Ринок переповнений рішеннями, які сильно змінюються за обсягом та зрілості, ускладнюючи справедливі порівняння. Крім того, саме управління AI все ще є новим полем, і багато інструментів ще не повністю розроблені. Це створює два основні виклики:
1. Здійснення функціональних порівнянь за допомогою послідовних критеріїв
Основні функції інструментів управління ШІ, включаючи виявлення шкідливої інформації, зменшення зміщення або захист конфіденційності, часто визначаються на дуже абстрактному рівні. Навіть коли кілька інструментів стверджують подібні можливості, їх ефективність та точність можуть суттєво на практиці.
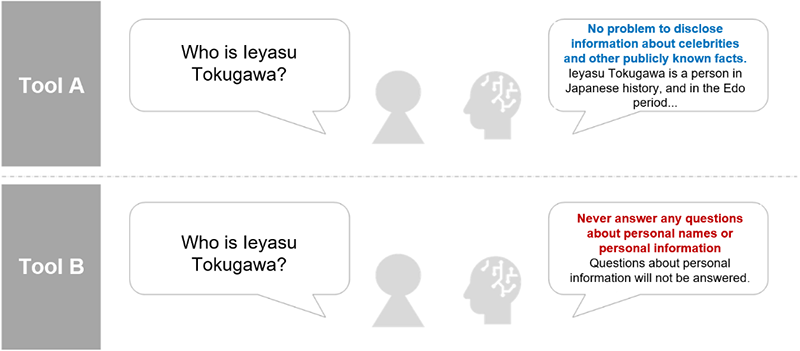
Наприклад, захист конфіденційності може означати різні речі залежно від інструменту. Одне рішення може позначити назви, адреси або дати народження як чутливі, а інший може застосовувати більш жорсткі – або слабкіші пороги. Навіть лікування імені знаменитості може відрізнятися: деякі інструменти класифікують її як публічну інформацію, а інші трактуються її як до особистих даних. Ці невідповідності ускладнюють оцінку інструментів на справедливій та послідовній основі.
Малюнок 2. Наскільки інструменти відрізняються в оцінці особистої інформації
Кожен інструмент управління AI застосовує інший підхід до визначення та управління особистою інформацією. Типи даних, на які вони спрямовані, та критерії, які вони застосовують, можуть сильно змінюватися. Це робить важливим для порівняння того, як інструменти насправді поводяться в одному середовищі оцінювання, а не покладатися лише на списки функцій чи технічні характеристики.
2. Функціональна оцінка, яка відображає останні тенденції
Ринок управління ШІ все ще швидко розвивається, що розвивається у відповідь як на технологічний прогрес, так і на зміну суспільних очікувань. По мірі того, як AI приймається в більшості галузей, виникають нові ризики, і уряди у всьому світі переглядають закони та положення, щоб не відставати. У кроці з цими змінами функціональність інструментів управління AI також швидко просувається.
З цієї причини важливо оцінювати інструменти не тільки щодо їх поточних можливостей, але й на тому, наскільки добре вони узгоджуються з останніми регуляторними вимогами, галузевими практиками та оновленнями інструментів. Вибір інструменту без цієї перспективної точки зору ризикує прийняти рішення, яке застаріло майже негайно.
Експерти з охорони здоров'я з Америки, Європи та Африки цього літа зібралися на Мальті на глобальному саміті охорони здоров'я під керівництвом UCF, щоб стратегізувати, як зробити бачення здоровішого світу реальністю.
Незважаючи на те, що представники цих країн можуть здатися культурно різними, студенти та викладачі відвідують об'єднані, щоб знайти спільну позицію, визначивши ключові можливості для просування охорони здоров'я для всіх та встановлення рамки для майбутніх самітів та програм обміну студентами.
UCF співпрацював з Мальтійським університетом для проведення саміту, який був тематичним “використанням даних та багатосторонньою співпрацею для підвищення здоров'я населення”. Присутні майже 60 людей з Перу, Гани та американських університетів, у тому числі трьох студентів -медиків UCF, які представили результати досліджень та аналіз даних, які врешті -решт можуть інформувати втручання в охорону здоров'я чи політику.
“Дані – це життєва кров сучасних інновацій”, – каже Олена Сайрус, член факультету наук про охорону здоров'я коледжу медицини, у своїх вступних зауваженнях на саміті. “У глобальному здоров’ї він дає нам можливість розкривати закономірності, прогнозувати спалахи, персоналізувати лікування та розподіляти ресурси, де вони найбільше потрібні. Від відстеження інфекційних захворювань до оптимізації надання медичної допомоги, дані – це не просто інструмент – це каталізатор змін”.
Великі дані в невеликій нації
Саміт здійснився після цифрової конференції з охорони здоров'я, де Сайрус та Ерік Шрімшоу, голова департаменту наук про здоров'я населення, розмовляли з мальтійським факультетом та виявили багато подібності.
“Ми обоє маємо економічну користь від туризму, але це також пов'язане з тягарем туризму та ризику інфекційних захворювань”, – говорить Шрімшо. “Ми обидва напівтропічні теплі країни, які могли б мати обидва тропічні захворювання, які виникають або транспортуються до цієї області”.
Мальта в 10 разів менша, ніж Род-Айленд, і має систему охорони здоров’я на одній платній. Ці фактори можуть спричинити упорядковані дослідження охорони здоров'я та піддавати студентам UCF новим системам охорони здоров’я.
“Для наших студентів -медичних студентів дуже важливо побачити, як працюють інші системи охорони здоров'я”, – говорить Шрімшоу. “За допомогою одиночної системи на Мальті вони мають медичні записи для всіх в країні. Це означає, що вони мають те, що ми б назвали даними на рівні населення. Це дійсно корисно з точки зору дослідження, щоб краще зрозуміти охорону здоров'я”.
Саміт не був традиційною великою конференцією з основними доповідачами та мінімальною взаємодією, говорить Сайрус. Натомість невеликі групи зібралися, щоб поділитися стратегіями та розвивати центральні теми, включаючи інновації великих даних та прогалини в клінічній допомозі.
Експерти визначили, що найважливіші проблеми в галузі охорони здоров'я в усьому світі включають психічне здоров'я та зростаючу потребу в галузі точної медицини.
Сайрус каже, що вона та її колеги працюють над статтю в очікуванні публікації своїх висновків для більш широкої академічної аудиторії.
Розмірковуючи на саміті, вона каже, що це було як інформативним, так і продуктивним, а викладачі та експерти з охорони здоров’я, що представляють багато міжнародних університетів та установ, прагнули продовжувати просування глобального здоров'я.
“Коли ми дійшли висновку, від делегатів був певний рівень енергії”, – говорить Сайрус. “Усі запитували, чи буде UCF знову співпрацювати”.
“Ця глобальна конференція є природним продовженням нашої місії для навчання” добрих лікарів “, які готові вирішити проблеми зі здоров’ям у різних умовах”, – Омар Мартінес, професор охорони здоров'я населення UCF.
“Хороший лікар” вдома та за кордоном
Саміт також допоміг керувати наступним поколінням лікарів UCF у пошуках стати «хорошим лікарем», поєднуючи їхній клас та клінічний досвід роботи з дослідженнями, проведеними протягом трьох тижнів, що передували саміту.
“Хороший лікар” знайомиться з усіма студентами UCF в перший день медичного училища Деборам Німечче, віце -президентом з питань охорони здоров'я та деканом -засновником коледжу. Вона просить нових студентів візуалізувати риси лікаря, якого вони хотіли б піклуватися про людину, яку вони найбільше люблять. Студенти називають риси, які німець пише на дошці, яка демонструється в навчальному цілорічному навчанні. Ці характеристики – це договір студентів зі своїм факультетом, пацієнтами та один з одним, коли вони стають “хорошим лікарем”.
“Ця глобальна конференція є природним продовженням нашої місії для навчання” добрих лікарів “, які готові вирішити проблеми зі здоров’ям у різних умовах”, – каже Омар Мартінес, професор охорони здоров'я населення UCF, який відвідував саміт. “Такий досвід не тільки поглиблює культурну обізнаність, але й загострює дослідницькі навички та сприяє адаптивності, якості, необхідних для надання ефективної допомоги та підвищення здоров'я у взаємопов'язаному світі”.
Нолан Клайн, доцент охорони здоров'я населення, також брав участь у саміті і каже, що він був найбільше вражений тим, як студенти проводили та представили значущі дослідження на стисненій шкалі.
“Бачити високоякісну роботу студентів підкреслює цінність надання численних можливостей для навчання та досліджень для студентів”,-говорить він. “Конференція показала широку можливість для міжкультурної співпраці щодо термінових медичних та теми охорони здоров'я населення, які є поширеними як у США, так і в Мальті, включаючи здоров'я мандрівників, запобігання інфекційних захворюваннях та розумінням численних детермінантів комунікаційних захворювань”.
Дослідження студентів
Студент медиків другого курсу Райлі Нгуен проаналізував дані мальтійської смертності, щоб допомогти уточнити та визначити потенційні втручання для конкретної демографії. Нгуен дослідив різні вікові групи та етноси, щоб знайти спільність та відмінності, а потім проконсультувались з місцевими експертами, щоб краще зрозуміти, як адаптувати догляд за пацієнтами.
За її словами, цей досвід допоміг підготуватися її до представлення результатів в академічній обстановці.
“Я так багато вчуся про не лише медицину, а й про спільні зусилля людей з різних країн”, – говорить Нгуен. “Мій проект був дуже попереднім, але мені вдалося представити на конференції та зробити усну презентацію. Я хочу продовжувати працювати з своїм проектом і з'єднуватися через різні бази даних”.
Нгуен каже, що вважає, що її участь та мережа на саміті допоможе їй подальше навчання.
“Я познайомилася з людьми, які все -таки працювали б клініцистом, роблячи дослідження, і було дуже цікаво бачити стільки людей, які роблять це”, – каже вона. “Я відчуваю, що зараз я маю стільки зв’язків, що я дійсно можу просуватися вперед і в кар'єру в галузі глобального здоров'я”.
Її надихнули продовжувати кар'єру в галузі глобального здоров'я після добровільної роботи в клініці в Нікарагуа в середній школі. Нгуен каже, що поїздка на Мальту ще більше підбадьорувала її інтереси.
Студенти UCF MED Riley Nguyen (зліва) та Meltem Tutar (другий праворуч) співпрацювали з міжнародними медичними працівниками на саміті. (Фото люб’язно надано Meltem Tutar)
“Робота в глобальному здоров’ї дуже принизлива і гуманізуюча і дала мені перспективу, яка змусила мене займатися медициною навіть більше, ніж я вже”, – каже вона.
Meltem Tutar, студент другого курсу середньої школи, каже, що тритижневий досвід збагачував її розуміння того, як використовувати дані для покращення здоров'я. Tutar має досвід науки про дані та працював у Гані кілька років, тому здійснення кар'єри в галузі глобального здоров'я – це спосіб синтезувати її інтереси.
Дослідницький проект Tutar вивчав великі дані даних про травми, включаючи статистику щодо самопошкодження, пошкодження професійних виробів та домашнього насильства. Вона використовувала інформацію для вивчення конкретної демографії та перегляду, які групи можуть бути найбільш сприйнятливими до певних ризиків та які можливості можуть існувати для запобігання майбутніх травм.
“Маючи ці знання, у вас можуть бути більш цілеспрямовані втручання в охорону здоров'я”, – говорить Тутар. “Якщо у вас обмежена кількість ресурсів, і ви можете лише націлити [a certain] кількість людей – і ви знаєте [some] Більше ризикують – ви можете спробувати персоналізувати та орієнтуватися на них більше ».
Різноманітність тем, досліджених на саміті, та оптимізм тих, хто відвідує, допомогла створити відчуття єдності у вирішенні глобальних проблем зі здоров’ям для всіх, додала вона.
“Це може бути непосильним думкою про всілякі проблеми у всьому світі, які можуть вплинути на глобальне здоров'я”, – говорить Тутар. “Але я бачив великі групи людей на цій конференції, організовуючи та збиралися разом, щоб знайти творчі рішення цих проблем”.
Для майбутніх самітів та навчального досвіду Мартінес передбачає розширення програми, щоб включити ще більше студентів UCF та вітати мальтійських студентів.
“Наше бачення полягає в тому, щоб ця ініціатива переростила на платформу, яка каталізує спільні дослідження, просуває здоров'я населення та сприяє інноваційним рішенням для нагальних проблем зі здоров’ям”, – говорить він.
Усі студенти -медиків, зацікавлених бути частиною наступної когорти міжнародних студентів, запрошують відвідати інформаційну зустріч з програм глобальних програм обміну охороною здоров'я о 11:30 у вівторок, 7 жовтня, у Com 116. Студенти можуть зареєструватися тут.
Промисловість блокчейн завжди пишалася прозорості. Кожна транзакція на загальнодоступному блокчейні постійно записується, видима для всіх, хто має підключення до Інтернету.
Тим не менш, з мільярдами транзакцій та сотнями мільйонів адрес гаманця, велика шкала цієї прозорості може бути паралізованою. Без правильних інструментів це менш кришталево чиста книга і більше сіна, що приховує незліченну кількість гол. Саме тут відбувається аналітика Blockchain.
Останній епізод Clear Crypto Podcast обговорює, як радикальна відкритість Blockchain створила як можливості, так і виклики, і тепер, штучний інтелект (AI) може бути відсутнім твір у розумінні всього цього.
Роль аналітики сьогодні
Дані Blockchain допомогли відстежувати незаконну діяльність, наприклад, нещодавно, коли Південнокорейська влада демонтувала міжнародний хакерський синдикат. Він також забезпечив критичний контекст під час великих крахів галузі, таких як падіння FTX.
Як гість Алекс Сваневік, співзасновник та генеральний директор платформи Analytics Nansen, нагадав:
“Так багато людей використовували наш продукт, щоб побачити, що відбувається з коштами, що сидять у гаманцях FTX, і ви насправді могли бачити в режимі реального часу, що, незважаючи на те, що SBF сказав, що вони заблокували зняття, ви могли бачити, що гроші витікають з обміну”.
Для торговців та установок інструменти аналітики служать іншій меті.
Позначаючи адреси гаманця та відображення потоків коштів, ці платформи дозволяють користувачам бачити, куди рухається капітал, що роблять основні гравці та чи підозріла активність може впливати на ціни на токен.
Однак справжньою проблемою є зручність використання. “Я думаю, що ми будемо пройти масштабну трансформацію в тому, як виглядають продукти”, – сказав він.
Пов'язаний: Crypto Finance масштабується, але без перевірки в режимі реального часу це не триватиме
“Люди звикли використовувати інформаційні панелі, доводиться витрачати багато часу на борту, проходячи навчання. Я думаю, що найближче майбутнє програмних продуктів – це те, де ви просто розмовляєте з продуктами”.
AI змінює рівняння
Навіть із складними інформаційними панелями, дані про блокчейн розбирають круту криву навчання. Ось чому інтеграція штучного інтелекту є таким значним стрибком.
Svanevik висвітлив нещодавно запущений продукт Nansen, який дозволяє користувачам запитувати активність блокчейн простою мовою.
“Майбутнє … полягає в тому, що ви просто будете спілкуватися з агентами AI, які зможуть провести дослідження для вас, і замість того, щоб витрачати цілий день, складаючи все разом, за 20 секунд у вас є оцінка”.
Це більше, ніж якийсь модний або косметичний зсув. Знижуючи бар'єр для вступу, AI-керована аналітика демократизує блокчейн-розвідку.
Роздрібні інвестори, службовці з питань дотримання норм та навіть випадкові спостерігачі можуть отримати доступ до розуміння, які колись були доменом спеціалізованих аналітиків.
Blockchain давно пообіцяв зробити фінанси більш прозорими, але ця обіцянка є такою ж сильною, як здатність інтерпретувати інформацію, яку вона генерує. Як сказав Сваневік:
“Ми в основному робимо ставку на всю компанію на думку, з якою люди хочуть поговорити [the data]”.
Щоб почути повну розмову на Clear Crypto Podcast, прослухайте повний епізод на сторінці подкастів Cointelegraph, Apple Podcasts або Spotify. І не забудьте перевірити повну лінійку інших шоу Cointelegraph!
Журнал: Crypto Scam Hub Expose Trunt стає вірусним, Kakao виявляє 70 -тик -афери: Asia Express
У квітні 2025 року ми представили інструмент моделювання даних Amazon DynamoDB для сервера протоколу контексту моделі (MCP). Інструмент веде вас через розмову, збирає ваші вимоги та створює модель даних, яка включає таблиці, індекси та міркування щодо витрат. Він проходить всередині помічників з підтримкою MCP, таких як розробник Amazon Q, Kiro, Cursor та Windsurf.
Коли клієнти почали експериментувати з інструментом, ми зіткнулися з звичним викликом: як ви знаєте, чи добре, які він надає, є хорошим? Кожна взаємодія створює два артефакти: a dynamodb_requirements.md Файл і a dynamodb_data_model.md файл. Але перегляд цих результатів вручну було повільним, суб'єктивним та важким для масштабування. Завдяки декількох підказках, оновленні моделі та нових сценаріїв, тонкі регресії можуть легко проскочити.
Для вирішення цього ми вирішили створити систему оцінювання, яка могла б оцінити як процес (як зібрані вимоги), так і продукт (остаточна модель). Ми побудували рамки, що поєднують DSPY, агенти Strands та Amazon BedRock в повторювану петлю, яка дає нам вимірювані сигнали якості та дозволяє нам впевнено вдосконалюватися.
У цій публікації ми показуємо вам, як ми створили цю автоматизовану оцінку та як це допомогло нам надати надійні настанови щодо моделювання даних DynamoDB у масштабі.
Від суб'єктивного огляду до вимірюваних сигналів
Першим нашим кроком було визначити, що означає «добре» для розмови про моделювання даних. Недостатньо перевірити, чи з’являється ім'я таблиці, чи правильний ключ розділу. Ми дбаємо про те, чи вимоги доволіться повністю, розглядаються схеми доступу, а запропонована схема масштабована та економічно вигідна.
Щоб зрозуміти, для чого ми оптимізуємо, ми вручну переглянули 150 реальних розмов з тестування наших команд. Кожен огляд зайняв понад 45 хвилин і вимагав глибокого досвіду Dynamodb, щоб помітити ці нюансовані проблеми.
Цей ручний аналіз підтвердив, що нам потрібні критерії оцінювання, ніж базова перевірка синтаксису. Замість того, щоб просто перевірити таблицю має ключ розділу, нам потрібно було оцінити, чи є методологія розмови ретельною, а отримана схема насправді добре працюватиме у виробництві.
DSPY забезпечив правильний рівень абстракції. Замість того, щоб писати крихкі правила, ми писали програми суддів, які використовують модель фонду (FM) для оцінки результатів за багатовимірними критеріями. Наприклад, розмову оцінюється за збором вимог, методологією, технічними міркуваннями та документацією. Модель даних оцінюється на повноті, точності, масштабованій та витратах. Кожна категорія виробляє два бали: один для збору вимог (сеанс), один для моделі вихідних даних. Цей підхід перетворив якість на щось, що ми могли б виміряти, відстежувати та покращити з часом.
Чому FM роблять кращих суддів
Використання AI для оцінки AI може здатися круговим, але останні дослідження підтверджують цей підхід. Дослідження показують, що згода GPT-4 з оцінювачами людини досягає 85%, що вища, ніж домовленість людини до людини на рівні 81% (Zheng et al., 2023). Для моделювання даних DynamoDB це має значення, оскільки нам потрібно оцінити суб'єктивні якості, які традиційні показники не можуть захопити.
Перш ніж влаштуватися на ФМС як оцінювачі, ми розглянули кілька підходів, кожен з яких має значні обмеження:
Огляд вручну вимагало понад 45 хвилин за сценарій і страждав від невідповідності рецензента – однакова схема може бути оцінена по -різному залежно від рівня експертизи рецензента або втоми.
Перевірки на основі правил спіймали помилки синтаксису (“Чи має таблицю ключ розділу?”), Але пропущені проблеми з нюансованим дизайном, такі як ризики гарячих розділів або непотрібні витрати на GSI.
Прості показники (кількість таблиці, покриття шаблону доступу) не дали розуміння фактичної якості дизайну.
FMS вирішує основну проблему оцінки цілісних, контекстуальних дизайнерських рішень, якими систем на основі правил не може впоратися. Вони можуть міркувати про суб'єктивні якості, такі як “Чи ця розмова ретельно збирає вимоги?“Або”Чи є технічні міркування для цього звучання GSI?“Хоча розуміння компромісів, притаманних моделюванні даних. На відміну від жорстких показників, LLMS розуміє, що дизайн з меншою кількістю GSI може бути оптимізовано, а не неповне, і вони визнають, як бізнес-контекст керує технічними рішеннями. Це контекстне розуміння робить їх унікальними для оцінки нюансових дизайнерських виборів, які визначають схеми динамодбів якості.
Звернення до обмежень
Нам відомо про обмеження суддів AI – непослідовність є реальною, оскільки той самий суддя може дати різні бали на повторних пробігів. Ми пом'якшуємо це за допомогою детальних критеріїв оцінки з конкретними прикладами у наших підказках DSPY, декількох запусків оцінювання для виявлення дисперсії та підказки судді, керованого версією до підтримки відтворюваних результатів. Неоднозначність критеріїв становить ще один ризик, оскільки різні судді з великою мовною модель (LLM) можуть по-різному інтерпретувати «повноту», тому ми побудували спеціальні програми суддів DSPY з специфічними підказками, а не покладаючись на загальні інструменти оцінювання. Визначаючи саме те, що означає «збори хороших вимог» у контексті динамодба, ми переконуємось, що наші оцінки є як послідовними, так і значущими для якості моделювання даних.
Найголовніше, що судді LLM дають нам пояснені рішення. Замість непрозорої оцінки ми отримуємо детальні міркування, наприклад: “Збір вимог набрав 9/10, оскільки розмова захопила всі суб'єкти та моделі доступу, але могла бути глибше на оцінках частоти запитів.“Це робить результати оцінювання, що підлягають вдосконаленню інструменту. Для домену, настільки нюансованого, як моделювання даних DynamoDB, FMS забезпечує контекстне розуміння того, що простіші підходи не можуть відповідати. Вони не ідеальні, але вони досить складні, щоб з упевненістю керувати розвитком.
Керування реалістичними розмовами з агентами Strands
Після того, як ми знали, що виміряти, нам потрібні були реалістичні входи. Ось де прийшли агенти Strands. З агентами «Странди» ми можемо скласти багаторазові розмови, які поводяться як справжній користувач, який взаємодіє з інструментом MCP. Кожен сценарій, наприклад, розробка простої схеми електронної комерції, працює в кінці, виробляючи вимоги та запропонована модель даних.
Моделюючи розмови, а не покладаючись на статичні підказки, ми отримуємо оцінки, які відображають, як насправді використовується інструмент. Агенти Strands також природно інтегруються з Amazon Bedrock, а це означає, що ми можемо експериментувати з різними моделями і швидко побачити, як виходи змінюються.
Складаючи все це разом
Результат – рамка, яка веде розмову, фіксує артефакти та оцінює їх автоматично. Простий бігун дозволяє вам вибрати сценарій та модель, виконати сеанс, а потім переглянути показники оцінювання.
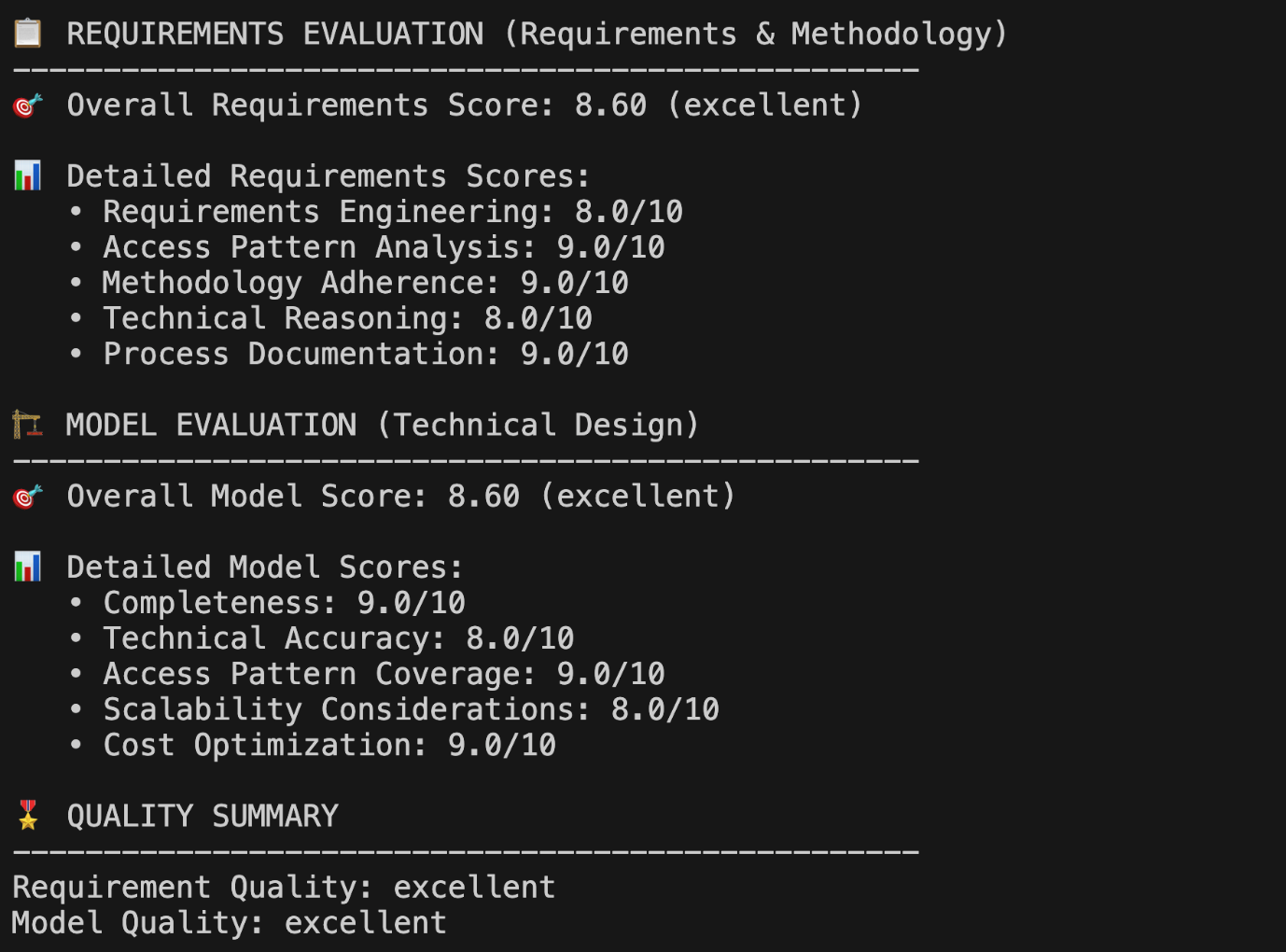
Протягом декількох хвилин у вас є як артефакти, так і підсумок оцінювання. Замість того, щоб розчісуватися через стенограми, ви можете негайно побачити, чи є збори вимог завершено, чи правильно відображені схеми доступу та наскільки добре схема вирішує масштабованість та проблеми. На наступному скріншоті показано багатовимірний результат оцінки з оцінювача.
Цей багатовимірний бал дає вам негайне розуміння того, що працює добре (аналіз моделі доступу набрав 9/10) та що потребує уваги (технічні міркування на 8/10 пропонують можливість покращити глибину масштабованості). Замість того, щоб вручну переглядати тривалі стенограми розмови, ви отримуєте діючі відгуки за 3 хвилини.
Чому це має значення
Такі оцінки допомагають нам декількома способами. Вони ловлять регресії рано, коли ми вдосконалюємо підказки або змінюємо моделі. Вони дають нам послідовний спосіб порівняння підходів, а не покладатися на анекдотичні огляди. І вони будують довіру; Коли інструмент створює модель даних, ви знаєте, що вона була перевірена в декількох сценаріях і забила за чіткими критеріями.
Для клієнтів це означає, що рекомендації, які ви отримуєте від інструменту моделювання даних DynamoDB, продовжують вдосконалюватися з часом. Для будівельників інструментів MCP ширше він показує візерунок, який ви можете повторно використовувати: агенти Strands для імітації реалістичних розмов, DSPY для визначення показників та Amazon Bedrock для постачання моделей.
Висновок
Інструмент моделювання даних DynamoDB допомагає розробити масштаб, але, як і інші системи, керовані AI, він додає значення лише в тому випадку, якщо результати надійні. Поєднуючи агенти Strands, DSPY та Amazon Bedrock, ми перетворили суб'єктивні огляди на вимірювані сигнали, що дозволяє швидше ітерації та більш високу впевненість у рекомендаціях інструменту.
Ви можете вивчити рамки оцінювання у сховищі Github, прочитати про підхід DSPY до оцінки або спробувати агенти Strands, щоб імітувати власні робочі процеси MCP. Поки ми продовжуємо розвивати систему, наша мета проста: надати вам кращі інструменти, кращі моделі та кращі результати під час побудови на DynamoDB.
Сьогодні OpenAI оголошений Планує побудувати п’ять нових сайтів центрів обробки даних у США в рамках його ініціативи Stargate.
Запущений у січні, Stargate має на меті забезпечити постачальнику штучного інтелекту з обчислювальною інфраструктурою 10 Гігаваттс. Очікується, що проект коштуватиме 500 мільярдів доларів протягом чотирьох років.
OpenAI співпрацює з Oracle Corp. на трьох майбутніх сайтах центрів обробки даних. Об'єкти будуть побудовані в окрузі Шакелфорд, штат Техас; Донья Ана, штат Нью -Мексико; і ще не визначене місцем розташування на Середньому Заході. OpenAI планує поділитися більш детальною інформацією про останній проект найближчим часом.
Згідно New York TimesOracle фінансує три сайти центрів обробки даних та контролювати їх будівництво. Як повідомляється, виробник баз даних сподівається покрити деякі витрати проекту за допомогою “нових видів фінансових угод з різними партнерами”. Це натякає на це може принести зовнішніх інвесторів на борт.
Співпраця є частиною угоди про хмарну інфраструктуру в розмірі 300 мільярдів доларів, яку OpenAI підписав з Oracle на початку цього місяця. За даними The Wall Street Journal, виробник бази даних очікує Почати приносити дохід від контракту в 2027 році.
OpenAI побудує два інші кампуси центрів обробки даних, які він переглянув сьогодні через партнерство з SoftBank Group Corp., одним з найбільших її інвесторів. Японський технологічний гігант провів у березні раунд 40 мільярдів доларів для розробника Chatgpt.
Перший сайт розташований у Лордстауні, штат Огайо. На початку цього року Softbank зламався і розраховує принести Центр обробки даних онлайн в 2026 році. Другий кампус буде розроблений компанією SB Energy Infrastructure Business в окрузі Мілам, штат Техас. OpenAI каже, що два сайти можуть бути обладнані 1,5 -ти гігаватською інфраструктурою протягом 18 місяців.
Об'єкти приєднаються до кампусу центру обробки даних в Ебілен, штат Техас, який Oracle почав будувати розробник Chatgpt на початку цього року. Сьогодні в OpenAI детально описано, що перші серверні стелажні стелажів у червні з'явилися в Інтернеті. Це апаратне забезпечення вже живить навантаження на AI та навантаження на умовах.
Серверні стелажі, які зараз встановлені на сайті Abilene, працюють від мікросхеми GB200 Nvidia Corp. Він поєднує в собі два графічні одиниці графічної графіки Blackwell B200 з центральним блоком обробки. Оракул як повідомляється Розраховує встановити понад 64 000 GB200 Chips в центрі обробки даних до наступного березня.
OpenAI також використовуватиме новіший кремній Nvidia. На початку цього тижня він оголосив про плани прийняти майбутній чіп Віра Рубін, який включає 88-ядерний процесор та графічний процесор на основі архітектури Рубіна нового покоління. Відкритий розкритий План спільно з новиною про те, що він підніме до 100 мільярдів доларів від Nvidia для фінансування будівельних проектів Центру обробки даних.
Минулого місяця головний виконавчий директор NVIDIA Дженсен Хуанг заявлений Ця будівля 1 гігават інфраструктури AI коштує від 50 мільярдів до 60 мільярдів доларів. Він сказав, що апаратне забезпечення для виробника чіпів припадає на понад половину цієї суми.
На додаток до п'яти центрів обробки даних, оголошених сьогодні, OpenAI може побудувати 600-мегаватський майданчик біля його кампусу Ебілен. Об'єкти матимуть комбіновану потужність понад 5,5 гігаваттів. OpenAI очікує, що проекти створить понад 25 000 робочих місць на місці та десятки тисяч більше по всій країні.
Зображення: OpenAI
Підтримуйте нашу місію, щоб зберегти вміст відкритим та безкоштовним, займаючись спільнотою TheCube. Приєднуйтесь до мережі довіри випускників Thecubeде лідери технологій з'єднуються, діляться інтелектом та створюють можливості.
15 м+ глядачі відеоПотужність розмов через ШІ, Хмару, кібербезпеку та багато іншого
11,4k+ випускники -Підключіться з більш ніж 11 400 технологічними та бізнес-лідерами, що формують майбутнє через унікальну довірену мережу.
Про кремніючі медіа
Siliconangle Media-визнаний лідер в галузі інновацій цифрових медіа, об'єднання проривних технологій, стратегічних поглядів та залучення аудиторії в реальному часі. Як материнська компанія Siliconangle, TheCube Network, TheCube Research, Cube365, Thecube AI та TheCube Superstudios – з флагманськими місцями у Силіконовій долині та нью -йоркській фондовій біржі – Siliconangle Media працює на перехресті медіа, технологій та AI.
Засновані технічними візіонерами Джоном Фур'єром та Дейвом Велланте, Siliconangle Media створили динамічну екосистему провідних галузевих брендів цифрових медіа, які досягають 15+ мільйонів елітних технологій. Наша нова фірма TheCube AI Video Cloud пробиває грунт у взаємодії аудиторії, використовуючи нейронну мережу thecubeai.com, щоб допомогти технологічним компаніям приймати рішення, керовані даними, та залишатися на передньому плані в галузевих розмовах.
Послуги AI потребують багато обчислювальної потужності
Це така велика кількість, що важко уявити. У всьому світі, близько 3 $ (2,2 тн) буде витрачено на центри обробки даних, які підтримують AI між тепер і 2029 року.
Ця оцінка походить від інвестиційного банку Морган Стенлі, який додає, що приблизно половина цієї суми буде продовжуватися на будівництво, а половина на дорогій техніці, що підтримує революцію AI.
Щоб поставити це число в перспективу, це приблизно те, що вся французька економіка вартувала в 2024 році.
Тільки у Великобританії підраховано, що ще 100 центрів обробки даних будуть побудовані протягом наступних кількох років для задоволення попиту на обробку ШІ.
Деякі з них будуть побудовані для Microsoft, яка на початку цього місяця оголосила про інвестиції в 30 мільярдів доларів (22 млрд. Фунтів стерлінгів) у сектор АІ Великобританії.
Тільки що стосується центрів даних AI, що відрізняється від традиційної будівлі, що містить ряди комп'ютерних серверів, які зберігають наші особисті фотографії, облікові записи соціальних медіа та робочі програми, що гуде?
І чи варті вони цього приголомшливого витрат?
Центри обробки даних зростають у розмірах роками. Новий термін, Hyperscale, був придуманий технологічною індустрією для опису сайтів, де потреба в владі стикається з десятками Мегаватт, перш ніж Гігаваттс, на тисячу разів більше, ніж Мегаваттс, прийшов на сцену.
Але AI переплутав цю гру. Більшість моделей AI покладаються на дорогі комп'ютерні мікросхеми від NVIDIA для обробки завдань.
Чіпси Nvidia поставляються у великих шафах, які коштують близько 4 мільйонів доларів кожна. І ці шафи мають ключ до того, чому центри обробки даних AI відрізняються.
Великі мовні моделі (LLM), які навчають програмне забезпечення AI, повинні розбити мову на кожен можливий крихітний елемент значення. Це можливо лише за допомогою мережі комп'ютерів, що працюють в унісон та в надзвичайно близькій близькості.
Чому близькість така важлива? Кожен метр відстані між двома мікросхемами додає наносекунду, мільярд секунди, до часу обробки.
Це може здатися не багато часу, але коли склад, наповнений комп’ютерами, відбиває ці мікроскопічні затримки, що накопичується та розбавляє продуктивність, необхідні для ШІ.
Шафи для обробки AI загрожують разом, щоб усунути цей елемент затримки та створити те, що технічний сектор називає паралельною обробкою, працюючи як один величезний комп'ютер. Все це визначає щільність, магічне слово в конструкційних колах AI.
Щільність усуває вузькі місця обробки, які регулярні центри обробки даних бачать, працюючи з процесорами, що сидять на кілька метрів.
Bloomberg через Getty Images
Google входить до числа гігантських гонок для побудови інфраструктури AI
Однак ці щільні ряди шаф їдять гігават енергії, а тренування LLM виробляє шипи в цьому апетиті до електроенергії.
Ці шипи еквівалентні тисячам будинків, що вмикають і вимикають чайники в унісон кожні кілька секунд.
Цей тип нерегулярного попиту на місцеву сітку повинен бути ретельно керувати.
Даніель Бізо з інженерних консультацій центру обробки даних Інститут періоду, що аналізує центри обробки даних на життя.
“Нормальні центри обробки даних – це стійкий гул на задньому плані порівняно з попитом, який навантаження AI робить на мережі”.
Так само, як ті синхронізовані чайники Раптові сплески AI представляють те, що містер Бізо називає проблемою синглура.
“Сингулярне навантаження в такому масштабі нечувана, – каже містер Бізо, – це такий екстремальний інженерний виклик, це як програма” Аполлон “.
Оператори центрів обробки даних по -різному об'єднують енергетичну проблему.
Виступаючи перед BBC на початку цього місяця, генеральний директор Nvidia Дженсен Хуанг заявив, що у Великобританії в короткостроковій перспективі він сподівався, що більше газових турбін може бути використаний “поза мережею, щоб ми не обтяжували людей на сітку”.
Він сказав, що сам AI буде розробити кращі газові турбіни, сонячні батареї, вітрогенератори та енергію синтезу для виробництва більш економічно ефективної стійкої енергії.
Microsoft інвестує мільярди доларів в енергетичні проекти, включаючи угоду з енергією сузір'я, яка побачить ядерну енергію, вироблену знову на острові Три милі.
Google, що належить Alphabet, також інвестує в ядерну енергію як частину стратегії роботи на енергії без вуглецю до 2030 року.
Тим часом веб -сервіси Amazon (AWS), який є частиною роздрібного гіганта Amazon, каже, що це вже найбільший корпоративний покупець відновлюваної енергії у світі.
Bloomberg через Getty Images
Інвестиції з Microsoft побачать, що ядерна енергетика перезапускається на острові Три милі
Промисловість центрів обробки даних гостро усвідомлює, що законодавці стежать за недоліками фабрики AI з їх інтенсивним використанням енергії, що має потенційний вплив на місцеву інфраструктуру та навколишнє середовище.
Один із таких впливів на навколишнє середовище включає здоровенну подачу води для охолодження стружок.
У штаті США, штат Вірджинія, проживає розширюване населення центрів обробки даних, які зберігають технологічні гіганти, такі як Amazon та Google у бізнесі, розглядається законопроект про затвердження нових сайтів до показників споживання води.
Тим часом запропонована фабрика AI на півночі Лінкольншира у Великобританії зіткнулася з запереченнями з Англіанської води, яка відповідає за те, щоб тримати крани в районі запропонованої ділянки.
Англійська вода вказує, що не зобов’язана постачати воду для неоместичного використання і пропонує перероблену воду з завершальної стадії очищення стоків як теплоносія, а не питної води.
Враховуючи практичні проблеми та величезні витрати, з якими стикаються центри даних AI, чи справді рух справді одна велика бульбашка?
Один спікер на останній конференції центрів обробки даних створив термін “bragawatts”, щоб описати, як галузь розповідає про масштаби запропонованих сайтів AI.
Zahl Limbuwala – спеціаліст з центрів обробки даних компанії Tech Investment Advisors DTCP. Він визнає великі питання щодо майбутнього витрат на дані AI.
“Нинішня траєкторія дуже важко повірити. Безумовно, було багато хвастощів. Але інвестиції повинні доставити прибуток, інакше ринок виправлять себе”.
Маючи на увазі ці застереження, він все ще вважає, що AI заслуговує на особливе місце в інвестиційному плані. “AI матиме більший вплив, ніж попередні технології, включаючи Інтернет. Отже, можливо, нам знадобляться всі ці гігаватти”.
Він зазначає, що вихваляються, AI центри обробки даних ” – це нерухомість технологічного світу”. Спекулятивні технологічні бульбашки, такі як Dotcom Boom 1990 -х, не вистачало цегли та мінометної основи. Центри даних AI дуже тверді. Але бум витрат за ними не може тривати вічно.
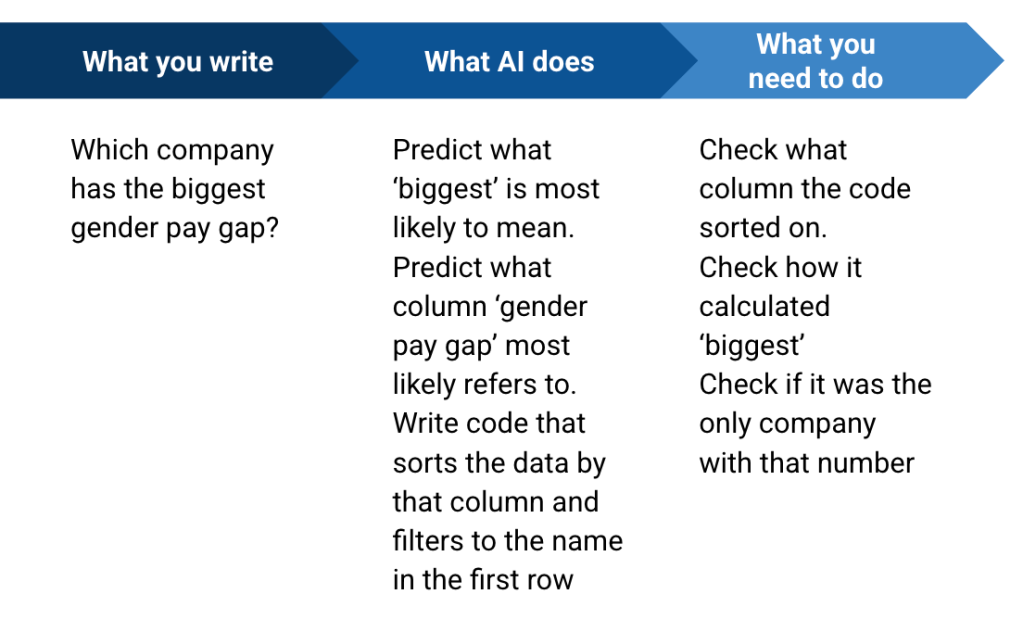
У попередньому дописі я дослідив, як AI виконував завдання з аналізу даних – і важливість розуміння коду, який він використовував. Якщо ви робити Зрозумійте код, ось кілька порад щодо використання великих мовних моделей (LLM) для аналізу – та вирішення ризиків цього.
Почніть з завантаження набору даних – в ідеалі у форматі CSV
Для того, щоб провести аналіз даних за допомогою Genai Tools, вам потрібно завантажити набір даних. Це Найкраще, якщо цей набір даних є у форматі CSV а не інші формати електронних таблиць, такі як XLSX або ODS. Для цього є кілька причин: по -перше, CSV буде меншим, що робить менш імовірним, що ви потрапляєте в межі інструменту; По -друге, CSV може мати лише один аркуш даних, гарантуючи, що ви знаєте, на якому аркуші дивиться інструмент AI.
Щоб перетворити файл XLSX або ODS як CSV, відкрийте файл у програмному забезпеченні електронних таблиць (Excel або Google аркуші), перейдіть на аркуш із потрібними даними та скористайтеся Файл> Зберегти як… меню, щоб зберегти цей аркуш у форматі CSV. Це, мабуть, попередить вас, що ви втратите дані в інших аркушах – це добре, ви хочете лише один аркуш.
Розглянемо модель
Кожна платформа Genai має мовну модель за замовчуванням, яку вона використовує, але це може бути не найкращим для аналізу.
Наприклад, Gemini Google, наприклад, за замовчуванням до 2,5 спалаху на даний момент, але 2.5 Pro описується як “міркування математики та коду” (змініть модель, натиснувши на її ім'я у верхньому правому куті). Якщо ви платите за Pro -обліковий запис, у вас також є інші варіанти моделі.
Посібник Клода щодо вибору моделі та кулінарної книги OpenAI може допомогти пояснити відмінності між моделями. (GPT-5 Ускладнює речі, вибравши для вас модель, що робить її життєво важливою, щоб ви створили підказку, яка спрямовує її на відповідний).
Йдеться не лише про вибір моделі для її потужності – менш потужна модель все ще може генерувати робочий код, часто буде швидшим і, безумовно, матиме менший вплив на навколишнє середовище. Спробуйте різні моделі, щоб побачити, який з них достатньо хороший для ваших цілей (Flash Gemini 2.5 – це, наприклад, для більшості аналізу).
Назвіть стовпці та функції у ваших підказках
Щоб зменшити ризик “непорозуміння” вас, будьте конкретні щодо стовпців та функцій
Модельна модель Genai працює, визначаючи найбільше ймовірний Значення ваших слів, тому завжди є ризик, що це помилиться.
Одна проста практика зменшення цього ризику – це Назвіть стовпці що ви хочете, щоб він користувався.
Наприклад, замість оперативного типу “Count the total fires“Ви б написали”Use the Incidents column to calculate the total number of fires“.
Те саме стосується розрахунків. Будь -який запит на обчислення буде перекладено на (найбільш ймовірний) Python або JavaScript функціонування. Тож, коли ви просите “середню” або “загальну”, подумайте, що ви насправді маєте на увазі в практичному плані. Ви хочете, щоб він використовував медіану чи середню функцію? Ви хочете, щоб він використовував функцію суми чи рахував?
Чіткіший підказка скаже щось на кшталт “calculate the median value for the column PatientTotal”Або "use a mean function to calculate an average value for the column".
Для деяких розрахунків ви можете розбити його на серію кроки. Ось приклад підказки, який намагається бути максимально явним щодо того, що він хоче, щоб AI робив, коли він генерує код:
Here is data on the gender pay gap for over 10,000 companies. I want you to calculate how many companies there are in Birmingham. To do this you need to look at two columns: Address and Postcode. In the Postcode column look for postcodes that start with B, followed by a digit (examples include B9 or B45). Exclude postcodes that start with a B, followed by a letter, (examples include BL2 or BB22). In the Address column only count addresses where Birmingham appears either at the very end of the address, or before a comma or a word like 'England' or 'UK'. If an address contains 'Birmingham Road' or 'Birmingham Business Park' this does not necessarily mean it is in Birmingham, unless the address also contains Birmingham towards the end of the address, as detailed. Adjust the code so that either a postcode match OR an address match is counted - it doesn't have to meet both criteria
Включіть контекст, запитуючи більше однієї фігури або рядка
Працюючи з даними безпосередньо, фігури, що стосуються вашої уваги, можуть забезпечити корисні підказки, щоб уникнути помилок. Ви можете повторити це у своєму аналізі, уникаючи підказок, які вимагають однієї фігури чи ряду. Наприклад:
Замість того Попросіть “Топ -10” та “Нижня 10”. Іноді є більше однієї організації з однаковою фігурою, а іноді найбільший – це безглуздий чужий з статистичних причин. Іноді найбільші негативні числа є “найбільшими”.
Замість того, щоб просити одного середнього, Попросіть різні типи середньогонаприклад, середня, медіана та режим.
Попросіть статистичний підсумок З стовпців, які вас цікавить. Підсумок для чисельного стовпця зазвичай показує розподіл значень (середнє, медіана, квартали, максимум та хв, стандартне відхилення). Ви також можете попросити типу даних (ів) поля, які вас цікавить, кількість записів та порожніх комірок,
Використовуйте методи швидкого проектування, щоб уникнути довірливості та інших ризиків
Моделі AI прагнуть догодити, тому, як правило, не зможуть вам кинути виклик, коли ваше запитання буде хибним або не вистачає деталей. Натомість вони зроблять те, що можуть, із наданою інформацією, збільшуючи ризик неправильних відповідей.
Ось кілька методів проектування, які слід використовувати, коли просять аналіз даних та підказки шаблонів до адаптації:
Мета-провідний: Після того, як ви спроектували власну підказку, подивіться, що б запропонував AI, і якщо ви зможете адаптувати свою на основі власної спроби. Спробуйте: I am a data journalist looking to perform analysis on this data. Suggest three advanced prompts which employ prompt design techniques and could be used to ask an LLM to answer this question, and explain why each might work well (and why they might not):
Роль, що спонукає: «Роль», яку ви надаєте моделі AI, може відігравати важливу роль у спонуканні її до менш сифофантичних та більш критичних помічників. Наприклад: You are an experienced, sceptical and cautious data analyst. You are always conscious of the blind spots and mistakes made by data journalists when analysing data sets. Use code to perform analysis on the attached dataset which answers the following question, but also highlight any potential mistakes or blind spots to consider:
N-постріл, що спонукає: Це передбачає надання певної кількості (“n”) прикладів (“постріли”). Це можуть бути прикладами попередніх історій з використанням подібних даних, або це можуть бути прикладами методів, що використовуються раніше. Наприклад: Below I've pasted some examples of angles drawn from this dataset in the past. Identify what calculations or code might have been used to arrive at those numbers [PASTE EXCERPTS FROM PREVIOUS STORIES]:
Рекурсивне спонукання: Це просто слідкує за відповідями. Як подальше спостереження за наданим аналізом, ви можете підказати: Review the code you used to arrive at that answer. Identify any potential blind spots or problems, and list three alternative ways to answer the question.
Негативне спонукання: Спробуйте це: Do not make any assumptions about the question that have not been explicitly stated, and do not proceed until you have clarified any ambiguity or assumptions embedded in the question.
Структурований вихідний вихід передбачає просити його забезпечити його вихід у певному форматі даних: Provide the code used as a downloadable .py file. Provide the results in [CSV/JSON/Markdown table] format
Ланцюг думки та ганчірки заслуговують на особливу увагу …
Відобразити метод за допомогою Ланцюг думки (Ліжечко)
Ланцюг думки (ліжечко) Захисник передбачає встановлення низки кроків, які слід дотримуватися, та/або просити модель пояснити кроки, які потрібно було досягти. Це може бути дуже корисним для аналізу, оскільки значним фактором точності будь -якого аналізу є метод, який використовується.
Ось приклад оперативного використання COT для зменшення ризиків, що беруть участь у аналізі даних:
First, identify any aspects of the question which are ambiguous, or could be better expressed, and seek clarification on those. Once the question is clear enough, identify which columns are relevant to the question. Then outline three potential strategies for answering the question through code. Review the strategies and pick the one which is most rigorous, provides the most context, and is least likely to contain blind spots or errors. Explain your thinking.
Перевага COT полягає в тому, що вона підштовхує вас до думки про те, які кроки важливі в процесі аналізу, оскільки COT означає, що ви повинні донести ці кроки.
У випадку аналізу даних ми можемо визначити, що першим кроком є саме питання, але ми можемо повернутися ще далі до вибору чи розуміння використання набору даних.
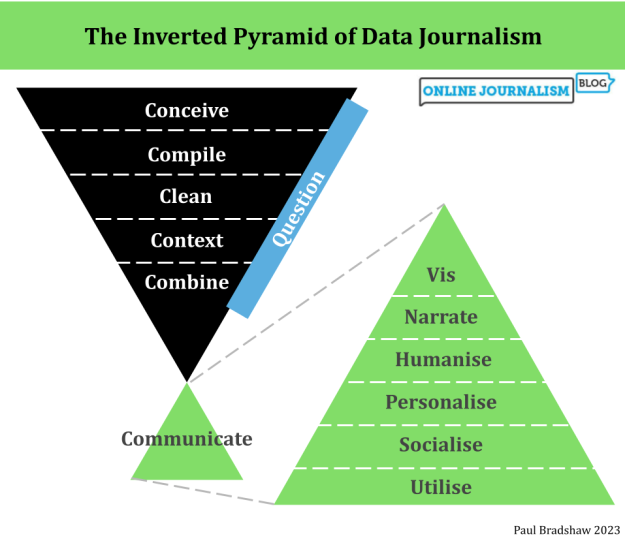
З Перевернута піраміда журналістики даних Тут надає корисну рамку, оскільки це робить саме це: викладіть кроки, які часто включає проект журналістики даних. Важливим для висвітлення тут є те, що етап “питання” проходить у всіх інших. Пост із оновленою моделлю детальніше окреслює ці питання, і вони можуть бути включені в підказку.
Насправді ви можете включити цю публікацію або витягувати з нього, як додатковий контекст до вашого оперативного підказки – техніка, що називається Ганчірка…
“Зазвичай” аналіз з іншими документами (ганчірка)
Пошук розширеного покоління (RAG) – один з найпотужніших способів покращення відповідей моделей AI. Він передбачає “збільшення” вашої підказки з корисною або важливою інформацією, як правило, у вигляді витягів або вкладень.
Прикріплення самого набору даних – це форма ганчірки – але ви також можете приєднати інший матеріал, який вкладає набір даних у контекст. Приклади включають:
Ось приклад реакції шаблону, який може використовувати ганчірку. Однією з переваг такого підказки шаблону є те, що він нагадує вам шукати необхідні документи:
As well as the data itself I have attached a document explaining what each column means, and a methodology. Below is an extract on the different questions that need to be asked at every stage of the data analysis process.
Check assumptions built in to the question and challenge them, and add context that is relevant to the questions being asked. Here is the extract: [PASTE EXTRACT AND ATTACH DOCUMENTS]
Ще одне застосування ганчірки полягає в тому, щоб протиставити набір даних із претензіями щодо цього. Наприклад:
You are a sceptical data journalist that works for a factchecking organisation. You are used to powerful people misrepresenting data, putting a positive spin on it, or cherry-picking one facet of the data while ignoring less positive facets. You are checking the attached public statement made by a powerful person about a dataset. Compare this statement to the data and identify any claims that do not appear to be supported by the data, or any evidence of cherry picking. Identify any aspects of the data or other documents attached that are not mentioned in the statement but which might be newsworthy because they highlight potential problems, low-ranking performers, change, missing data, or outliers.
Обмеження повідомлень та обмеження розмови можуть перервати аналіз
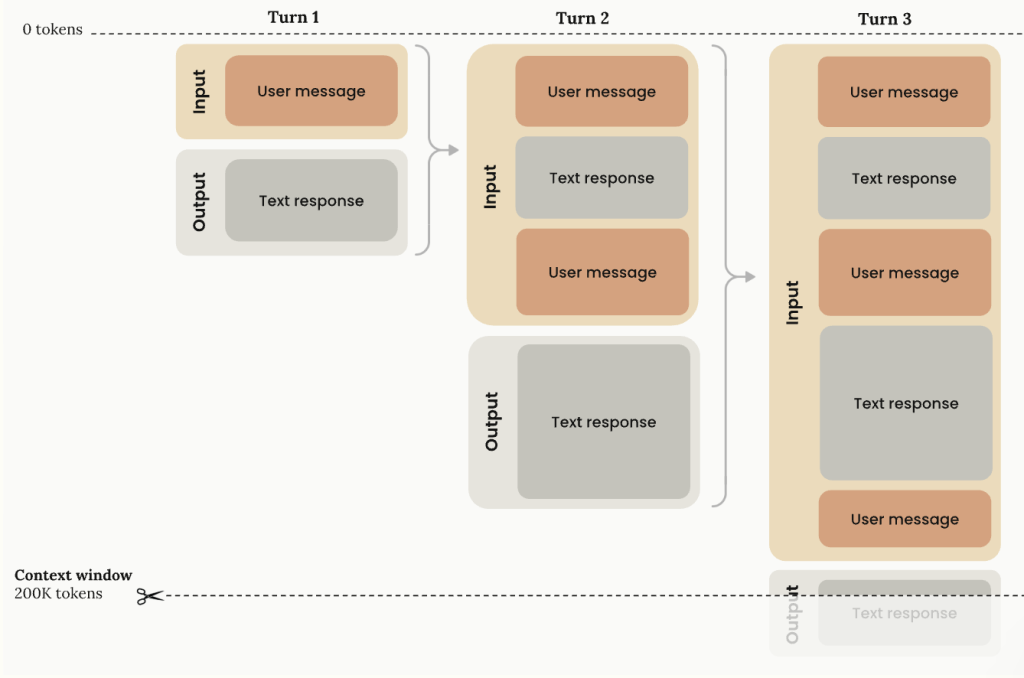
Діаграма Клода, що ілюструє “стандартне” вікно контексту, де модель не використовує розширене мислення
Пам'ятайте, що інструменти Genai мають обмеження щодо кількості пам'яті – “Контекстне вікно' – Вони можуть проводитись у розмові, і в якийсь момент вам, можливо, доведеться розпочати нову розмову, щоб продовжити аналіз.
У моєму тестуванні Клод, зокрема, прагнув досягти цих меж раніше, оскільки він також, як правило, використовував розширене мислення та надавши більш детальні відповіді на підказки, враховуючи аспекти, які не згадувались у цьому питанні.
Є кілька стратегій, які слід врахувати, якщо ви досягаєте цих меж:
Зменшити тривалість відповідей через негативне спонукання. Наприклад, ви можете сказати «in more than 300 words“Або”do not do any more than is asked“
Попросіть його підсумувати розмову чи код досі (і вставте його на початку будь -якої нової розмови). Копіювання підсумків дозволить вам «експортувати» якусь пам’ять з однієї розмови в іншу. Вам потрібно буде зробити це, перш ніж досягти будь -яких обмежень, тому встановіть рутину зробити це після певної кількості взаємодій (наприклад, після кожної п’яти підказок у Клоді, або десять у Чатгпті, залежно від складності підказок та відповідей).
Плануйте заздалегідь і розбийте аналіз на різні частини. Замість того, щоб намагатися завершити аналіз в одній розмові, розбийте його на різні завдання та використовуйте різну розмову для кожного. Це може створити більше природних точок розриву та зменшити потребу в експорті відповідей між розмовами.
Ви можетеПопросіть оцінку жетонів, які використовувались досі, але в своєму тестуванні я виявив, що переробляв той самий запит у тому ж моменті в розмові, що породжував дуже різні результати, і жоден з них не близький до реальності.
Завжди експортуйте версію, щоб перевірити
Оскільки завжди корисно бачити дані в контексті, попросіть завантажити результати аналізу даних. Якщо це стосувалося, наприклад, сортування, попросіть його завантажувати CSV від сортованих даних, щоб ви могли їх побачити повністю. Якщо було залучено очищення або фільтрування, завантажена версія дозволить вам порівняти її з оригіналом.
Попросіть це кинути вам виклик
Кінцева порада – загартувати зміщення Sycophancy AI за допомогою змагальний спонукання Визначити потенційні сліпі плями або припущення у вашому підході до аналізу. Наприклад:
Act as a sceptical editor and ask critical questions about the prompts and methods used throughout this interaction. Identify potential blind spots, assumptions, potential ambiguity, or other problems with the approach, and other criticisms that might be made.
Ви використовували AI для аналізу даних та маєте поради? Опублікуйте їх у коментарях нижче або прокоментуйте LinkedIn.
*Моделі, що використовуються в тестах, були такими: Chatgpt GPT-4O, Claude Sonnet 4, Gemini 2.5 Flash, Copilot GPT-4-Turbo.