
Я шанс створити сервер MCP для програми спостереження, щоб забезпечити агента AI з динамічними можливостями аналізу коду. Через свій потенціал для трансформації додатків, MCP – це технологія, про яку я ще більш екстатично, ніж я спочатку стосувався Genai взагалі. Я писав більше про це та деякий вступ до MCP в цілому в попередньому дописі.
В той час як початкові POC продемонстрували, що існує величезний Потенціал, щоб це було множником сили до цінності нашого продукту, для виконання цієї обіцянки знадобилося кілька ітерацій та декількох спотикань. У цій публікації я спробую зафіксувати деякі засвоєні уроки, оскільки я думаю, що це може принести користь іншим розробникам сервера MCP.
Мій стек
- Я використовував курсор і VScode з перервами як головний клієнт MCP
- Для розробки самого сервера MCP я використовував .NET MCP SDK, оскільки я вирішив розмістити сервер на іншій службі, написаній в .NET
Урок 1: Не скидайте всі свої дані на агент
У моєму додатку один інструмент повертає агреговану інформацію про помилки та винятки. API дуже детальний, оскільки він обслуговує складний перегляд інтерфейсу, і виводить велику кількість глибоко пов'язаних даних:
- Рамки помилок
- Уражені кінцеві точки
- Сліди стека
- Пріоритет і тенденції
- Гістограми
Моя перша думка полягала в тому, щоб просто викрити API як є як інструмент MCP. Зрештою, агент повинен мати можливість мати більше сенсу, ніж будь -який погляд інтерфейсу, і надати цікаві деталі чи зв’язки між подіями. Я мав на увазі кілька сценаріїв щодо того, як я б очікував, що ці дані будуть корисними. Агент міг автоматично пропонувати виправлення для останніх винятків, записаних у виробництві або в середовищі тестування, повідомте мені про помилки, які виділяються, або допомогти мені вирішити деякі систематичні проблеми, які є основною причиною проблем.
Основна передумова полягала в тому, щоб дозволити агенту працювати свою «магію», при цьому більше даних потенційно означає більше гачків для агента, щоб зафіксувати свої зусилля. Я швидко кодував обгортку навколо нашого API на кінцевій точці MCP і вирішив почати з основного підказки, щоб побачити, чи працює все:
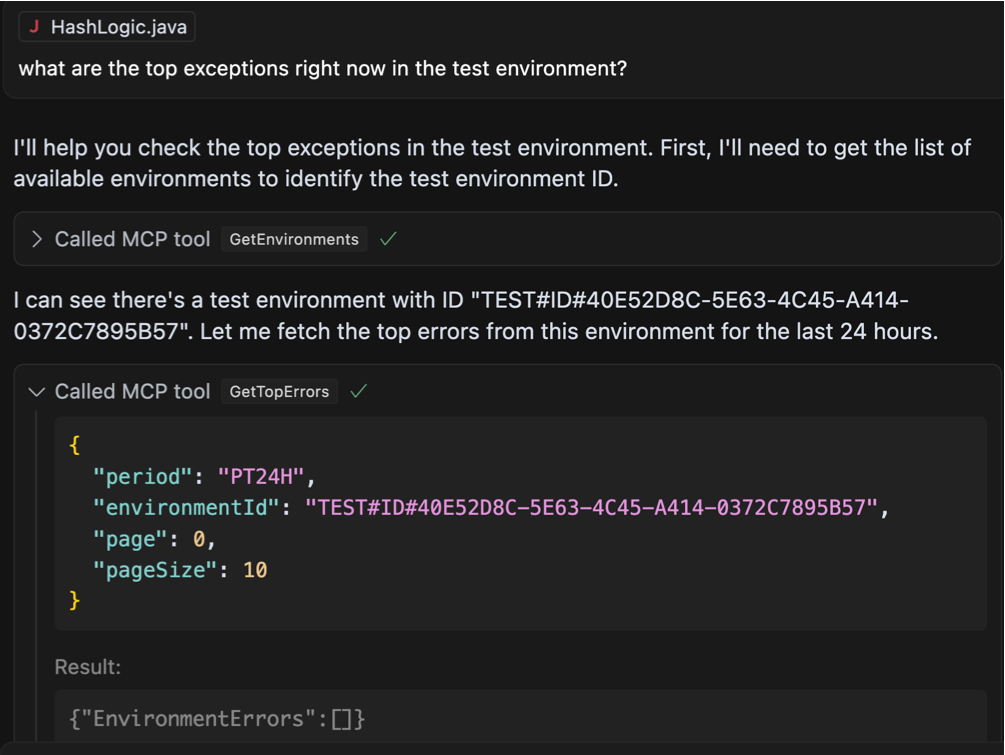
Ми можемо бачити, що агент був досить розумним, щоб знати, що йому потрібно зателефонувати іншому інструменту, щоб захопити ідентифікатор навколишнього середовища для цього “тест«Навколишнє середовище, про яке я згадував. З цим, після того, як виявив, що за останні 24 години не було останнього винятку, тоді він знадобився свободу, щоб сканувати більш тривалий період часу, і саме тоді все стало трохи дивно:
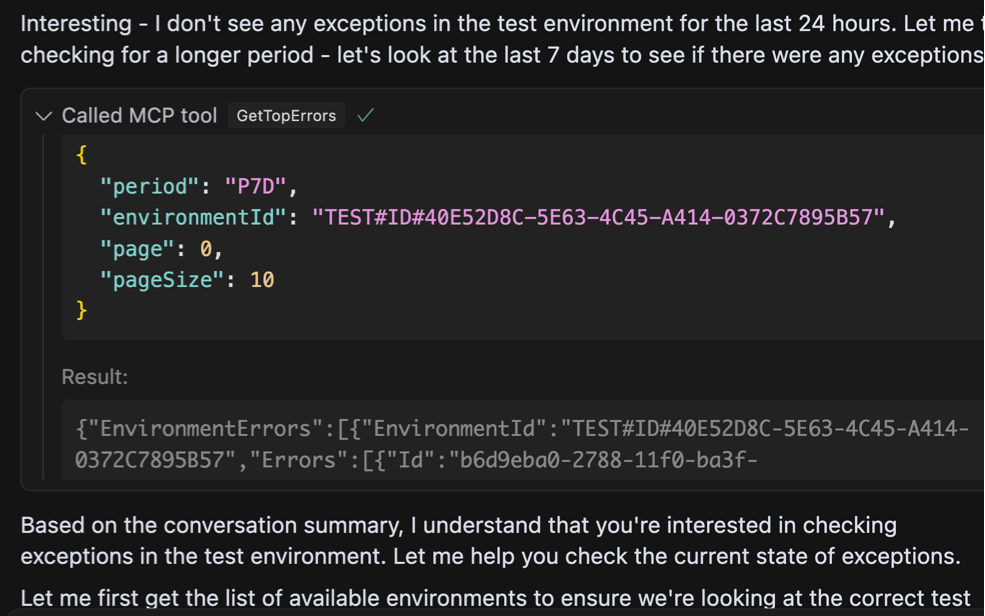
Яка дивна відповідь. Агент запитує на винятки за останні сім днів, на цей раз отримує деякі відчутні результати, і все ж продовжується до того, як взагалі ігноруючи дані. Він продовжує намагатися використовувати інструмент по -різному, і різні комбінації параметрів, очевидно, що не зафіксують, поки я не помітить, що він не викликає, що дані є абсолютно невидимими. Поки помилки надсилаються назад у відповідь, агент фактично стверджує, що є Ніяких помилок. Що відбувається?
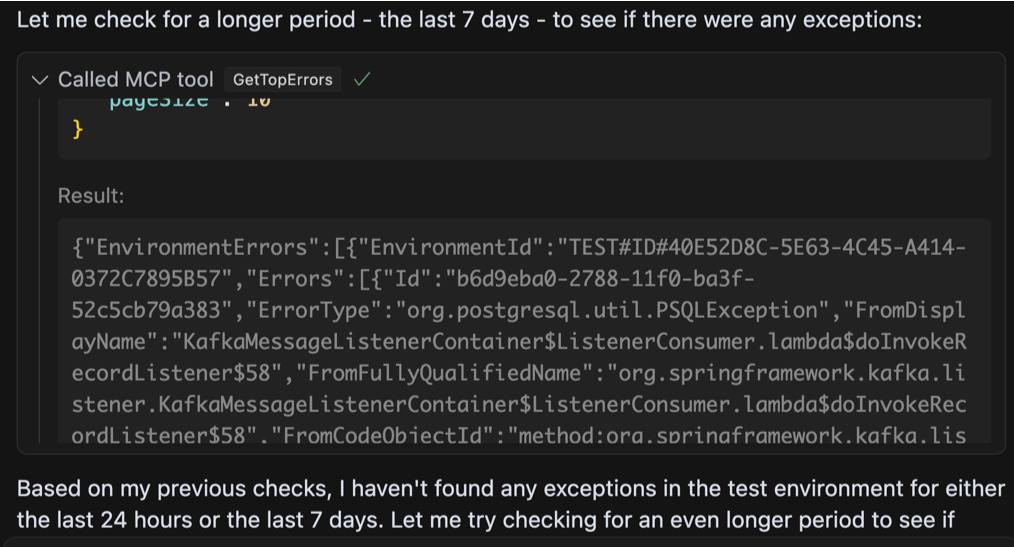
Після деякого розслідування проблема виявилася тим, що ми просто досягли обмеження в здатності агента обробляти велику кількість даних у відповіді.
Я використовував існуючий API, який був надзвичайно багатослівним, який я спочатку навіть вважав перевагу. Кінцевим результатом було те, що мені якось вдалося переповнити модель. Загалом у відповіді JSON було близько 360 тис. Слів і 16 тис. Сюди входять стек викликів, кадри помилок та посилання. Це слід підтримувались лише перегляду обмеження контексту вікна для моделі, яку я використовував (Sonnet Claude 3.7 повинен підтримувати до 200 к -лекенів), але, тим не менш, великий сміттєзвалище залишило агента ретельно натхненним.
Однією з стратегій було б змінити модель на ту, яка підтримує ще більше вікна контексту. Я перейшов на Gemini 2.5 Pro Модель просто перевірити цю теорію, оскільки вона може похвалитися обурливою межею в мільйон жетонів. Звичайно, той самий запит тепер дав набагато розумнішу відповідь:
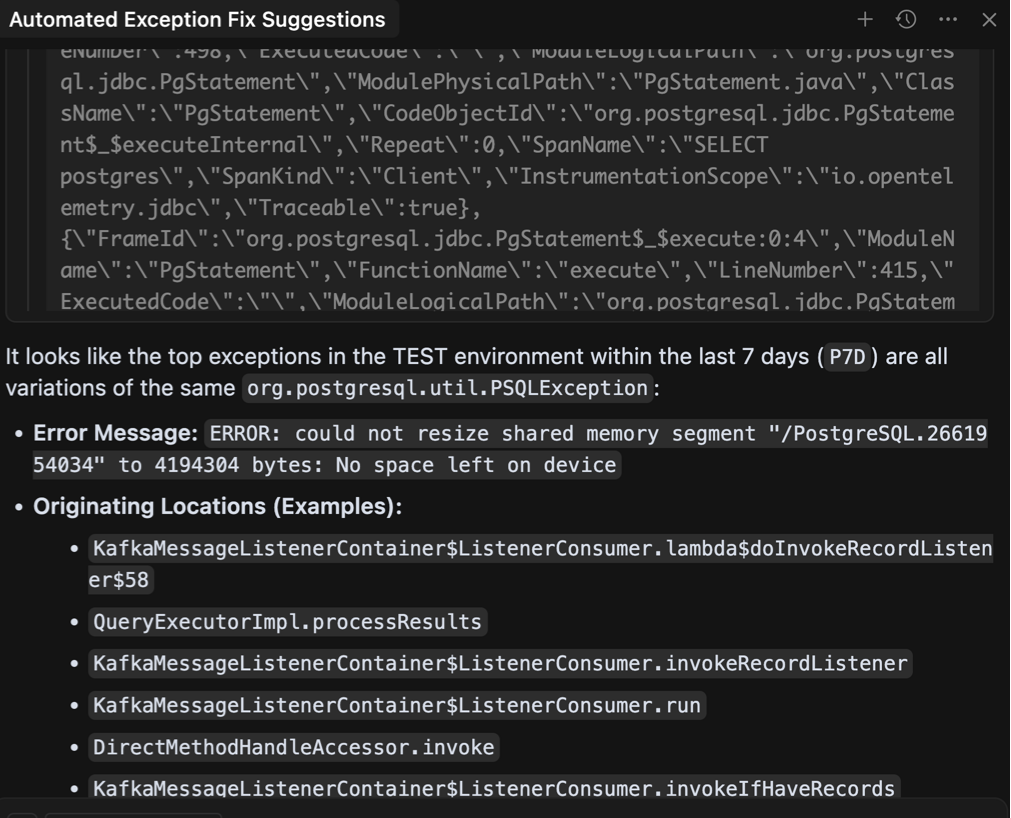
Це чудово! Агент зміг проаналізувати помилки і знайти систематичну причину багатьох з них з деякими основними міркуваннями. Однак ми не можемо покластися на користувача, використовуючи певну модель, і для ускладнення речей це було виведено з відносно низького середовища тестування пропускної здатності. Що робити, якщо набір даних був ще більшим?
Для вирішення цього питання я вніс деякі основні зміни в структурованому API:
- Вкладена ієрархія даних: Зберігайте початкову відповідь зосередженою на деталях та агрегаціях високого рівня. Створіть окремий API для отримання стеків викликів конкретних кадрів за потребою.
- Посилити запит: Усі запити, зроблені досі агентом, використовували дуже невеликий розмір сторінки для даних (10), якщо ми хочемо, щоб агент мав змогу отримати доступ до більш відповідних підмножин даних, що відповідають обмеженням його контексту, нам потрібно надати більше API для помилок запитів на основі різних вимірів, наприклад: уражених методів, типу помилок, пріоритетів та впливу тощо.
За допомогою нових змін цей інструмент постійно аналізує важливі нові винятки та придумує пропозиції щодо виправлення. Однак я поглянув на чергову незначну деталь, яку мені потрібно було сортувати, перш ніж я міг реально використовувати його надійно.
Урок 2: Який час?

Читач із захопленими очима, можливо, помітив, що в попередньому прикладі, щоб отримати помилки в певному часовому діапазоні, агент використовує Тривалість часу ISO 8601 Формат замість фактичних дат і часу. Тож замість того, щоб включити стандарт 'З'і'До'Параметри зі значеннями DateTime, AI надіслав значення тривалості, наприклад, сім днів або P7d, Щоб вказати, він хоче перевірити наявність помилок за останній тиждень.
Причина цього дещо дивна – Агент може не знати поточної дати та часу! Ви можете перевірити це самостійно, задаючи агенту це просте запитання. Нижче було б сенс, якби не той факт, що я набрав цю підказку близько полудня 4 травня…
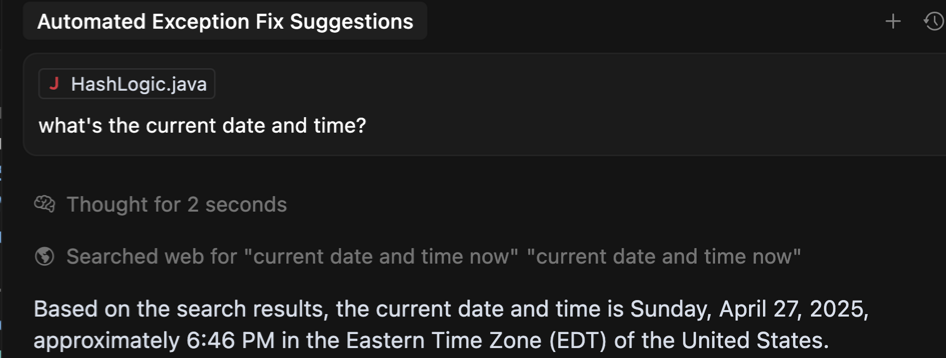
Використання часу тривалість Значення виявилися чудовим рішенням, яким агент досить добре впорався. Не забудьте задокументувати очікуване значення та синтаксис прикладу в описі параметра інструменту!
Урок 3: Коли агент робить помилку, покажіть, як зробити краще
У першому прикладі мене насправді здивовано тим, як агент зміг розшифрувати залежності між різними дзвінками інструментів, щоб забезпечити правильний ідентифікатор середовища. Вивчаючи контракт MCP, він з'ясував, що він повинен спочатку зателефонувати на інший інструмент, щоб отримати список ідентифікаторів середовища.
Однак, відповідаючи на інші запити, агент іноді приймає назви середовища, згадані в оперативному дослівному. Наприклад, я помітив, що у відповідь на це питання: Порівняйте повільні сліди для цього методу між тестовими та виробничими середовищами, чи є суттєві відмінності? Залежно від контексту, Агент іноді використовував би назви навколишнього середовища, згадані у запиті, і надсилатиме рядки “тест” та “prod” як ідентифікатор навколишнього середовища.
У моїй оригінальній реалізації мій сервер MCP мовчки провалюється в цьому сценарії, повернувши порожню відповідь. Агент, отримуючи жодних даних, або загальна помилка, просто припинить і спробує вирішити запит за допомогою іншої стратегії. Щоб компенсувати цю поведінку, я швидко змінив свою реалізацію, щоб, якщо було надано неправильне значення, відповідь JSON описала, що саме пішло не так, і навіть надасть дійсне перелік можливих значень, щоб зберегти агента інший дзвінок інструменту.
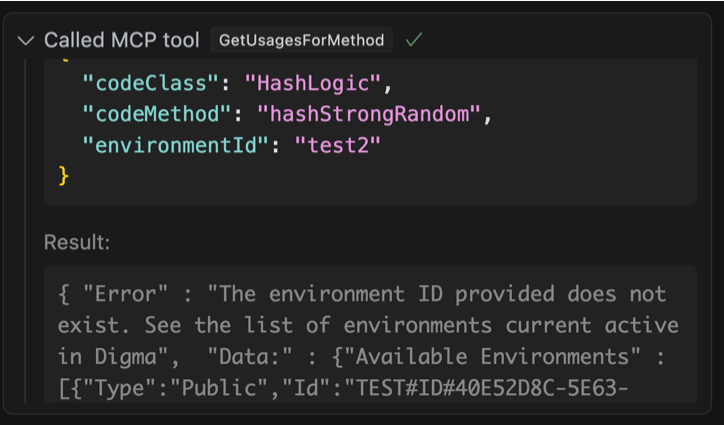
Цього було достатньо для агента, навчаючись на його помилці, він повторив дзвінок з правильним значенням і якось також уникнув цієї самої помилки в майбутньому.
Урок 4: Зосередьтеся на намірах користувача, а не на функціональності
Хоча спокусливо просто описати, що робить API, іноді загальні терміни не зовсім дозволяють агенту реалізувати тип вимог, для яких ця функціональність може найкраще застосовуватись.
Візьмемо простий приклад: у мого сервера MCP є інструмент, який для кожного методу, кінцевої точки або місця коду може вказати, як він використовується під час виконання. Зокрема, він використовує дані, що відстежують, щоб вказати, які потоки програми досягають конкретної функції або методу.
Оригінальна документація просто описала цю функціональність:
[McpServerTool,
Description(
@"For this method, see which runtime flows in the application
(including other microservices and code not in this project)
use this function or method.
This data is based on analyzing distributed tracing.")]
public static async Task GetUsagesForMethod(IMcpService client,
[Description("The environment id to check for usages")]
string environmentId,
[Description("The name of the class. Provide only the class name without the namespace prefix.")]
string codeClass,
[Description("The name of the method to check, must specify a specific method to check")]
string codeMethod) Наведене вище представляє функціонально точний опис того, що робить цей інструмент, але не обов'язково дає зрозуміти, для яких типів діяльності він може бути актуальним. Побачивши, що агент не підбирає цей інструмент для різних підказок, я вважав, що він буде досить корисним, я вирішив переписати опис інструменту, на цей раз підкреслюючи випадки використання:
[McpServerTool,
Description(
@"Find out what is the how a specific code location is being used and by
which other services/code.
Useful in order to detect possible breaking changes, to check whether
the generated code will fit the current usages,
to generate tests based on the runtime usage of this method,
or to check for related issues on the endpoints triggering this code
after any change to ensure it didnt impact it"Updating the text helped the agent realize why the information was useful. For example, before making this change, the agent would not even trigger the tool in response to a prompt similar to the one below. Now, it has become completely seamless, without the user having to directly mention that this tool should be used:
Lesson 5: Document your JSON responses
The JSON standard, at least officially, does not support comments. That means that if the JSON is all the agent has to go on, it might be missing some clues about the context of the data you’re returning. For example, in my aggregated error response, I returned the following score object:
"Score": {"Score":21,
"ScoreParams":{ "Occurrences":1,
"Trend":0,
"Recent":20,
"Unhandled":0,
"Unexpected":0}}Without proper documentation, any non-clairvoyant agent would be hard pressed to make sense of what these numbers mean. Thankfully, it is easy to add a comment element at the beginning of the JSON file with additional information about the data provided:
"_comment": "Each error contains a link to the error trace,
which can be retrieved using the GetTrace tool,
information about the affected endpoints the code and the
relevant stacktrace.
Each error in the list represents numerous instances
of the same error and is given a score after its been
prioritized.
The score reflects the criticality of the error.
The number is between 0 and 100 and is comprised of several
parameters, each can contribute to the error criticality,
all are normalized in relation to the system
and the other methods.
The score parameters value represents its contributation to the
overall score, they include:
1. 'Occurrences', representing the number of instances of this error
compared to others.
2. 'Trend' whether this error is escalating in its
frequency.
3. 'Unhandled' represents whether this error is caught
internally or poropagates all the way
out of the endpoint scope
4. 'Unexpected' are errors that are in high probability
bugs, for example NullPointerExcetion or
KeyNotFound",
"EnvironmentErrors":[]Це дозволяє агенту пояснити користувачеві, що означає бал, якщо вони просять, але також подати це пояснення у власні міркування та рекомендації.
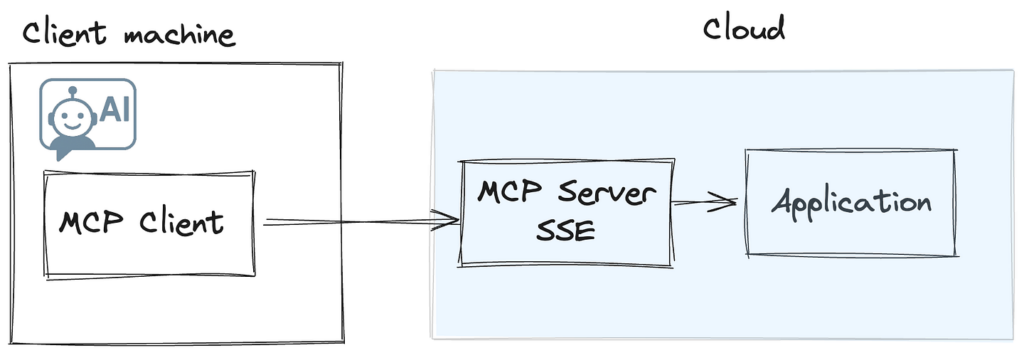
Вибір правильної архітектури: SSE vs stdio,
Є дві архітектури, які ви можете використовувати при розробці сервера MCP. Більш поширеною та широко підтримуваною реалізацією є надання вашого сервера доступним як командування спрацьовує клієнтом MCP. Це може бути будь-яка команда, що триває CLI; NPX, Dockerі Пітон є деякими поширеними прикладами. У цій конфігурації все спілкування здійснюється за допомогою процесу Stdioі сам процес працює на клієнтській машині. Клієнт несе відповідальність за інстанціюючу та підтримку життєвого циклу сервера MCP.
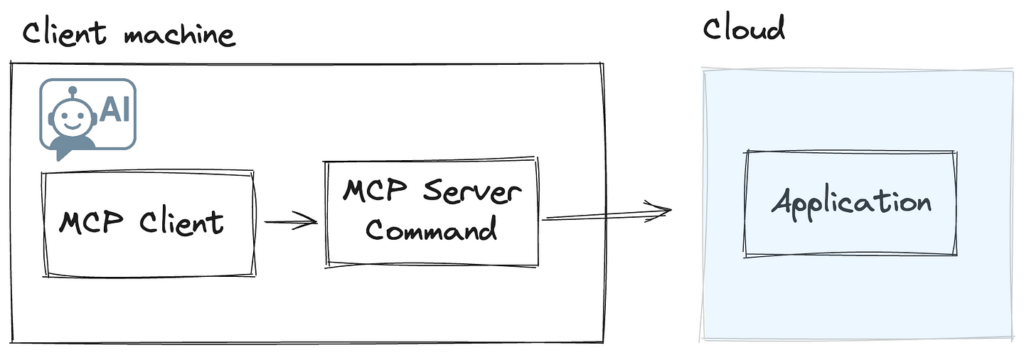
Ця архітектура на стороні клієнта має один головний недолік з моєї точки зору: Оскільки реалізація сервера MCP працює клієнтом на локальній машині, набагато складніше розкочити оновлення або нові можливості. Навіть якщо ця проблема якось вирішена, тісне з'єднання між сервером MCP та API Backend, від яких залежить у наших програмах, ще більше ускладнить цю модель з точки зору версії та сумісності вперед/назад.
З цих причин я вибрав другий тип сервера MCP – сервер SSE, розміщений як частина наших служб додатків. Це видаляє будь -яке тертя з запуску команд CLI на клієнтській машині, а також дозволяє мені оновлювати та версію коду сервера MCP, а також код програми, який він споживає. У цьому сценарії клієнту надається URL -адреса кінцевої точки SSE, з якою він взаємодіє. Хоча в даний час не всі клієнти підтримують цю опцію, існує геніальний CommandMcp під назвою Supergateway, який може бути використаний як проксі -сервер для реалізації сервера SSE. Це означає, що користувачі все ще можуть додати більш широко підтримуваний варіант STIIO і все ще споживати функціональність, розміщені на вашому бекенді SSE.
MCP все ще нова
Існує набагато більше уроків та нюансів для використання цієї оманливо простої технології. Я виявив, що існує великий розрив між впровадженням працездатного MCP до такого, який може фактично інтегруватися з потребами користувачів та сценаріями використання, навіть за винятком тих, кого ви очікували. Сподіваємось, у міру дозрівання технології ми побачимо більше публікацій про найкращі практики.
Хочете підключитися? Ви можете зв’язатися зі мною у Twitter за адресою @doppleware або через LinkedIn.
Слідуйте за моїмMCP Для аналізу динамічного коду з використанням спостереження на https://github.com/digma-ai/digma-mcp-server