

У попередньому дописі я дослідив, як AI виконував завдання з аналізу даних – і важливість розуміння коду, який він використовував. Якщо ви робити Зрозумійте код, ось кілька порад щодо використання великих мовних моделей (LLM) для аналізу – та вирішення ризиків цього.
Почніть з завантаження набору даних – в ідеалі у форматі CSV
Для того, щоб провести аналіз даних за допомогою Genai Tools, вам потрібно завантажити набір даних. Це Найкраще, якщо цей набір даних є у форматі CSV а не інші формати електронних таблиць, такі як XLSX або ODS. Для цього є кілька причин: по -перше, CSV буде меншим, що робить менш імовірним, що ви потрапляєте в межі інструменту; По -друге, CSV може мати лише один аркуш даних, гарантуючи, що ви знаєте, на якому аркуші дивиться інструмент AI.
Щоб перетворити файл XLSX або ODS як CSV, відкрийте файл у програмному забезпеченні електронних таблиць (Excel або Google аркуші), перейдіть на аркуш із потрібними даними та скористайтеся Файл> Зберегти як… меню, щоб зберегти цей аркуш у форматі CSV. Це, мабуть, попередить вас, що ви втратите дані в інших аркушах – це добре, ви хочете лише один аркуш.
Розглянемо модель
Кожна платформа Genai має мовну модель за замовчуванням, яку вона використовує, але це може бути не найкращим для аналізу.
Наприклад, Gemini Google, наприклад, за замовчуванням до 2,5 спалаху на даний момент, але 2.5 Pro описується як “міркування математики та коду” (змініть модель, натиснувши на її ім'я у верхньому правому куті). Якщо ви платите за Pro -обліковий запис, у вас також є інші варіанти моделі.
Посібник Клода щодо вибору моделі та кулінарної книги OpenAI може допомогти пояснити відмінності між моделями. (GPT-5 Ускладнює речі, вибравши для вас модель, що робить її життєво важливою, щоб ви створили підказку, яка спрямовує її на відповідний).
Йдеться не лише про вибір моделі для її потужності – менш потужна модель все ще може генерувати робочий код, часто буде швидшим і, безумовно, матиме менший вплив на навколишнє середовище. Спробуйте різні моделі, щоб побачити, який з них достатньо хороший для ваших цілей (Flash Gemini 2.5 – це, наприклад, для більшості аналізу).
Назвіть стовпці та функції у ваших підказках
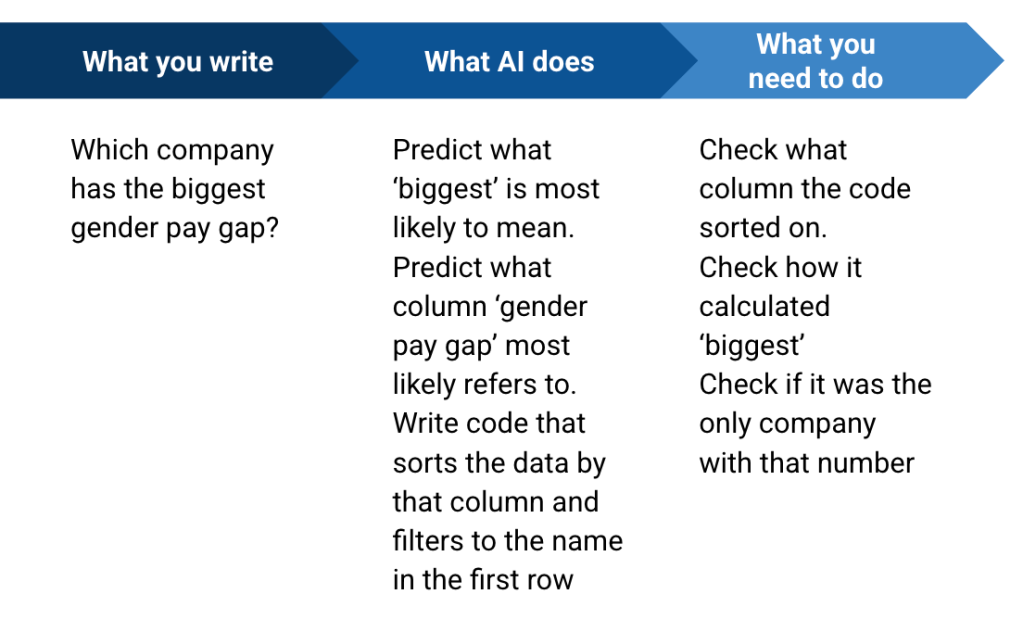
Модельна модель Genai працює, визначаючи найбільше ймовірний Значення ваших слів, тому завжди є ризик, що це помилиться.
Одна проста практика зменшення цього ризику – це Назвіть стовпці що ви хочете, щоб він користувався.
Наприклад, замість оперативного типу “Count the total fires“Ви б написали”Use the Incidents column to calculate the total number of fires“.
Те саме стосується розрахунків. Будь -який запит на обчислення буде перекладено на (найбільш ймовірний) Python або JavaScript функціонування. Тож, коли ви просите “середню” або “загальну”, подумайте, що ви насправді маєте на увазі в практичному плані. Ви хочете, щоб він використовував медіану чи середню функцію? Ви хочете, щоб він використовував функцію суми чи рахував?
Чіткіший підказка скаже щось на кшталт “calculate the median value for the column PatientTotal”Або "use a mean function to calculate an average value for the column".
Для деяких розрахунків ви можете розбити його на серію кроки. Ось приклад підказки, який намагається бути максимально явним щодо того, що він хоче, щоб AI робив, коли він генерує код:
Here is data on the gender pay gap for over 10,000 companies. I want you to calculate how many companies there are in Birmingham. To do this you need to look at two columns: Address and Postcode.
In the Postcode column look for postcodes that start with B, followed by a digit (examples include B9 or B45). Exclude postcodes that start with a B, followed by a letter, (examples include BL2 or BB22).
In the Address column only count addresses where Birmingham appears either at the very end of the address, or before a comma or a word like 'England' or 'UK'. If an address contains 'Birmingham Road' or 'Birmingham Business Park' this does not necessarily mean it is in Birmingham, unless the address also contains Birmingham towards the end of the address, as detailed. Adjust the code so that either a postcode match OR an address match is counted - it doesn't have to meet both criteria
Включіть контекст, запитуючи більше однієї фігури або рядка
Працюючи з даними безпосередньо, фігури, що стосуються вашої уваги, можуть забезпечити корисні підказки, щоб уникнути помилок. Ви можете повторити це у своєму аналізі, уникаючи підказок, які вимагають однієї фігури чи ряду. Наприклад:
- Замість того Попросіть “Топ -10” та “Нижня 10”. Іноді є більше однієї організації з однаковою фігурою, а іноді найбільший – це безглуздий чужий з статистичних причин. Іноді найбільші негативні числа є “найбільшими”.
- Замість того, щоб просити одного середнього, Попросіть різні типи середньогонаприклад, середня, медіана та режим.
- Попросіть статистичний підсумок З стовпців, які вас цікавить. Підсумок для чисельного стовпця зазвичай показує розподіл значень (середнє, медіана, квартали, максимум та хв, стандартне відхилення). Ви також можете попросити типу даних (ів) поля, які вас цікавить, кількість записів та порожніх комірок,
Використовуйте методи швидкого проектування, щоб уникнути довірливості та інших ризиків

Моделі AI прагнуть догодити, тому, як правило, не зможуть вам кинути виклик, коли ваше запитання буде хибним або не вистачає деталей. Натомість вони зроблять те, що можуть, із наданою інформацією, збільшуючи ризик неправильних відповідей.
Ось кілька методів проектування, які слід використовувати, коли просять аналіз даних та підказки шаблонів до адаптації:
- Мета-провідний: Після того, як ви спроектували власну підказку, подивіться, що б запропонував AI, і якщо ви зможете адаптувати свою на основі власної спроби. Спробуйте:
I am a data journalist looking to perform analysis on this data. Suggest three advanced prompts which employ prompt design techniques and could be used to ask an LLM to answer this question, and explain why each might work well (and why they might not): - Роль, що спонукає: «Роль», яку ви надаєте моделі AI, може відігравати важливу роль у спонуканні її до менш сифофантичних та більш критичних помічників. Наприклад:
You are an experienced, sceptical and cautious data analyst. You are always conscious of the blind spots and mistakes made by data journalists when analysing data sets. Use code to perform analysis on the attached dataset which answers the following question, but also highlight any potential mistakes or blind spots to consider: - N-постріл, що спонукає: Це передбачає надання певної кількості (“n”) прикладів (“постріли”). Це можуть бути прикладами попередніх історій з використанням подібних даних, або це можуть бути прикладами методів, що використовуються раніше. Наприклад:
Below I've pasted some examples of angles drawn from this dataset in the past. Identify what calculations or code might have been used to arrive at those numbers [PASTE EXCERPTS FROM PREVIOUS STORIES]: - Рекурсивне спонукання: Це просто слідкує за відповідями. Як подальше спостереження за наданим аналізом, ви можете підказати:
Review the code you used to arrive at that answer. Identify any potential blind spots or problems, and list three alternative ways to answer the question. - Негативне спонукання: Спробуйте це:
Do not make any assumptions about the question that have not been explicitly stated, and do not proceed until you have clarified any ambiguity or assumptions embedded in the question. - Структурований вихідний вихід передбачає просити його забезпечити його вихід у певному форматі даних:
Provide the code used as a downloadable .py file. Provide the results in [CSV/JSON/Markdown table] format
Ланцюг думки та ганчірки заслуговують на особливу увагу …
Відобразити метод за допомогою Ланцюг думки (Ліжечко)
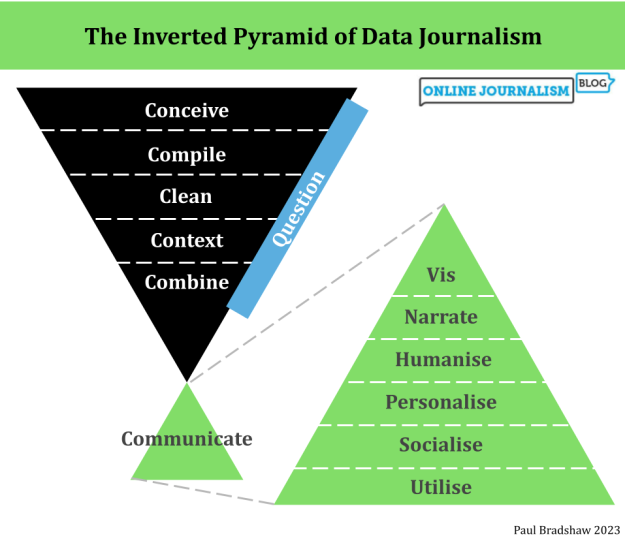
Ланцюг думки (ліжечко) Захисник передбачає встановлення низки кроків, які слід дотримуватися, та/або просити модель пояснити кроки, які потрібно було досягти. Це може бути дуже корисним для аналізу, оскільки значним фактором точності будь -якого аналізу є метод, який використовується.
Ось приклад оперативного використання COT для зменшення ризиків, що беруть участь у аналізі даних:
First, identify any aspects of the question which are ambiguous, or could be better expressed, and seek clarification on those. Once the question is clear enough, identify which columns are relevant to the question. Then outline three potential strategies for answering the question through code. Review the strategies and pick the one which is most rigorous, provides the most context, and is least likely to contain blind spots or errors. Explain your thinking.
Перевага COT полягає в тому, що вона підштовхує вас до думки про те, які кроки важливі в процесі аналізу, оскільки COT означає, що ви повинні донести ці кроки.
У випадку аналізу даних ми можемо визначити, що першим кроком є саме питання, але ми можемо повернутися ще далі до вибору чи розуміння використання набору даних.
З Перевернута піраміда журналістики даних Тут надає корисну рамку, оскільки це робить саме це: викладіть кроки, які часто включає проект журналістики даних. Важливим для висвітлення тут є те, що етап “питання” проходить у всіх інших. Пост із оновленою моделлю детальніше окреслює ці питання, і вони можуть бути включені в підказку.
Насправді ви можете включити цю публікацію або витягувати з нього, як додатковий контекст до вашого оперативного підказки – техніка, що називається Ганчірка…
“Зазвичай” аналіз з іншими документами (ганчірка)
Пошук розширеного покоління (RAG) – один з найпотужніших способів покращення відповідей моделей AI. Він передбачає “збільшення” вашої підказки з корисною або важливою інформацією, як правило, у вигляді витягів або вкладень.
Прикріплення самого набору даних – це форма ганчірки – але ви також можете приєднати інший матеріал, який вкладає набір даних у контекст. Приклади включають:
Ось приклад реакції шаблону, який може використовувати ганчірку. Однією з переваг такого підказки шаблону є те, що він нагадує вам шукати необхідні документи:
As well as the data itself I have attached a document explaining what each column means, and a methodology. Below is an extract on the different questions that need to be asked at every stage of the data analysis process.
Check assumptions built in to the question and challenge them, and add context that is relevant to the questions being asked. Here is the extract: [PASTE EXTRACT AND ATTACH DOCUMENTS]
Ще одне застосування ганчірки полягає в тому, щоб протиставити набір даних із претензіями щодо цього. Наприклад:
You are a sceptical data journalist that works for a factchecking organisation. You are used to powerful people misrepresenting data, putting a positive spin on it, or cherry-picking one facet of the data while ignoring less positive facets. You are checking the attached public statement made by a powerful person about a dataset. Compare this statement to the data and identify any claims that do not appear to be supported by the data, or any evidence of cherry picking. Identify any aspects of the data or other documents attached that are not mentioned in the statement but which might be newsworthy because they highlight potential problems, low-ranking performers, change, missing data, or outliers.
Обмеження повідомлень та обмеження розмови можуть перервати аналіз
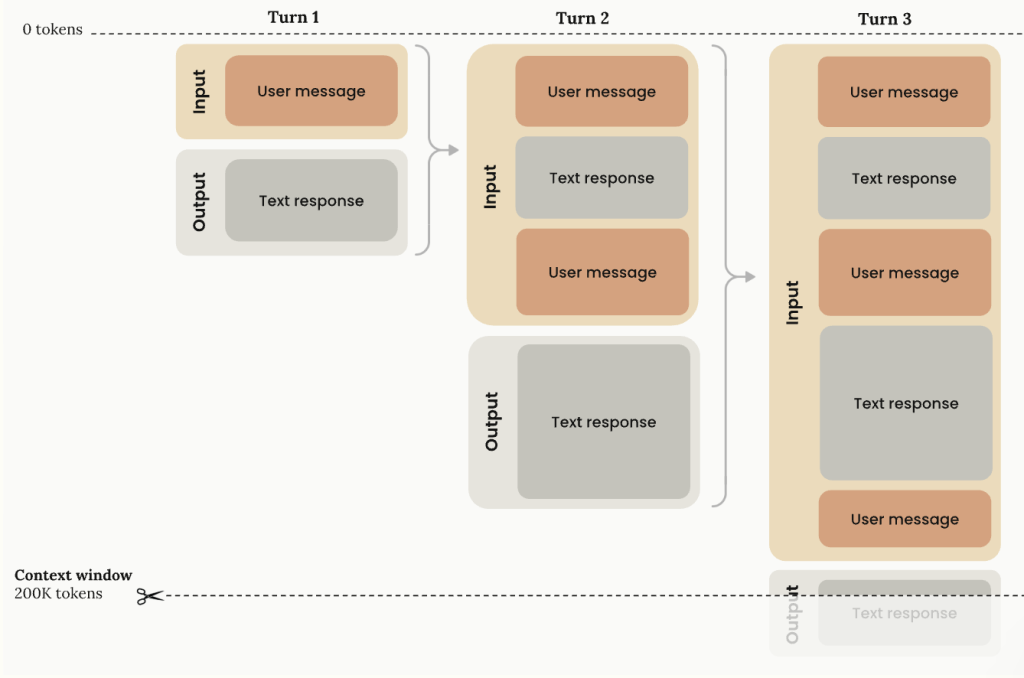
Пам'ятайте, що інструменти Genai мають обмеження щодо кількості пам'яті – “Контекстне вікно' – Вони можуть проводитись у розмові, і в якийсь момент вам, можливо, доведеться розпочати нову розмову, щоб продовжити аналіз.
У моєму тестуванні Клод, зокрема, прагнув досягти цих меж раніше, оскільки він також, як правило, використовував розширене мислення та надавши більш детальні відповіді на підказки, враховуючи аспекти, які не згадувались у цьому питанні.
Є кілька стратегій, які слід врахувати, якщо ви досягаєте цих меж:
- Зменшити тривалість відповідей через негативне спонукання. Наприклад, ви можете сказати «
in more than 300 words“Або”do not do any more than is asked“ - Попросіть його підсумувати розмову чи код досі (і вставте його на початку будь -якої нової розмови). Копіювання підсумків дозволить вам «експортувати» якусь пам’ять з однієї розмови в іншу. Вам потрібно буде зробити це, перш ніж досягти будь -яких обмежень, тому встановіть рутину зробити це після певної кількості взаємодій (наприклад, після кожної п’яти підказок у Клоді, або десять у Чатгпті, залежно від складності підказок та відповідей).
- Плануйте заздалегідь і розбийте аналіз на різні частини. Замість того, щоб намагатися завершити аналіз в одній розмові, розбийте його на різні завдання та використовуйте різну розмову для кожного. Це може створити більше природних точок розриву та зменшити потребу в експорті відповідей між розмовами.
Ви можете Попросіть оцінку жетонів, які використовувались досі, але в своєму тестуванні я виявив, що переробляв той самий запит у тому ж моменті в розмові, що породжував дуже різні результати, і жоден з них не близький до реальності.
Завжди експортуйте версію, щоб перевірити
Оскільки завжди корисно бачити дані в контексті, попросіть завантажити результати аналізу даних. Якщо це стосувалося, наприклад, сортування, попросіть його завантажувати CSV від сортованих даних, щоб ви могли їх побачити повністю. Якщо було залучено очищення або фільтрування, завантажена версія дозволить вам порівняти її з оригіналом.
Попросіть це кинути вам виклик
Кінцева порада – загартувати зміщення Sycophancy AI за допомогою змагальний спонукання Визначити потенційні сліпі плями або припущення у вашому підході до аналізу. Наприклад:
Act as a sceptical editor and ask critical questions about the prompts and methods used throughout this interaction. Identify potential blind spots, assumptions, potential ambiguity, or other problems with the approach, and other criticisms that might be made.
Ви використовували AI для аналізу даних та маєте поради? Опублікуйте їх у коментарях нижче або прокоментуйте LinkedIn.
*Моделі, що використовуються в тестах, були такими: Chatgpt GPT-4O, Claude Sonnet 4, Gemini 2.5 Flash, Copilot GPT-4-Turbo.